Generic SQL コネクタに関するテクニカル リファレンス
この記事では Generic SQL コネクタについて説明します。 この記事は次の製品に適用されます。
- Microsoft Identity Manager 2016 (MIM2016)
- Microsoft Entra ID
MIM2016の場合、コネクタは Microsoft ダウンロード センターからダウンロードできます。
このコネクタの動作を確認するには、「 Generic SQL Connector step-by-step (Generic SQL コネクタのステップ バイ ステップ) 」の記事を参照してください。
注意
Microsoft Entra IDでは、MIM 同期のデプロイを必要とせずに、SQL データベースにユーザーをプロビジョニングするための軽量のエージェント ベースのソリューションが提供されるようになりました。 送信ユーザー プロビジョニングに使用することをお勧めします。 詳細については、こちらを参照してください。
Generic SQL コネクタの概要
Generic SQL コネクタを使用すると、ODBC 接続を提供するデータベース システムに同期サービスを統合することができます。
包括的な観点から見た場合、コネクタの現在のリリースでサポートされている機能は次のとおりです。
| 機能 | サポート |
|---|---|
| 接続先のデータ ソース | コネクタは、すべての 64 ビット ODBC ドライバー* でサポートされています。 次のデータ ソースでテスト済みです。 |
| シナリオ | |
| Operations | |
| スキーマ |
前提条件
コネクタを使用する前に、次のものが同期サーバーにインストールされていることを確認してください。
- Microsoft .NET 4.6.2 Framework 以降
- 64 ビット ODBC クライアント ドライバー
- コネクタを使用して Oracle 12c と通信する場合は、ODBC パッケージを使用した Oracle Instant Client 12.2.0.1 以降が必要です。
- コネクタを使用して Oracle 18c-23c と通信する場合は、Oracle Instant Client 18-23 以降と ODBC パッケージを使用し、NLS_LANG システム変数を UTF8 文字 (NLS_LANG=AMERICAN_AMERICA など) をサポートするように設定する必要があります。AL32UTF8。
- このコネクタでは、SQL で準備されたステートメントと、トランザクションごとに複数のステートメントが使用されます。 一部の RDBM システムでは、トランザクション処理、サーバー側で準備された SQL ステートメント、および同じトランザクション内の複数のステートメントに関連する ODBC ドライバーに問題がある場合があります。 これらのステートメントがデータベースに正しく送信されるように DSN 接続オプションを構成してください。たとえば、MySQL ODBC Driver バージョン 8.0.32 には、オプション NO_SSPS=1 と MULTI_STATEMENTS=1 が必要です。 "autocommit" や "成功した操作に対してのみコミットする" などのその他のオプションは、バッチ エクスポートの処理方法に影響する可能性があります。詳細については、データベース管理者に問い合わせてください。 エクスポート中の問題をトラブルシューティングするには、エクスポート バッチ サイズを 1 に設定し、コネクタの詳細ログを有効にします。
このコネクタをデプロイするには、データベースの構成の変更と MIM の構成の変更が必要になる場合があります。 MIM と運用環境のサード パーティ製データベース サーバーの統合に関連するデプロイの場合は、お客様がデータベース ベンダー、またはこの統合に関するヘルプ、ガイダンス、サポートのために展開パートナーと協力することをお勧めします。
接続先データ ソースでのアクセス許可
Generic SQL コネクタでサポートされているタスクのどれかを作成または実行するには、次のものが必要です。
- db_datareader
- db_datawriter
ポートとプロトコル
ODBC ドライバーが動作するために必要なポートについては、データベース ベンダーのドキュメントを参照してください。
新しいコネクタの作成
Generic SQL コネクタを作成するには、[同期サービス] で [管理エージェント] を選択し、[作成] を選択します。 Generic SQL (Microsoft) コネクタを選択します。
接続
コネクタでは、接続のために ODBC DSN ファイルを使用します。 [管理ツール] の [スタート] メニューで見つかった [ODBC データ ソース] を使用して DSN ファイルを作成します。 管理ツールで、 ファイル DSN を作成してコネクタに提供できるようにします。

新しい Generic SQL コネクタを作成すると、[接続] 画面が最初に表示されます。 まず次の情報を指定する必要があります。
- DSN ファイル パス
- 認証
- [ユーザー名]
- パスワード
データベースは、次の認証方法のいずれかをサポートしている必要があります。
- Windows 認証: 認証データベースは、Windows 資格情報を使用してユーザーを検証します。 指定されたユーザー名/パスワードは、データベースとの認証に使用されます。 このアカウントには、データベースへのアクセス許可が必要です。
- SQL 認証: 認証データベースでは、[接続] 画面で定義されたユーザー名/パスワードを使用してデータベースに接続します。 DSN ファイルにユーザー名/パスワードを格納する場合、[接続] 画面で指定する資格情報には優先順位があります。
- Azure SQL データベース認証: 詳細については、「Microsoft Entra認証を使用してSQL Databaseに接続する」を参照してください。
DN はアンカー: このオプションを選択した場合、DN はまた、アンカー属性として使用されます。 これは、単純な実装に使用できるものの、次の制限事項があります。
- コネクタはオブジェクトの種類を 1 つのみサポートします。 したがって、参照属性は、同じオブジェクトの種類しか参照できません。
エクスポートの種類: オブジェクトの置換: エクスポート中には、一部の属性しか変更されていなくても、オブジェクト全体がすべての属性を伴ってエクスポートされ、既存のオブジェクトに置き換わります。
スキーマ 1 (オブジェクトの種類の検出)
このページでは、データベース内のさまざまなオブジェクトの種類をコネクタで検索する方法を構成します。
オブジェクトの種類はすべてパーティションとして表示され、 [Configure Partitions and Hierarchies (パーティションの構成と階層)]でさらに構成できます。
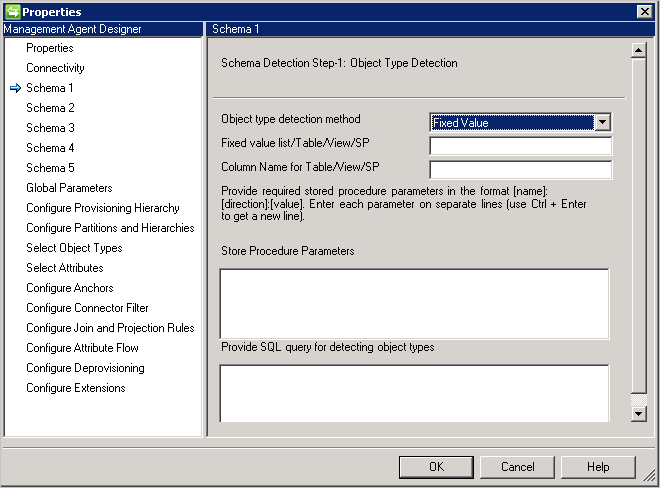
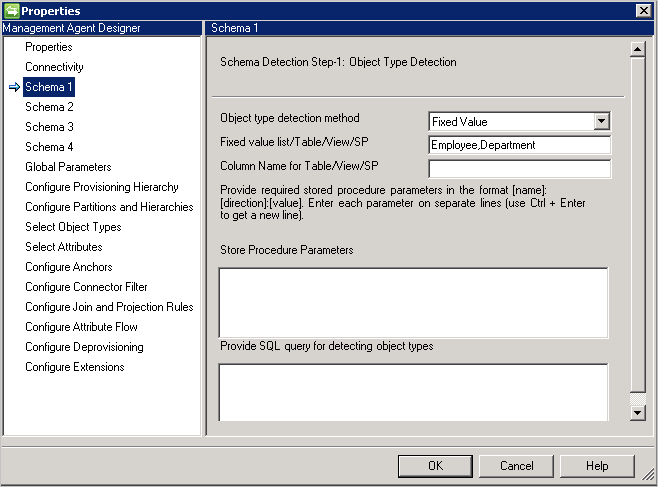
オブジェクトの種類の検出方法: コネクタでは、次に示すオブジェクトの種類の検出方法をサポートしています。
- 固定値: コンマ区切りの形式でオブジェクトの種類のリストを指定します。 (例:
User,Group,Department)。
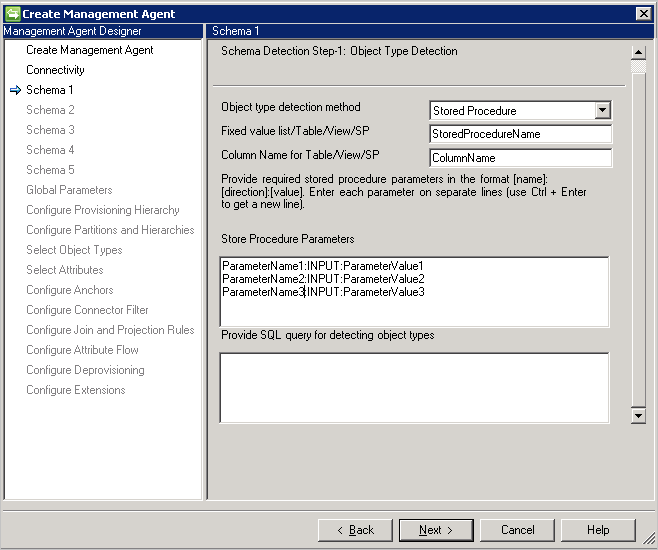
- テーブル/ビュー/ストアド プロシージャ: テーブル/ビュー/ストアド プロシージャの名前を指定し、次にオブジェクトの種類の一覧を指定する列名を指定します。 ストアド プロシージャを使用する場合はさらに、そのパラメーターを [Name]:[Direction]:[Value]の形式で指定します。 各パラメーターを個別の行に指定します (新しい行を取得するには、Ctrl + Enter キーを使用します)。
- SQL クエリ: このオプションでは、オブジェクトの種類を含んでいる 1 つの列を返す SQL クエリを指定できます (例:
SELECT [Column Name] FROM TABLENAME)。 返される列は、文字列型 (varchar) でなければなりません。
スキーマ 2 (属性の型を検出する)
このページでは、属性の名前と型を検出する方法を構成します。 前のページで検出されたすべてのオブジェクトについて構成オプションが一覧表示されます。
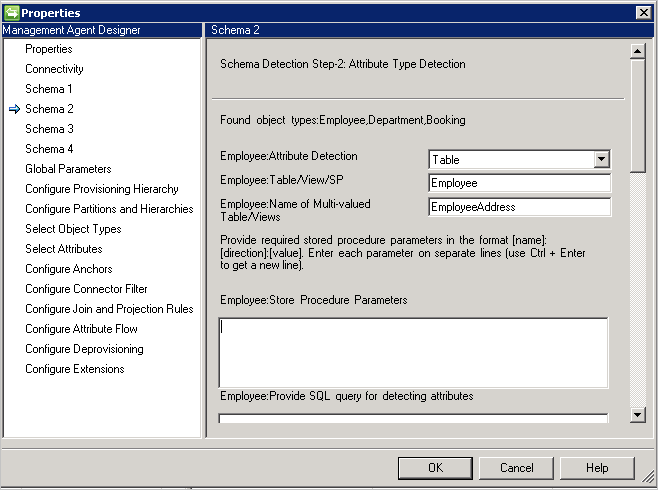
属性の型の検出方法: コネクタでは、[スキーマの 1] 画面で検出されたすべてのオブジェクトで属性の型を検出する以下の方法をサポートしています。
- テーブル/ビュー/ストアド プロシージャ: 属性の名前を検索する場合に使用する必要があるテーブル/ビュー/ストアド プロシージャの名前を指定します。 ストアド プロシージャを使用する場合はさらに、そのパラメーターを [Name]:[Direction]:[Value]の形式で指定します。 各パラメーターを個別の行に指定します (新しい行を取得するには、Ctrl + Enter キーを使用します)。 複数値の属性内で属性名を検出するには、テーブルまたはビューのコンマ区切りのリストを指定します。 親テーブルと子テーブルの列名が同じである場合、複数値のシナリオはサポートされません。
- SQL クエリ: このオプションでは、属性名を含んでいる 1 つの列を返す SQL クエリを指定できます (例:
SELECT [Column Name] FROM TABLENAME)。 返される列は、文字列型 (varchar) でなければなりません。
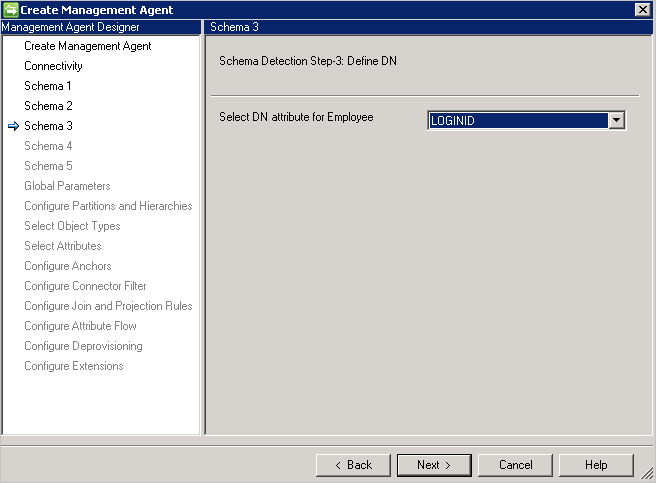
スキーマ 3 (アンカーと DN を定義する)
このページでは、検出されたオブジェクトの種類ごとにアンカーと DN 属性を構成することができます。 複数の属性を選択することでアンカーを一意にできます。

複数値の属性とブール型の属性は表示されません。
[接続] ページで [DN はアンカー] が選択されていない限り、DN とアンカーに対して同じ属性を使用することはできません。
[接続] ページで [DN はアンカー] が選択されている場合、このページでは DN 属性のみが必要です。 DN 属性は、アンカー属性としても使用されます。
スキーマ4 (属性の型、参照、および方向を定義する)
このページでは、属性の型 (整数、バイナリ、ブール値など) と方向を属性ごとに構成することができます。 [スキーマ 2] ページからの属性がすべて (複数値の属性も含む)、一覧表示されます。
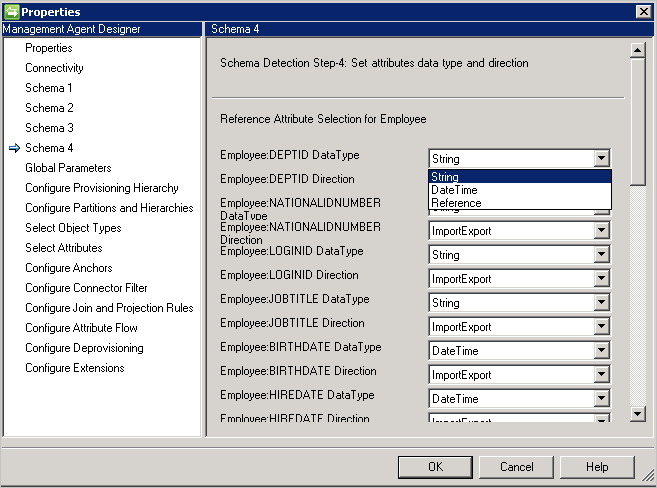
- DataType: 属性の型を、同期エンジンで認識されている種類にマップするために使用します。 既定では SQL スキーマで検出された型と同じ型を使用しますが、DateTime 型と参照型は簡単に検出されません。 そのような場合は、DateTime または参照を指定する必要があります。
- 方向: 属性の方向は Import、Export、または ImportExport に設定することができます。 ImportExport が既定値です。
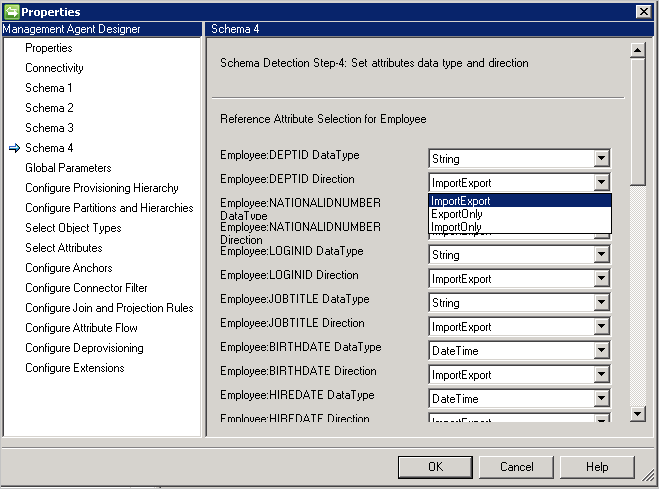
メモ:
- 属性の型がコネクタで検出不可能な型である場合、コネクタは文字列データ型を使用します。
- 入れ子になったテーブル は、1 列のデータベース テーブルと見なすことができます。 Oracle では、入れ子になったテーブルの行を任意の順序で格納します。 ただし、入れ子になったテーブルを取得して PL/SQL 変数に入れる場合、行には 1 から始まる連続した添字が与えられます。 これにより個々の行への配列様式のアクセスが可能になります。
- VARRYS はコネクタでサポートされていません。
スキーマ 5 (参照属性のパーティションを定義する)
このページでは、すべての参照属性について、属性が参照するパーティション (オブジェクトの種類) を構成します。
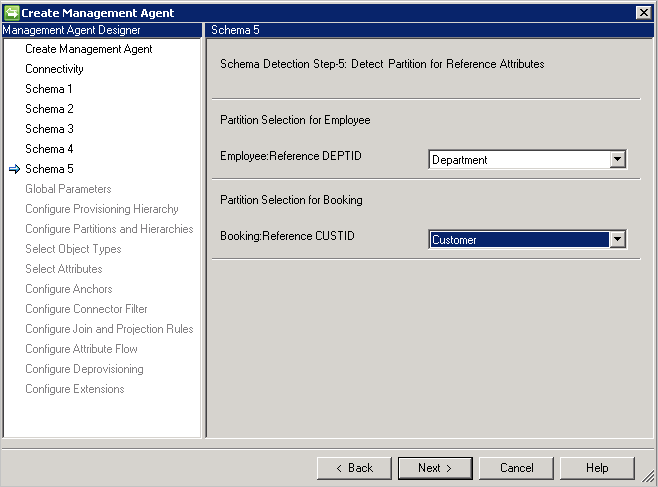
[DN is anchor (DN はアンカー)]を使用している場合、参照元のオブジェクトの種類と同じ種類を使用する必要があります。 別のオブジェクトの種類を参照することはできません。
注意
2017 年 3 月の更新以降、[*] オプションを使用できるようになりました。このオプションを選択すると、すべての可能なメンバーの種類がインポートされます。
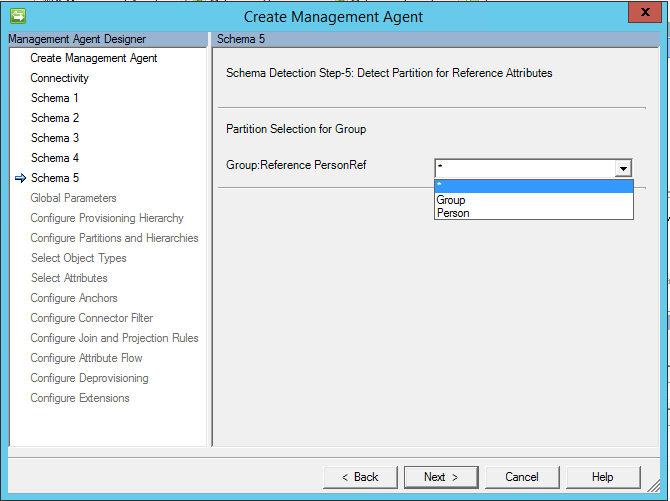
重要
2017 年 5 月の時点で、インポートとエクスポートのフローをサポートするために、 任意のオプション として "*" が変更されました。 このオプションを使用する場合、複数値のテーブル/ビューに、オブジェクトの種類を含む属性を追加する必要があります。

"*" が選択されている場合は、オブジェクト型を持つ列の名前も指定する必要があります。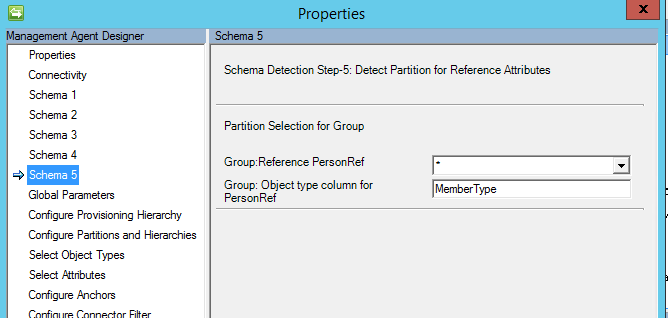
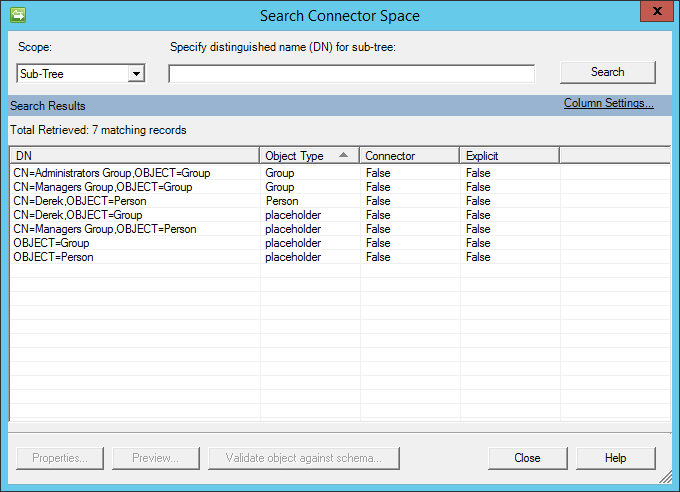
インポートが完了すると、次の図のような情報が表示されます。
グローバル パラメーター
[グローバル パラメーター] ページでは、差分インポート、日付/時刻形式、およびパスワード方法を構成します。
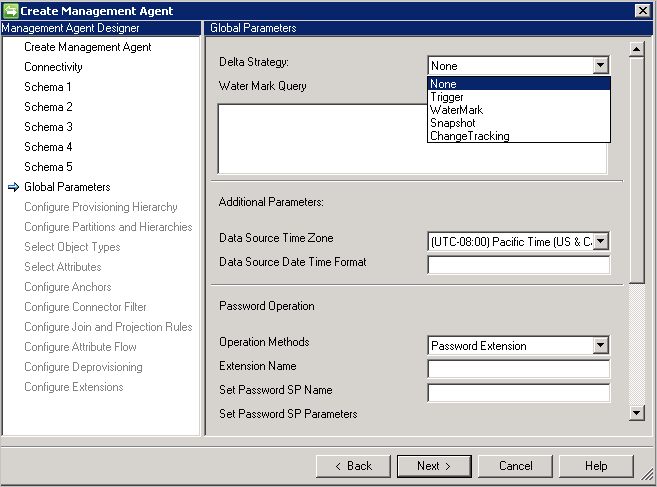
Generic SQL コネクタでは、差分インポートの次の方法をサポートしています。
- トリガー: 「 トリガーを使用した差分ビューの生成」を参照してください。
- 透かし: これは、任意のデータベースで使用できる一般的な手法です。 データベース ベンダーに基づいて透かしクエリがあらかじめ設定されています。 使用するすべてのテーブル/ビューに、透かし列が存在する必要があります。 この列では、テーブルとその依存 (複数値または子) テーブルへの挿入と更新を追跡する必要があります。 同期サービスとデータベース サーバーとの間で時間を同期させる必要があります。 そうしないと、差分インポートの一部のエントリが省略される場合があります。
制限事項:- 透かし手法では、削除されたオブジェクトはサポートされていません。
- スナップショット: (Microsoft SQL Server でのみ動作)。「Generating Delta Views Using Snapshots (スナップショットを使用した差分ビューの生成)」を参照してください
- 変更の追跡: (Microsoft SQL Server でのみ動作)。「変更の追跡について」を参照してください
制限事項:- アンカー & DN 属性は、テーブル内の選択されたオブジェクトのプライマリ キーの一部を成している必要があります。
- [変更の追跡] を使用したインポートおよびエクスポート中に、SQL クエリはサポートされていません。
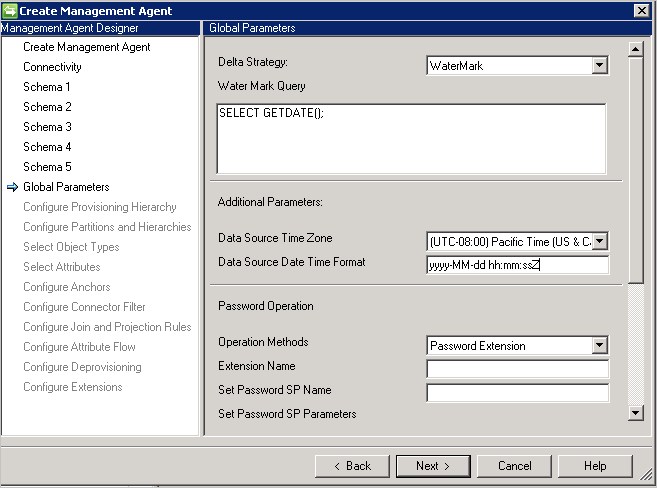
追加パラメーター: データベース サーバーが置かれている場所を示すデータベース サーバーのタイム ゾーンを指定します。 この値は、日付属性と時刻属性のさまざまな形式をサポートするために使用されます。
コネクタでは常に、日付と時刻が UTC 形式で格納されます。 日付と時刻を正しく変換できるようにするには、データベース サーバーのタイム ゾーンと、使用する形式を指定する必要があります。 形式は .NET 形式で表す必要があります。
エクスポート時には、日時の属性のすべてを UTC 時刻形式でコネクタに指定する必要があります。
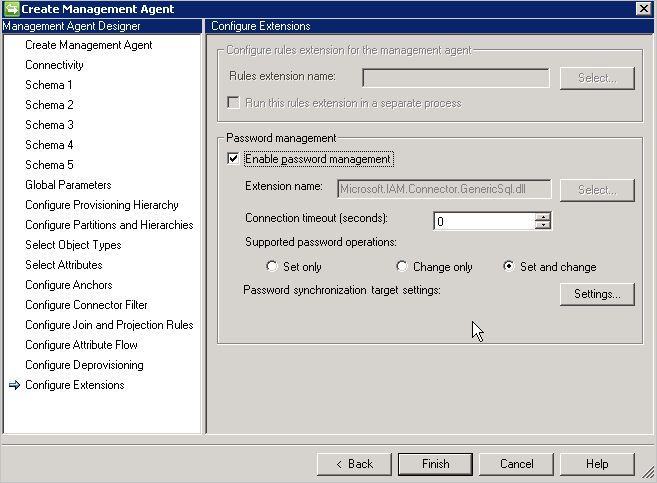
パスワード構成: コネクタは、パスワード同期機能を備え、パスワードの設定および変更をサポートしています。
このコネクタでは、2 つの方法でパスワード同期をサポートしています。
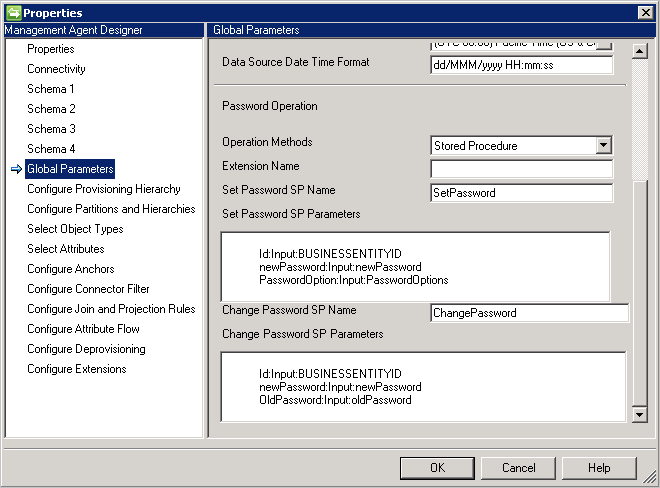
- ストアド プロシージャ: この方法では、パスワードの設定と変更に対応するために 2 つのストアド プロシージャが必要です。 次の例に示すように、[Set Password SP Parameters (パスワード SP パラメーターの設定)] と [Change Password SP Parameters (パスワード SP パラメーターの変更)] に、パスワードの追加操作とパスワードの変更操作に必要なすべてのパラメーターを入力します。
- パスワード拡張: この方法ではパスワード拡張 DLL が必要です ( IMAExtensible2Password インターフェイスを実装する拡張 DLL 名を指定する必要があります)。 コネクタが実行時に DLL を読み込むことができるように、拡張フォルダーにパスワード拡張アセンブリを配置する必要があります。
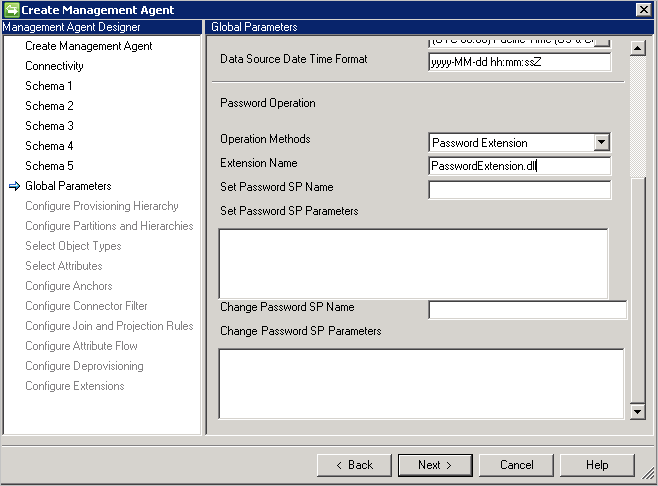
また、 [拡張の構成] ページでパスワードの管理を有効にする必要があります。
パーティションと階層を構成する
パーティションと階層のページでは、すべてのオブジェクトの種類を選択します。 各オブジェクトの種類はそれぞれの独自のパーティションです。
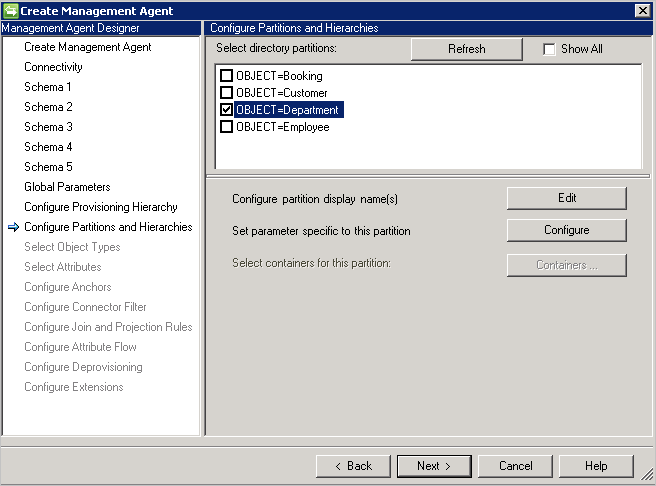
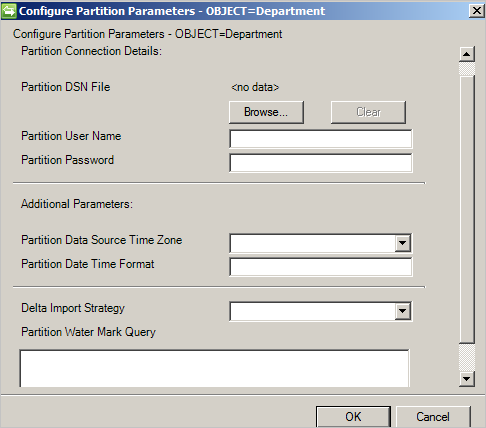
[接続] ページまたは [グローバル パラメーター] ページで定義されている値をオーバーライドすることもできます。
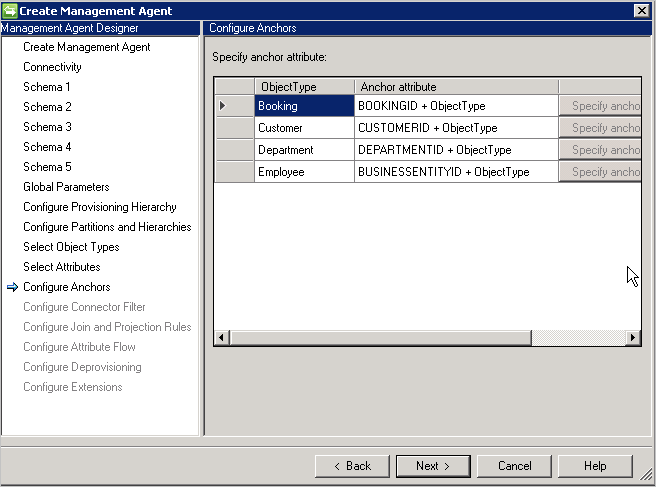
アンカーを構成する
アンカーは既に定義されているので、このページは読み取り専用です。 選択したアンカー属性は常にオブジェクトの種類に付加され、それがオブジェクトの種類全体の中で確実に一意のままであるようにします。
実行ステップ パラメーターの構成
次の手順は、コネクタの実行プロファイルで構成します。 これらの構成によって、データのインポートとエクスポートの実際の作業が実行されます。
フル インポートと差分インポート
Generic SQL コネクタでは、次の方法を使用したフル インポートと差分インポートをサポートしています。
- テーブル
- 表示
- ストアド プロシージャ
- SQL クエリ
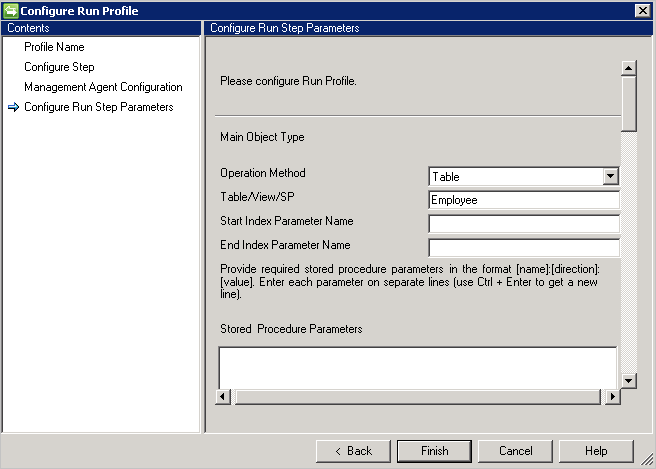
テーブル/ビュー
オブジェクトの複数値の属性をインポートするには、[複数値のテーブル/ビューの名前] にテーブル/ビュー名を指定し、[結合条件] に親テーブルとのそれぞれの結合条件を指定します。 データ ソースに複数の値を持つテーブルがある場合は、共用体を 1 つのビューに使用できます。
重要
Generic SQL 管理エージェントは、1 つの複数値テーブルでのみ動作します。 [複数値のテーブル/ビューの名前] には、複数のテーブル名を入力しないでください。 これは Generic SQL の制限です。
例: Employee オブジェクトとそのすべての複数値属性をインポートします。 Employee という名前のテーブル (メイン テーブル) と Department という名前のテーブル (複数値テーブル) があります。 次の操作を行います。
- [テーブル/ビュー/SP] に「Employee」と入力します。
- [複数値のテーブル/ビューの名前]に「Department」と入力します。
- [結合条件] に Employee と Department の結合条件を入力します。たとえば、
Employee.DEPTID=Department.DepartmentIDのようになります。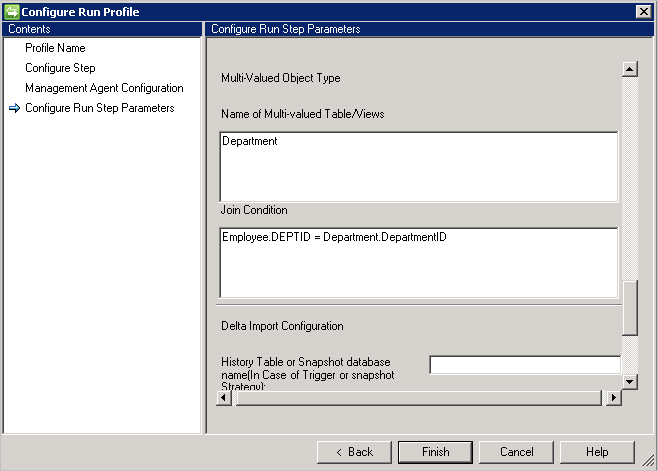
ストアド プロシージャ
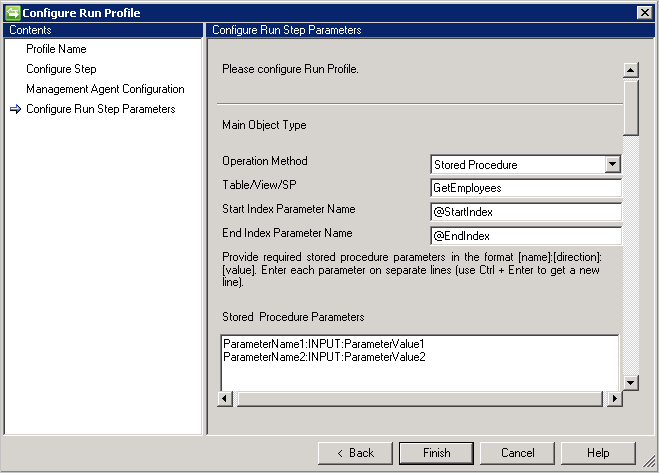
- データの量が多い場合は、ストアド プロシージャを使用して、改ページ調整を実装することをお勧めします。
- ストアド プロシージャで改ページ調整をサポートするには、開始インデックスと終了インデックスを指定する必要があります。 「 Efficiently Paging Through Large Amounts of Data (大量データの効率的なページング)」を参照してください。
- @StartIndex と @EndIndex は実行時に、[Configure Step (手順の構成)] ページで構成したそれぞれのページ サイズ値に置き換えられます。 たとえば、コネクタが取得した最初のページのサイズが 500 に設定されているとします。このような場合、@StartIndex は 1、@EndIndex は 500 になります。 これらの値は、コネクタが後続のページを取得するに従って大きくなり、@StartIndex 値と @EndIndex 値が変更されます。
- パラメーター化されたストアド プロシージャを実行するには、
[Name]:[Direction]:[Value]形式でパラメーターを指定します。 各パラメーターを個別の行に入力します (新しい行を取得するには、Ctrl + Enter キーを使用します)。 - Generic SQL コネクタでは、Microsoft SQL Server 内のリンク サーバーからのインポート操作もサポートされています。 リンク サーバー内のテーブルから情報が取得される場合、テーブルは次の形式で提供されます。
[ServerName].[Database].[Schema].[TableName] - Generic SQL コネクタでは、実行手順の情報とスキーマ検出との間で構造 (エイリアス名とデータ型の両方) が類似しているオブジェクトのみがサポートされます。 スキーマで選択したオブジェクトと、実行手順で指定した情報が異なる場合、このタイプのシナリオは SQL コネクタでサポートされません。
SQL クエリ
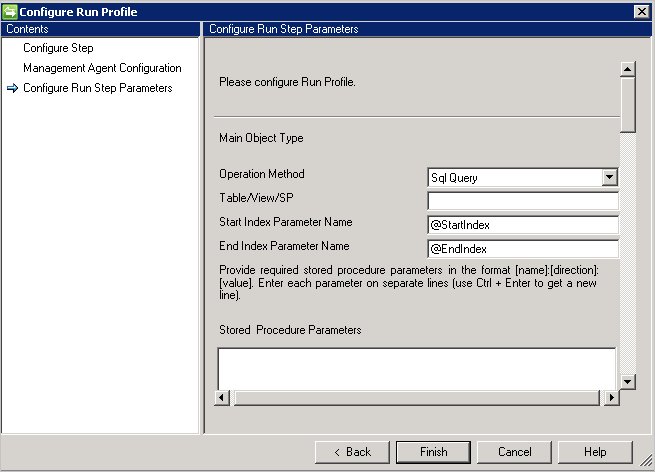
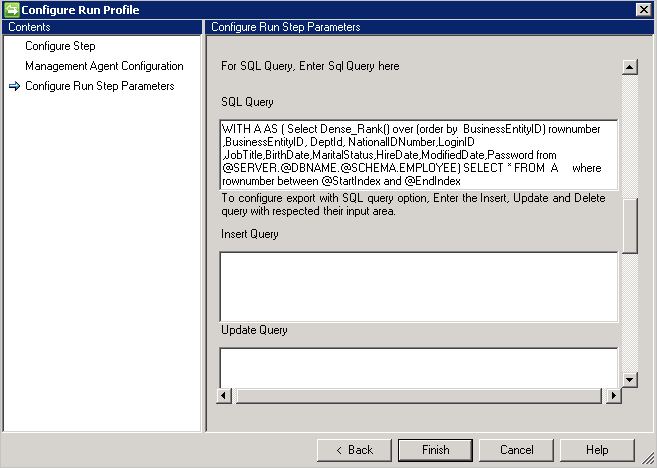
重要
CRLF または改行文字は、複数のステートメント間の区切り記号として機能します。
改ページを使用したサンプル SQL クエリ - 正しくないクエリは、新しい行文字が使用されるため機能しません。
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
ページ分割を使用したサンプル SQL クエリ - 正しいクエリ:
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- 複数の結果セット クエリはサポートされていません。
- SQL クエリは改ページをサポートし、改ページをサポートする変数として Start Index と End Index を指定します。
差分インポート
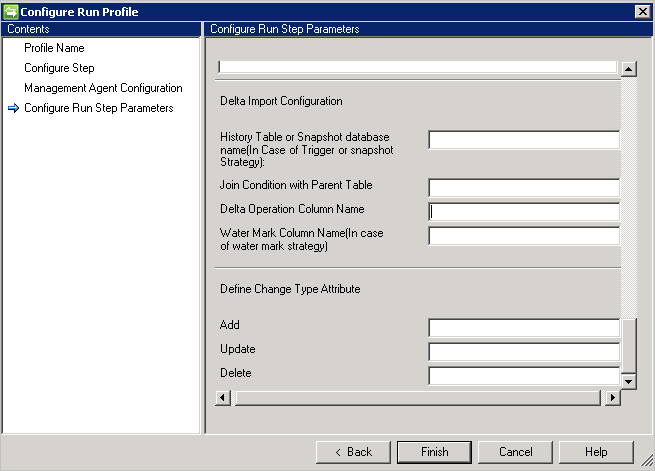
差分インポートの構成には、フル インポートと比較して追加の構成が必要です。
- 方法としてトリガーまたはスナップショットを選択して差分変更を追跡する場合、 [History Table or Snapshot database name (履歴テーブルまたはスナップショットのデータベース名)] ボックスで履歴テーブルまたはスナップショットのデータベースを指定します。
- また、履歴テーブルと親テーブルとの間の結合条件を指定する必要があります (たとえば、
Employee.ID=History.EmployeeID - 履歴テーブルから親テーブルに対するトランザクションを追跡するには、操作情報 (追加/更新/削除) が含まれている列名を指定する必要があります。
- 透かしで差分変更を追跡する場合、操作情報が含まれている列名を [Water Mark Column Name (透かし列名)]に指定する必要があります。
- 変更の種類については、 変更の種類の属性 列が必要です。 この列により、プライマリ テーブルまたは複数値のテーブル内で発生した変更が、差分ビュー内の変更の種類にマップされます。 この列には、属性レベルの変更に対しては Modify_Attribute という変更の種類を含め、オブジェクト レベルの変更に対しては Add、Modify、または Delete という変更の種類を含めることができます。 変更の種類が既定値の Add、Modify、または Delete 以外の種類である場合、このオプションを使用してそれらの値を定義できます。
エクスポート
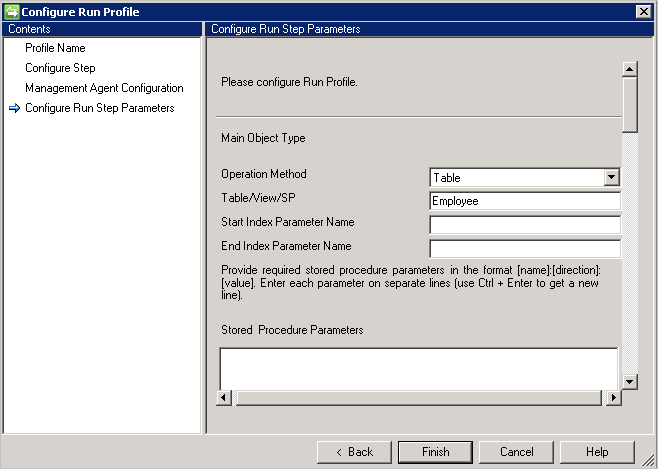
Generic SQL コネクタでは、次に示す 4 つのサポートされた方法を使用したエクスポートをサポートしています。
- テーブル
- 表示
- ストアド プロシージャ
- SQL クエリ
テーブル/ビュー
[テーブル/ビュー] オプションを選択した場合、コネクタによって各クエリが生成され、エクスポートが実行されます。
ストアド プロシージャ
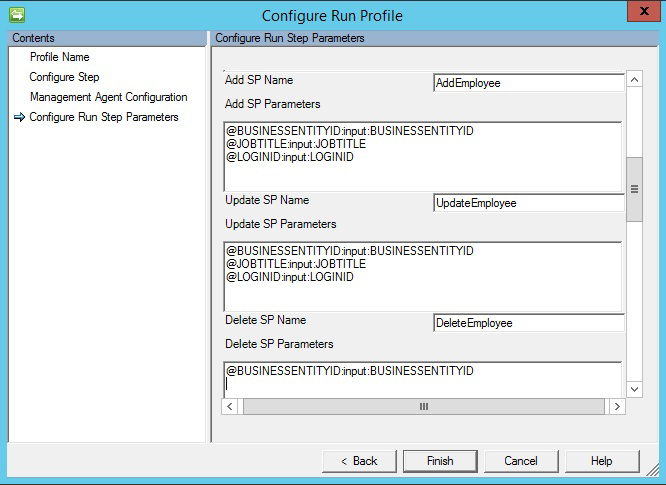
[ストアド プロシージャ] オプションを選択した場合、エクスポートには、挿入/更新/削除の操作を実行する 3 種類のストアド プロシージャが必要です。
- [Add SP Name (SP 名の追加)]: この SP は、それぞれのテーブルで挿入を行うために任意のオブジェクトがコネクタに渡された場合に実行されます。
- [Update SP Name (SP 名の更新)]: この SP は、それぞれのテーブルで更新を行うために任意のオブジェクトがコネクタに渡された場合に実行されます。
- [Delete SP Name (SP 名の削除)]: この SP は、それぞれのテーブルで削除を行うために任意のオブジェクトがコネクタに渡された場合に実行されます。
- ストアド プロシージャへのパラメーター値として使用されるスキーマから選択した属性です。 たとえば、
@EmployeeName: INPUT: EmployeeName(コネクタのスキーマで EmployeeName が選択されると、コネクタはエクスポートの実行中にそれぞれの値を置換します) です。 - パラメーター化されたストアド プロシージャを実行するには、
[Name]:[Direction]:[Value]形式でパラメーターを指定します。 各パラメーターを個別の行に入力します (新しい行を取得するには、Ctrl + Enter キーを使用します)。
SQL query
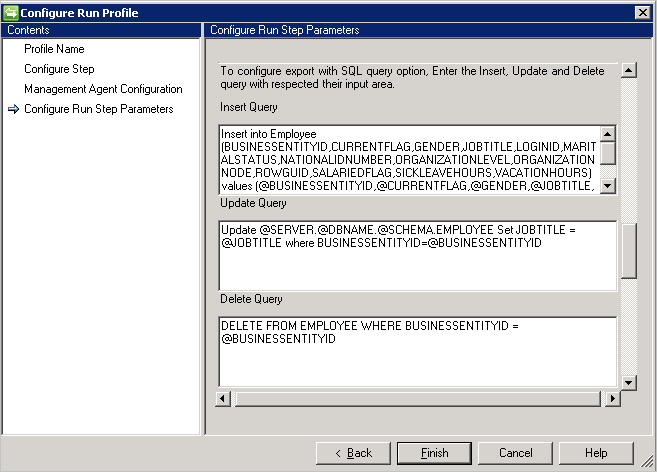
[SQL クエリ] オプションを選択した場合、エクスポートには、挿入/更新/削除の操作を実行する 3 種類のクエリが必要です。
- [挿入クエリ]: このクエリは、それぞれのテーブルで挿入を行うためにコネクタに任意のオブジェクトが渡された場合に実行されます。
- [更新クエリ]: このクエリは、それぞれのテーブルで更新を行うためにコネクタに任意のオブジェクトが渡された場合に実行されます。
- [削除クエリ]: このクエリは、それぞれのテーブルで削除を行うためにコネクタに任意のオブジェクトが渡された場合に実行されます。
- クエリへのパラメーター値として使用されるスキーマから選択された属性です (たとえば
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
重要
CRLF または改行文字は、複数のステートメント間の区切り記号として機能します。
マルチステップ更新 SQL クエリのサンプル - 新しい行文字を使用して SQL ステートメントを分離します。
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
トラブルシューティング
- コネクタのトラブルシューティングを行うためにログ記録を有効にする方法については、「 How to Enable ETW Tracing for Connectors (コネクタの ETW トレースを有効にする方法)」を参照してください。