Power BI の高密度線サンプリング
Power BI のサンプリング アルゴリズムによって、高密度データをサンプリングするビジュアルが向上します。 たとえば、小売店の売上結果から折れ線グラフを作成するとします。各店舗の売上金は毎年 1 万を超えています。 このような売上情報の折れ線グラフで、各店舗のデータをサンプリングし、複数系列の折れ線グラフを作成し、基になるデータを表します。 時間の経過に伴う売上の変化を示すために、そのデータの有意な表現を選択してください。 これは、高密度データを視覚化する一般的な方法です。 高密度データ サンプリングの詳細は、この記事で説明しています。
Note
この記事で説明する高密度サンプリング アルゴリズムは、Power BI Desktop と Power BI サービスの両方に使用可能です。
高密度データ線サンプリングのしくみ
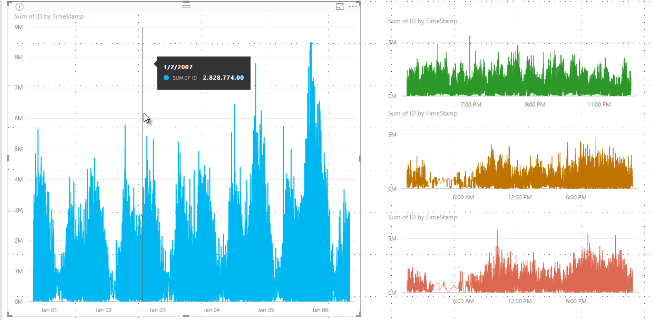
これまで、Power BI では、決定論的な方法で基になるデータ全体のサンプル データ ポイントのコレクションを選択していました。 たとえば、1 カレンダー年にわたるビジュアルの高密度データの場合、350 のサンプル データ ポイントがビジュアルで表示されます。各ポイントを選択すると、データ全体がビジュアルで表されます。 このしくみをわかりやすくするために、例として、1 年間の株価をプロットし、365 のデータ ポイントを選択して折れ線グラフのビジュアルを作成しています。 1 日ごとにデータ ポイントは 1 つです。
その場合、各日内の株価の値が多数存在します。 もちろん、日々の高値と安値はありますが、株式市場が開いている間、これらは随時変動する可能性があります。 高密度線サンプリングでは、基になるデータ サンプルが毎日午前 10 時 30 分と午後 12 時 00 分に取得された場合、基になるデータの代表的なスナップショット (午前 10 時 30 分と午後 12 時 00 分の価格) を取得します。 ただし、スナップショットでは、その日の代表的なデータ ポイントの株価の実際の高値と安値がキャプチャされない場合があります。 このような状況では、サンプリングは基になるデータの代表的なものとなりますが、必ずしも重要なポイントがキャプチャされるとは限りません。その場合、日々の株価の高値と安値が複数存在することになります。
定義上、高密度データは、対話機能に応答する視覚エフェクトを妥当な時間で作成するためにサンプリングされます。 ビジュアルのデータ ポイントが多すぎると繁雑になり、トレンドが見えにくくなる可能性があります。 データのサンプリング方法は、最適な視覚化エクスペリエンスを提供するサンプリング アルゴリズムの作成を促すものです。 Power BI Desktop では、アルゴリズムによって、各タイム スライスの重要なポイントの応答性、表記、および明確な保存の最適な組み合わせが提供されます。
新しい線サンプリング アルゴリズムのしくみ
高密度線サンプリングのアルゴリズムは、連続 x 軸を含む折れ線グラフと面グラフのビジュアルで使用可能です。
高密度のビジュアルの場合、Power BI はインテリジェントにデータを高解像度のチャンクにスライスしてから、重要なポイントを選んで各チャンクを表します。 高解像度データをスライスするこの処理は調整され、生成されるグラフが、基になるすべてのデータ ポイントをレンダリングする場合と視覚的には区別できないものの、より高速で対話的になるようにします。
高密度線の視覚エフェクトの最小値と最大値
どの視覚化でも、次の制限事項が適用されます。
基になるデータ ポイントまたは系列の数に関係なく、ほとんどの視覚エフェクトで "表示される" データ ポイントの最大数は 3,500 です。次の一覧の "例外" を参照してください。 たとえば、それぞれ 350 のデータ ポイントがある 10 系列の場合、ビジュアルはそのデータ ポイント全体の最大制限に達しています。 1 系列の場合、アルゴリズムで基になるデータの最適なサンプリングであると判断されると、最大 3,500 のデータ ポイントが含まれる可能性があります。
どのビジュアルにも、最大 60 の系列があります。 60 を超える系列がある場合は、データを分割し、それぞれ 60 以下の系列を含む複数のビジュアルを作成します。 スライサーを使用して、データのセグメントのみ (ただし、特定の系列のみ) が表示されるようにすることをお勧めします。 たとえば、凡例ですべてのサブカテゴリを表示する場合は、スライサーを使用して、同じレポート ページのカテゴリ全体でフィルター処理することができます。
データ制限の最大数は、次の種類の視覚エフェクトで高く、これは 3,500 のデータ ポイント制限の例外となります。
- R ビジュアルでは、最大 150,000 のデータ ポイント。
- Azure Map ビジュアルの 30,000 データ ポイント。
- 一部の散布図構成では 10,000 データ ポイント (散布図の既定値は 3500)。
- 高密度サンプリングを使用する他のすべてのビジュアルの場合は 3,500。 他の一部のビジュアルでは、より多くのデータを視覚化できる場合がありますが、サンプリングは使用されません。
これらのパラメーターを使用することで、Power BI Desktop のビジュアルで短時間にレンダリングできるようになり、ユーザーとの対話の応答性が高まります。また、ビジュアルをレンダリングするコンピューターでの計算オーバーヘッドが過度になることはありません。
高密度線のビジュアルで代表的なデータ ポイントを評価する
基になるデータ ポイントの数が、ビジュアルで表現できる最大データ ポイントを超えると、"ビン分割" と呼ばれるプロセスが開始します。 ビン分割すると、基になるデータが "ビン" と呼ばれるグループにチャンク化され、それらのビンが繰り返し調整されます。
アルゴリズムではできるだけ多くのビンを作成し、視覚エフェクトの細分度を最適なものにします。 各ビン内で、アルゴリズムは最小および最大データ値を検索し、ビジュアルで重要および重大な外れ値などの値がキャプチャされ、表示されることを確認します。 Power BI でのデータのビン分割と以降の評価の結果に基づいて、ビジュアルの x 軸の最小解像度が決まり、ビジュアルの最大細分性が確保されます。
前述のように、各系列の最小細分性は 350 ポイントで、最大はほとんどのビジュアルで 3,500 です。 "例外" は前の段落に記載されています。
各ビンは 2 つのデータ ポイントで表され、このデータ ポイントが視覚エフェクトのビンの代表的なデータ ポイントになります。 データ ポイントは、そのビンの高値と低値です。 高値と低値を選択することで、ビン分割プロセスによって、重要な高値、または重大な低値がビジュアルで確実にキャプチャされ、レンダリングされるようになります。
多くの分析で確実に不定期の外れ値がキャプチャされ、ビジュアルで適切に表示されるのが正しい動作です。 それがまさしく、アルゴリズムとビン分割プロセスの背後にある理由です。
ヒントと高密度線サンプリング
特定のビンの最小および最大の値がキャプチャされて表示される、このビン分割プロセスが、データ ポイントにマウス カーソルを合わせたときのヒントでのデータの表示方法に影響する可能性があることに注意してください。 この状態がどのように、また、なぜ発生するのかを説明するために、株価の例をここでも使用します。
たとえば、株価に基づいてビジュアルを作成し、2 つの異なる株を比較するとします。これらの両方で高密度サンプリングを使用します。 各系列の基になるデータには、多くのデータ ポイントがあります。 たとえば、1 日の 1 秒ごとに株価を取得する場合があります。 高密度線サンプリング アルゴリズムでは、各系列に対して個別にビン分割を実行します。
ここで、最初の株の価格が 12 時 02 分に急騰し、10 秒後にすぐに戻ったとします。 これは重要なデータ ポイントです。 その株でビン分割する場合、12 時 02 分の時点の高値がそのビンの代表的なデータ ポイントとなります。
しかし、2 番目の株には、12 時 02 分を含むビンの高値も安値もありませんでした。 12 時 02 分を含むビンの高値と安値は 3 分後に発生したかもしれません。 その場合、折れ線グラフが作成され、12 時 02 分にカーソルを合わせると、最初の株価のヒントに値が表示されます。 これは、12 時 02 分に急騰し、その値がそのビンの高いデータ ポイントとして選択されたためです。 ただし、2 番目の株の 12 時 02 分のヒントに値は表示されません。 これは、2 番目の株には、12 時 02 分を含むビンの高値と安値がなかったためです。 したがって、12 時 02 分の 2 番目の株について表示されるデータはないため、ヒントのデータは表示されません。
このような状態はヒントでは頻繁に発生します。 特定のビンの高値と安値は、均等にスケーリングされた x 軸値のポイントと完全には一致しないため、ヒントに値は表示されません。
高密度線サンプリングを有効にする方法
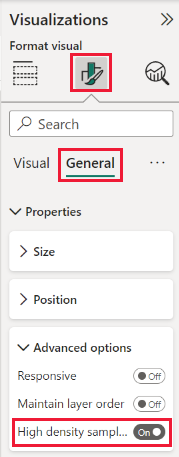
既定では、アルゴリズムは [オン] です。 この設定を変更するには、[書式設定] ペインに移動します。[全般] カードの下部には、[高密度サンプリング] スライダーがあります。 そのスライダーを選択して、[オン] または [オフ] を切り替えます。
考慮事項と制限事項
高密度線サンプリングのアルゴリズムは、Power BI の重要な拡張機能ですが、高密度の値とデータを処理する場合に知っておく必要がある考慮事項がいくつかあります。
細分性を高めたことで、またビン分割プロセスが原因で、ヒントで値を表示できるのは、代表データをカーソルで揃えた場合のみとなります。 詳細については、この記事の「ヒントと高密度線サンプリング」を参照してください。
データ ソース全体のサイズが大きすぎる場合、そのアルゴリズムは系列 (凡例の要素) を削除し、データ インポートの最大制約を適用します。
- このような場合、アルゴリズムは凡例の系列をアルファベット順に並べ替え、データ インポートの上限に達し、追加の系列がインポートされなくなるまで、アルファベット順に上から汎用要素のリストが開始されます。
基になるデータ セットに 60 (系列の最大数) 以上の系列が含まれている場合、そのアルゴリズムはアルファベット順に系列を並べ替え、アルファベット順に並べられた 60 番目の系列より後の系列を削除します。
データの値の型が "数値" や "日付/時刻" でない場合、Power BI はアルゴリズムを使用せず、以前のアルゴリズム (非高密度サンプリング) に戻します。
このアルゴリズムでは、[データのない項目を表示する] 設定がサポートされていません。
SQL Server Analysis Services 2016 以前でホストされているモデルへのライブ接続を使用する場合、このアルゴリズムはサポートされません。 Power BI または Azure Analysis Services でホストされているモデルではサポートされます。