Power Queryのデータ型は、より構造化されたデータ セットを持つ値を分類するために使用されます。 データ型はフィールド レベルで定義されます。フィールド内の値は、フィールドのデータ型準拠設定されます。
列のデータ型は、列見出しの左側に、データ型をシンボル表示するアイコンと共に表示されます。
![]()
注
Power Queryでは、列のデータ型に基づいて一連のコンテキスト変換とオプションが提供されます。 たとえば、データ型が Date の列を選択すると、その特定のデータ型に適用される変換とオプションが取得されます。 これらの変換とオプションは、Power Query インターフェイス全体 (Transform および Add column タブ、スマート フィルター オプションなど) で実行されます。
Power Queryで使用される最も一般的なデータ型を次の表に示します。 この記事の範囲を超えていますが、Power Query M Types と型変換記事で一般的に使用されるデータ型の一覧を確認できます。 Power Query M 数式言語のデータ型の完全な一覧Types記事もあります。
| データ型 | アイコン | 説明 |
|---|---|---|
| テキスト | 
|
Unicode 文字データ文字列。 文字列、数値、またはテキスト形式で表される日付を指定できます。 文字列の最大長は 268,435,456 Unicode 文字 (各 Unicode 文字は 2 バイト) または 536,870,912 バイトです。 |
| 真/偽 | 
|
True または False のいずれかのブール値。 |
| 10 進数 | 
|
64 ビット (8 バイト) の浮動小数点数を表します。 それは最も一般的な数値型であり、普段皆さんが思い浮かべる数字に対応しています。 小数部の値を持つ数値を処理するように設計されていますが、整数も処理します。 Decimal Number 型では、-1.79E +308 ~ –2.23E –308、0、および 2.23E –308 ~ 1.79E + 308 の正の値を処理できます。 たとえば、34、34.01、34.000367063 などの数値は有効な 10 進数です。 10 進数型で表すことができる最大の有効桁数は、15 桁です。 小数点区切り記号は、数値の任意の場所で使用できます。 Decimal Number 型は、数値Excel格納する方法に対応します。 バイナリ浮動小数点数は、サポートされている範囲内のすべての数値を 100% 精度で表すことはできません。 したがって、特定の 10 進数を表すときに、精度の小さな違いが発生する可能性があります。 |
| 固定 10 進数 | 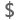
|
通貨型とも呼ばれるこのデータ型には、小数点区切り記号の固定位置があります。 小数点区切り記号は常に右に 4 桁の数字を持ち、19 桁の有効桁数を使用できます。 表すことができる最大値は 922,337,203,685,477.5807 (正または負) です。 10 進数とは異なり、固定小数点数型は常に正確であり、浮動小数点表記の不正確さがエラーを発生する可能性がある場合に役立ちます。 |
| 整数 | 
|
64 ビット (8 バイト) の整数値を表します。 整数であるため、小数点以下の桁数は表示されません。 19 桁の数字を使用できます。-9,223,372,036,854,775,808 (–2^63) から 9,223,372,036,854,775,807 (2^63-1) までの正または負の整数。 これは、さまざまな数値データ型の可能な限り最大の精度を表すことができます。 固定小数点数型と同様に、整数型は丸めを制御する必要がある場合に役立ちます。 |
| Percentage | 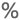
|
基本的には 10 進数型と同じですが、Power Query エディター ウィンドウで列の値をパーセンテージとして書式設定するためのマスクがあります。 |
| 日付/時刻 | 
|
日付と時刻の値の両方を表します。 内部では、日付/時刻の値が 10 進数型として格納されるため、2 つの間で実際に変換できます。 日付の時刻部分は、1/300 秒 (3.33 ミリ秒) の倍数全体に対する分数として格納されます。 1900 年から 9999 年までの日付がサポートされています。 |
| 日付 | 
|
日付のみを表します (時刻部分なし)。 モデルに変換すると、Date は、小数部の値がゼロの日付/時刻値と同じです。 |
| 時間 | 
|
時間のみを表します(日付部分なし)。 モデルに変換すると、Time 値は、小数点以下の桁数のない日付/時刻値と同じです。 |
| 日付/時刻/タイムゾーン | 
|
タイム ゾーン オフセットを持つ UTC 日付/時刻を表します。 モデルに読み込まれると、日付/時刻に変換されます。 |
| 期間 | 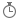
|
モデルに読み込まれるときに 10 進数型に変換される時間の長さを表します。 10 進数型として、正しい結果を持つ日付/時刻フィールドから加算または減算できます。 これは 10 進数型であるため、大きさを示す視覚化で簡単に使用できます。 |
| バイナリ | 
|
バイナリ データ型を使用して、バイナリ形式の他のデータを表すことができます。 |
| [任意] | 
|
Any データ型は、明示的なデータ型定義を持たない列に与えられる状態です。 Any は、すべての値を分類するデータ型です。 非構造化ソースからのクエリの列データ型は、常に明示的に定義することをお勧めします。 また、クエリの出力として Any データ型を持つ列は使用しないでください。 |
データ型の検出
データ型の検出は、接続する際に自動的に行われます。
データベースなどの構造化データ ソースPower Query、データ ソースからテーブル スキーマを読み取り、列ごとに適切なデータ型を使用してデータを自動的に表示します。
Excel、CSV、テキスト ファイルなどの非構造化ソースは、テーブル内の値を調べることでデータ型を自動的に検出Power Query。 既定では、非構造化ソースのPower Queryで自動データ型検出が有効になっています。
[変換] タブの [任意の列] グループの [データ 型の検出] コマンドを使用して、テーブル内の列のデータ型を自動的に検出することもできます。
![]()
列データ型を定義する方法
列のデータ型は、次の 4 つの場所のいずれかで定義または変更できます。
[ ホーム ] タブの [ 変換 ] グループの [ データ型 ] ドロップダウン メニュー。
![[ホーム] タブの [データ型] メニューのスクリーンショット。](media/data-types/home-tab.png)
[ 変換 ] タブの [ 任意の列 ] グループの [ データ型 ] ドロップダウン メニュー。
![[変換] タブの [データ型] メニューのスクリーンショット。](media/data-types/transform-tab.png)
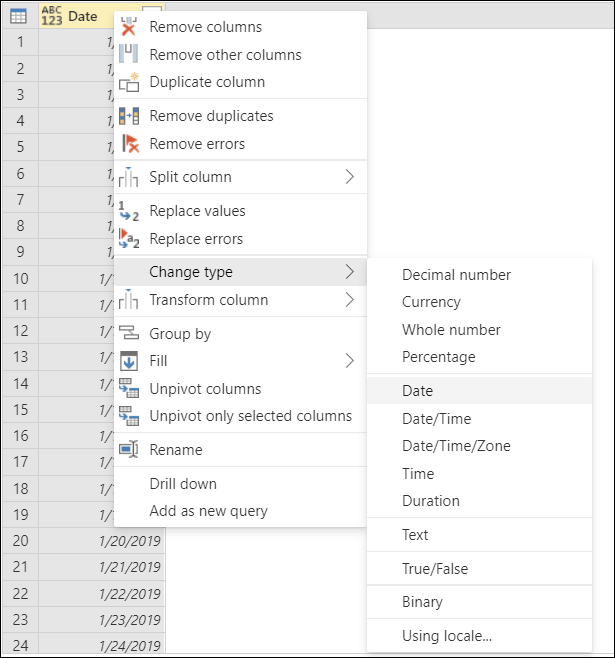
列見出しの左側にあるアイコンを選択します。
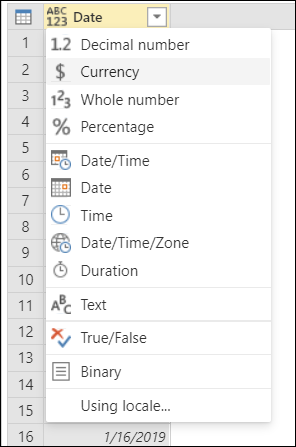
列のショートカット メニューの [型の変更]。
![[ホーム] タブの [データ型] メニューのスクリーンショット。](media/data-types/home-tab.png#lightbox)
列データ型とヘッダーの自動検出
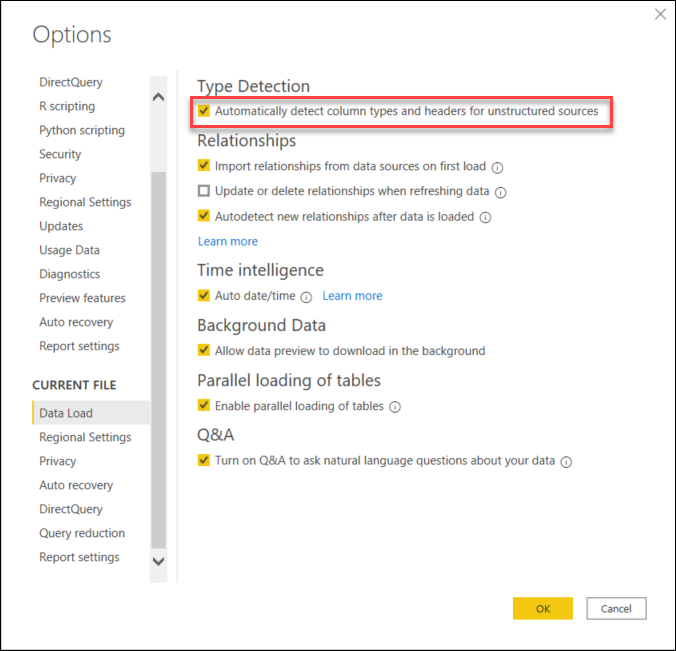
この設定は、非構造化ソース専用です。 テーブルの最初の 200 行に基づいて列の種類とヘッダーを自動的に検査して検出することで役立ちます。 この設定を有効にすると、Power Query自動的に 2 つのステップがクエリに追加されます。
- 列ヘッダーの昇格: テーブルの最初の行を列ヘッダーに昇格します。
- 変更された型: 各列の値の検査に基づいて、Any データ型の値をデータ型に変換します。
既定では、この設定は有効です。 この設定を無効または有効にするには、Power Query エクスペリエンスに適用される手順に従います。
Power Query Online でデータ型の自動検出を構成するには

Power Query Desktop でデータ型の自動検出を構成するには
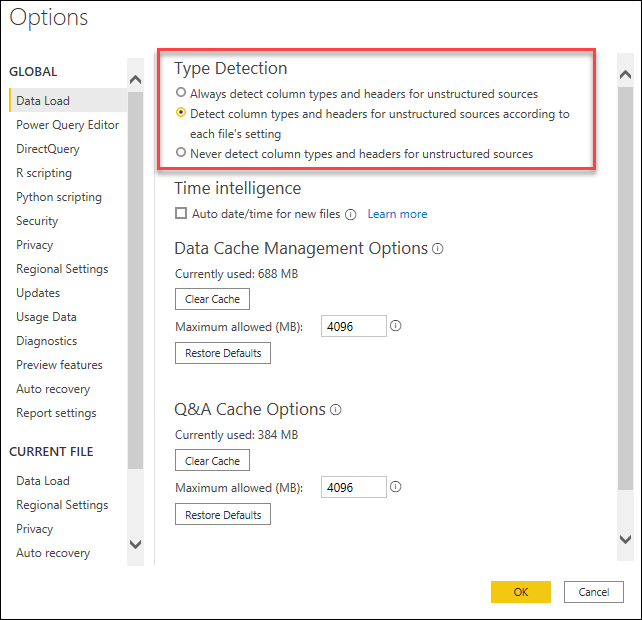
この動作は、Power Query エディターの Options ウィンドウで、グローバル レベルとファイル単位の両方のレベルで定義できます。 File タブで、Options と settings>Options) を選択します。
[グローバル]: 左側のウィンドウの [グローバル] で、[データの読み込み] を選択します。 [型検出の右側のウィンドウで、アプリケーションで作成されたすべての新しいファイルに適用される 3 種類の検出構成のいずれかを選択できます。
- 非構造化ソースの列の種類とヘッダーを常に検出
- 各ファイルの設定に従って、非構造化ソースの列の種類とヘッダーを検出
- 非構造化ソースの列の種類とヘッダーを検出しない
現在のファイル: 左側のペインで、[現在のファイル] の下の [データの読み込み] を選択します。 [型検出の右側のウィンドウで、現在のファイルの型検出を有効または無効にするかどうかを選択します。


ドキュメントまたはプロジェクトのロケール
Power Queryは、物事の外観と解釈方法を管理する 2 つの異なるコンポーネントを処理します。
- ローカライズ: 表示する言語をPower Queryに指示するコンポーネント。
- グローバリゼーション: テキスト値の解釈に加えて、値の書式設定を処理するコンポーネント。
ロケール は、ローカリゼーション コンポーネントとグローバリゼーション コンポーネントの両方を保持する単一の値です。 ロケールは、テキスト値を解釈し、他のデータ型に変換するために使用されます。 たとえば、ロケール English (米国) は、ローカリゼーション が米国英語であり、グローバリゼーション、または値の形式については、米国で使用される標準に基づいていることを意味します。
Power Queryで列データ型を定義したり、あるデータ型から別のデータ型に変換したりする場合は、変換する値を解釈してから別のデータ型に変換する必要があります。
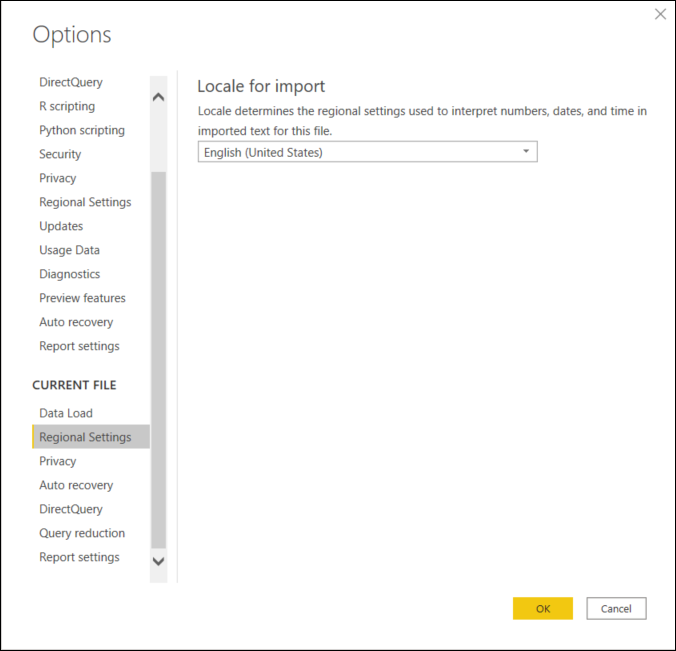
Power Query Online では、この解釈は Project オプションの Regional 設定で定義されます。
Power Query Online のロケール オプション設定のスクリーンショット Power Query Desktop では、Power Queryはオペレーティング システムの地域形式を自動的に認識し、データ型変換の値を解釈するために使用します。 このロケールの構成をオーバーライドするには、クエリ オプション ウィンドウを開き、左側のウィンドウの [現在のファイル ] の下にある [地域設定] 選択します。 ここから、ロケールを目的の設定に変更できます。

このロケール設定は、テキスト値を特定のデータ型に解釈するために重要です。 たとえば、ロケールが English (米国) として設定されているが、CSV ファイルの 1 つの列に日付が日/月/年の英国形式で書式設定されていることを想像してください。
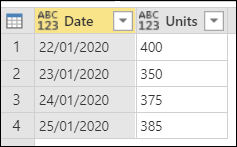
日付 列のデータ型を日付 に設定しようとすると、エラー値が表示されます。
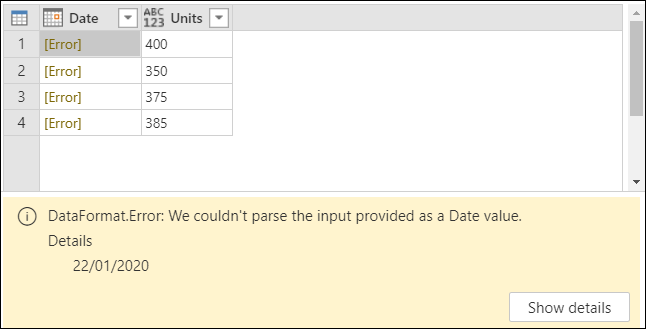
これらのエラーは、使用されているロケールが英語 (米国) 形式 (月/日/年) で日付を解釈しようとしているために発生します。 カレンダーに月 22 がないため、エラーが発生します。
Date データ型を選択する代わりに、列見出しを右クリックし、[型の変更] を選択してから、[ロケールを使用] を選択します。
![列のショートカット メニューの [using locale]\(ロケールの使用\) オプションのスクリーンショット。](media/data-types/locale-sample-right-click.png)
[ロケール を使用して列の種類を変更する] ダイアログ ボックスで、設定するデータ型を選択しますが、使用するロケールも選択します。この場合は、英語 (英国) する必要があります。
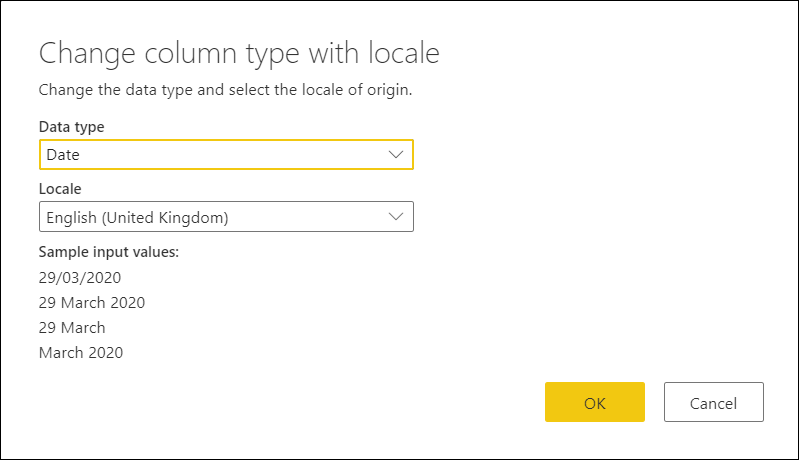
このロケールを使用すると、Power Queryは値を正しく解釈し、それらの値を適切なデータ型に変換できます。
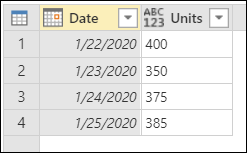
終了日の値を確認するには
グローバリゼーション値は、日付値の書式設定を促進します。 Power Queryによって表示される値に疑問がある場合は、日付、月、および年の新しい列を値から追加することで、日付値の変換を確認できます。 これらの新しい列を追加するには、日付 列を選択し、リボンの [列の追加] タブに移動します。 日付と時刻の列 グループに、日付列のオプションが表示されます。

ここから、年番号、月番号、日番号、日付 列から抽出されたさらに多くの列など、日付値の一部を抽出できます。

これらの列を使用すると、日付値が正しく変換されていることを確認できます。
データ型変換マトリックス
次のマトリックスは、あるデータ型から別のデータ型への値のデータ型変換の実現可能性を簡単に確認できるように設計されています。
注
変換は、このマトリックスにおけるデータ型列の元のデータ型から開始します。 新しい型への変換の各結果は、元のデータ型の行に表示されます。
| データ型 |
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|---|
|
10 進数 |
— | 
|
|

|
|
|

|

|
|
|
|
|
通貨 |
|
— |
|
|
|
|
|
|
|
|
|
|
整数 |
|
|
— |
|
|
|
|
|
|
|
|
|
パーセンテージ |
|
|
|
— |
|
|
|
|
|
|
|
|
日付/時刻 |
|
|
|
|
— |
|
|
|
|
|
|
|
日付 |
|
|
|
|
|
— |
|
|
|
|
|
|
時刻 |
|
|
|
|
|
|
— |
|
|
|
|
|
日付/時刻/タイムゾーン |
|
|
|
|
|
|
|
— |
|
|
|
|
期間 |
|
|
|
|
|
|
|
|
— |
|
|
|
テキスト |
|
|
|
|
|
|
|
|
|
— |
|
|
真/偽 |
|
|
|
|
|
|
|
|
|
|
— |
| アイコン | 説明 |
|---|---|
|
|
可能 |
|
|
無理です |
|
|
可能ですが、元の値に値を追加します |
|
|
可能ですが、元の値が切り捨てられます |
Power Query M の型
一般的に使用されるデータ型の一覧については、Power Query M Types と型変換に関する記事を参照してください。 Power Query M 数式言語のデータ型の完全な一覧Types記事もあります。