この手順では、Dataverse にテーブルを作成し、Power Query を使用して OData フィードからそのテーブルにデータを取り込みます。 同じ手法を使用して、次のようなオンライン ソースとオンプレミス ソースのデータを統合することができます:
- SQL Server
- Salesforce
- IBM DB2
- アクセス
- Excel
- Web APIs
- OData フィード
- テキスト ファイル
また、新規または既存のテーブルに読み込む前に、データのフィルター処理、変換、結合を行うこともできます。
Power Apps のライセンスがない場合は、無料でサインアップできます。
前提条件
この記事のフォローを開始する前に、次の手順を実行します。
- テーブルを作成できる環境に切り替えます。
- ユーザーごとの Power Apps プランまたはアプリごとの Power Apps プランのご利用が必要です。
ソース データを指定する
Power Apps にサインインします。
ナビゲーション ウィンドウで、テーブル を選択します。
![[テーブル] タブが選択され、[テーブル] ペインが開いているナビゲーション ペインのスクリーンショット。](media/add-data-power-query/view-entities-portal.png)
コマンド メニューで、インポート>データのインポート を選択します。
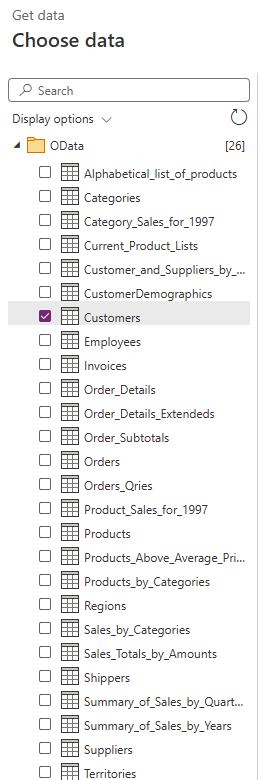
データ ソースの一覧で、[OData] を選択します。
![Power Query の [データ ソース] 選択画面を開き、OData コネクタを強調表示したスクリーンショット。](media/add-data-power-query/choose-odata.png)
[接続設定] で、次の URL を入力または貼り付けてから、[次へ] を選択します。
https://services.odata.org/V4/Northwind/Northwind.svc/テーブルの一覧で、Customers のチェック ボックスをオンにして、[次へ] を選択します。
(省略可能) スキーマを要件に合わせて変更します。含める列を選択する、1 つ以上の方法でテーブルを変換する、インデックスまたは条件付き列を追加する、などの変更を行ってください。
右下隅にある [次へ] を選択します。
![[テーブル] タブが選択され、[テーブル] ペインが開いているナビゲーション ペインのスクリーンショット。](media/add-data-power-query/view-entities-portal.png#lightbox)
![Power Query の [データ ソース] 選択画面を開き、OData コネクタを強調表示したスクリーンショット。](media/add-data-power-query/choose-odata.png#lightbox)
ターゲット テーブルを指定する (プレビュー)
[読み込みの設定] で、[新しいテーブルに読み込む] を選択します。
![[新しいテーブルに読み込む] に設定された [読み込み設定] メニューのスクリーンショット。](media/add-data-power-query/load-to-new-table.png)
新しいテーブルに別の名前または表示名を付けることもできますが、このチュートリアルどおりに進めるなら、既定値のままにします。
[一意のプライマリ名列] の一覧で、ContactName を選択し、[次へ] を選択します。
別のプライマリ名列を指定するか、作成中のテーブルの各列にソース テーブルの別の列をマップするかのいずれか、または両方を行うことができます。 また、Dataverse に、クエリ出力のテキスト列を、複数行テキストとして作成するか、単一行テキストとして作成するかを指定することもできます。 このチュートリアルを正確に行うために、列マッピングを既定のまま使用してください。
Power Query の更新設定で、[手動で更新] を選択し、[公開] を選択します。
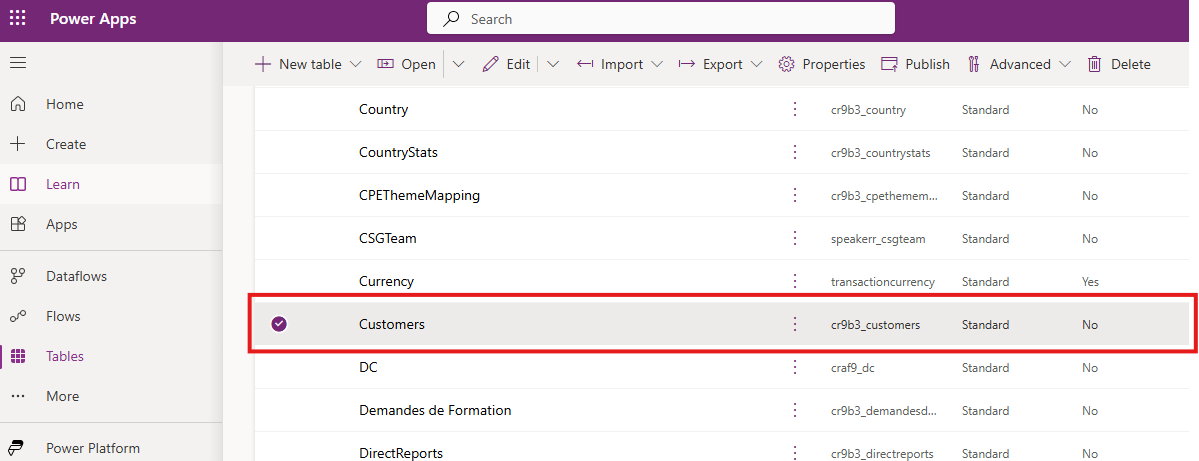
[Dataverse] (左端近く) で、[テーブル] を選択し、データベース内のテーブルの一覧を表示します。
OData フィードから作成した Customers テーブルが、カスタム テーブルとして表示されます。
![[新しいテーブルに読み込む] に設定された [読み込み設定] メニューのスクリーンショット。](media/add-data-power-query/load-to-new-table.png#lightbox)

警告
クエリ出力に存在しない行を削除するを有効にするか、プライマリ キー列を定義した状態で Dataverse テーブルにデータを読み込むと、既存のデータが変更または削除される可能性があります。
既存のテーブルへの読み込み (プレビュー)
[既存のテーブルに読み込む] を選択した場合は、データを読み込む既存の Dataverse テーブルを指定できます。
テーブルドロップダウンを選択すると、ドロップダウンの上部に最大 3 つの推奨される Dataverse テーブルが表示され、その後ろに他のすべての Dataverse テーブルが表示されます。 これらのテーブルの推奨事項は、列メタデータ (列名と列の種類) と既存の Dataverse テーブルの列メタデータの比較に基づいています。 最大 3 つの Dataverse テーブルが推奨され、最も推奨されるものが最初にリストされます。 推奨事項が見つからない場合、ドロップダウンには既定ですべてのテーブルのみがリストされます。
![推奨テーブルが表示された[宛先の設定を選択]ダイアログのスクリーンショット。](media/add-data-power-query/recommended-tables.png#lightbox)
データを読み込む Dataverse テーブルを選択した後、インポート方法を選択します。 [追加] が既定で選択され、以前に選択した Dataverse テーブルにデータが行として追加されます。 マージにより、Dataverse テーブル内の既存の行が更新されます。 Merge を選択すると、使用する主キー列を選択するオプションがあります。
![インポート方法の選択が表示された [宛先の設定を選択する] ダイアログのスクリーンショット。](media/add-data-power-query/import-method-selection.png#lightbox)
列マッピング (プレビュー)
コピー先の Dataverse テーブルを選択し、インポート方法を指定すると、列は、マッピング済み、可能性のある一致、未マッピングにグループ化されます。 これらのグループ化を切り替えるには、上部にある [Mapped] (マッピング済)、 [Possible match] (可能性のある一致)、または [Unmapped] (マッピングなし) タブを選択するか、すべてのマッピングを一覧表示する既定の [すべて表示] タブを使用します。
![列マッピングの選択肢が表示された [宛先設定の選択] ダイアログのスクリーンショット。](media/add-data-power-query/column-mapping.png#lightbox)
ソースと変換先の列のマッピングは、次のようにグループ化されます。
対応付け済み: 列名の意味が高い確信度で一致しており、かつ両方の列のデータ型が同じです。
未マッピング: この列については、高い信頼度のセマンティック列の一致が見つかりません。 この列が必須の列の場合は、先に進む前に、このデータをマップするソース列を手動で選択する必要があります。
Possible match (可能性のある一致): 列名の意味は一致するが、ソース列と変換先列のデータ型が異なります。
ソース列のマッピングに手動で変更を加えると、列のデータ型が異なる場合を除き、状態は Mapped (マッピング済み) に変わります。 その場合、状態は Possible match (可能性のある一致) に更新されます。 考えられるすべての一致と同様に、推奨されるアクション メッセージでは、データフローの 1 つのステップに戻り、Dataverse テーブルの変換先列の種類と一致するようにソース列の種類を変更することをお勧めします。
既知の制限
AI 支援マッピングでは、列間の型の不一致のみを検出できます。 これらの課題では受信データのレコードをプレビューする必要があるため、次の一覧の他の列マッピングの課題を検出できません。
切り捨て: ソースと変換先の間のセマンティック一致の信頼性が高くなりますが、ソース内の少なくとも 1 つのレコードの文字数が、変換先列の文字制限を超えています。
値の制限: ソースと変換先の間のセマンティック一致の信頼性が高くなりますが、ソース内の少なくとも 1 つのレコードに、変換先列によって設定された値制限の範囲外の値が含まれています。
ルックアップ値: ソースと変換先の間のセマンティック一致の信頼性が高くなりますが、ソース内の少なくとも 1 つのレコードに、変換先列によって設定された参照値に存在しない値が含まれています。
アクセス許可に関するエラー メッセージが表示されたら、管理者に問い合わせてください。
テーブル選択と列マッピングの提案は、特定の Power Platform 環境では利用できない可能性があるソリューションによって提供されます。 このソリューションを検出できない場合、テーブル選択と列マッピングの提案はシステムによって提供されたものではありません。 ですが、引き続き手動での続行は可能です。