開発しているデータフローがますます複雑になっている場合は、元の設計を改善するためにできることがいくつかあります。
複数のデータフローに分割する
1 つのデータフローですべてを実行しないでください。 単一の複雑なデータフローによってデータ変換プロセスが長くなるだけでなく、データフローの理解と再利用も困難になります。 データフローを複数のデータフローに分割するには、異なるデータフロー内のテーブル、または 1 つのテーブルを複数のデータフローに分割します。 計算テーブルまたはリンク テーブルの概念を使用して、変換の一部を 1 つのデータフローに構築し、他のデータフローで再利用できます。
ステージング/抽出データフローからデータ変換データフローを分割する
データの抽出専用のデータフロー (つまり、 ステージング データフロー) やデータ変換用のデータフローがある場合は、多層アーキテクチャを作成する場合だけでなく、データフローの複雑さを軽減するのにも役立ちます。 一部の手順では、データの取得、ナビゲーション、データ型の変更など、データ ソースからデータを抽出するだけです。 ステージング データフローと変換データフローを分離することで、データフローの開発が簡単になります。
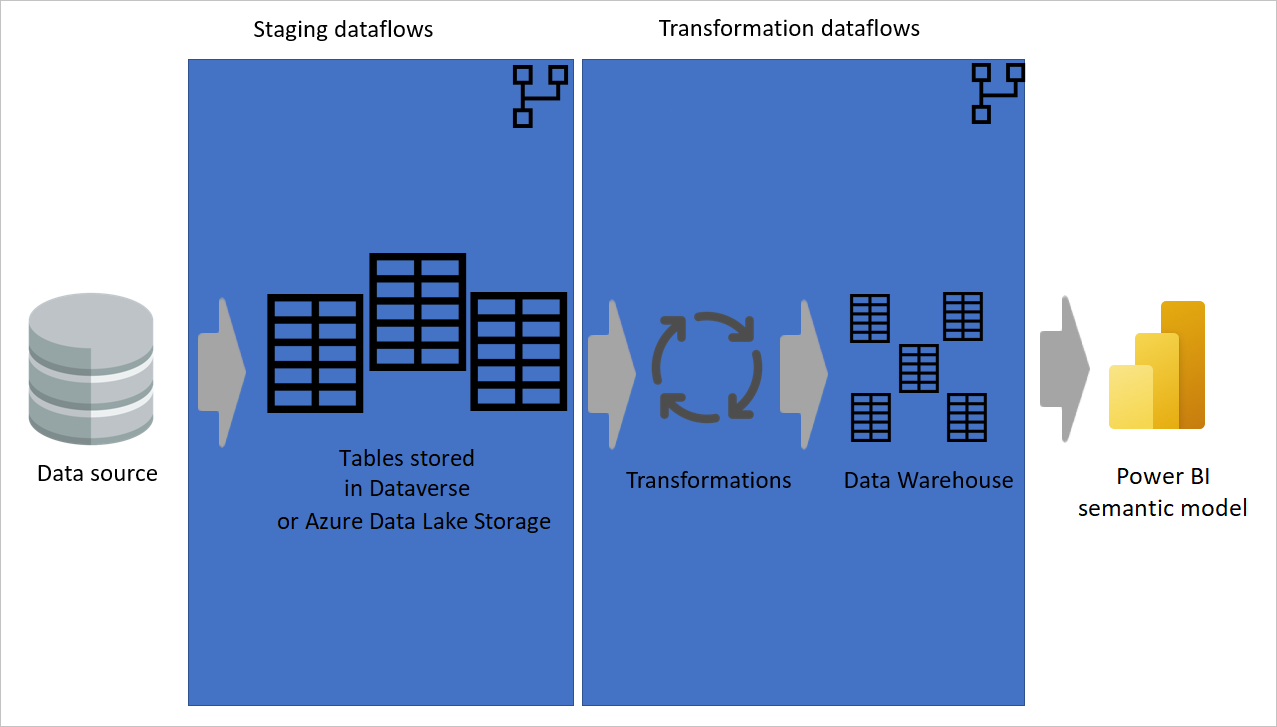
データ ソースからステージング データフローに抽出されるデータを示す画像。テーブルは Dataverse または Azure Data Lake Storage に格納されます。 その後、データは変換データフローに移動され、そこでデータが変換され、データ ウェアハウス構造に変換されます。 その後、データはセマンティック モデルに移動されます。
カスタム関数を使用する
カスタム関数は、さまざまなソースからの多数のクエリに対して特定の数の手順を実行する必要があるシナリオで役立ちます。 カスタム関数は、Power Query エディターのグラフィカル インターフェイスまたは M スクリプトを使用して開発できます。 関数は、必要な数のテーブルのデータフローで再利用できます。
カスタム関数を使用すると、ソース コードのバージョンが 1 つしかないため、コードを複製する必要はありません。 その結果、Power Query 変換ロジックとデータフロー全体の維持がはるかに簡単になります。 詳細については、ブログ投稿「Power BI Desktopで簡単なカスタム関数の作成」を参照してください。
![Get Holidays カスタム関数とそのデータが強調された [クエリ] ペインのスクリーンショット。](media/best-practices-developing-complex-dataflows/custom-function.png)
注
カスタム関数を使用してデータフローを更新するために Premium 容量が必要であることを示す通知を受け取ることがあります。 このメッセージは無視して、データフロー エディターをもう一度開くことができます。 これにより、関数が "読み込みが有効な" クエリを参照しない限り、通常は問題が解決されます。
フォルダーにクエリを配置する
クエリにフォルダーを使用すると、関連するクエリをグループ化するのに役立ちます。 データフローを開発するときは、少し時間を費やして、意味のあるフォルダーにクエリを配置します。 この方法を使用すると、将来的にクエリをより簡単に見つけることができ、コードの保守がはるかに簡単になります。
計算テーブルを使用する
計算テーブルは、データフローをより理解しやすくするだけでなく、パフォーマンスも向上します。 計算テーブルを使用すると、そのテーブルから参照される他のテーブルは、"既に処理されて格納されている" テーブルからデータを取得します。 変換ははるかに簡単で高速です。
強化されたコンピューティング エンジンを活用する
Power BI 管理ポータルで開発されたデータフローの場合は、他の種類の変換を実行する前に、計算テーブルで最初に結合とフィルター変換を実行して、拡張コンピューティング エンジンを使用するようにしてください。
多くのステップを複数のクエリに分割する
1 つのテーブルで多数のステップを追跡するのは困難です。 代わりに、多数のステップを複数のテーブルに分割する必要があります。 他のクエリに 対して [読み込みを有効にする] を使用し、中間クエリの場合は無効にし、データフローを介してのみ最終的なテーブルを読み込むことができます。 ステップが小さいクエリが複数ある場合は、1 つのクエリで数百のステップを掘り下げるのではなく、依存関係図を使用し、各クエリを追跡してさらに調査する方が簡単です。
クエリとステップのプロパティを追加する
ドキュメントは、保守が容易なコードを作成するための鍵です。 Power Query では、テーブルおよびステップにプロパティを追加できます。 プロパティに追加したテキストは、そのクエリまたはステップにカーソルを合わせるとヒントとして表示されます。 このドキュメントは、将来モデルを維持するのに役立ちます。 テーブルまたはステップをひとめで確認すれば、その手順で行ったことを再考して記憶するのではなく、そこで何が起こっているかを理解できます。
容量が同じリージョンにあることを確認する
データフローは現在、複数の国または地域をサポートしていません。 Premium 容量は、Power BI テナントと同じリージョンにある必要があります。
オンプレミスのソースとクラウド ソースを分離する
オンプレミス、クラウド、SQL Server、Spark、Dynamics 365 など、ソースの種類ごとに個別のデータフローを作成することをお勧めします。 データフローをソースの種類別に分離すると、トラブルシューティングが簡単になり、データフローを更新するときの内部制限が回避されます。
テーブルに必要なスケジュールされた更新に基づいてデータフローを分離する
ソース システムで 1 時間ごとに更新される販売トランザクション テーブルがあり、毎週更新される製品マッピング テーブルがある場合は、これら 2 つのテーブルを異なるデータ更新スケジュールを持つ 2 つのデータフローに分割します。
同じワークスペース内のリンク テーブルの更新をスケジュールしないようにする
リンク テーブルを含むデータフローから定期的にロックアウトされている場合は、データフローの更新中にロックされているのと同じワークスペース内の対応する依存データフローが原因である可能性があります。 このようなロックにより、トランザクションの精度が確保され、両方のデータフローが正常に更新されますが、編集がブロックされる可能性があります。
リンクされたデータフローの別のスケジュールを設定した場合、データフローを不必要に更新し、データフローの編集をブロックすることができます。 この問題を回避するには、次の 2 つの推奨事項があります。
- ソース データフローと同じワークスペース内のリンクされたデータフローの更新スケジュールを設定しないでください。
- 更新スケジュールを個別に構成し、ロック動作を回避する場合は、データフローを別のワークスペースに移動します。