ディメンション モデルの設計は、データフローで実行できる最も一般的なタスクの 1 つです。 この記事では、データフローを使用してディメンション モデルを作成するためのベスト プラクティスについて説明します。
ステージングデータフロー
データ統合システムの重要なポイントの 1 つは、ソース運用システムからの読み取りの数を減らすことです。 従来のデータ統合アーキテクチャでは、この削減は 、ステージング データベースと呼ばれる新しいデータベースを作成することによって行われます。 ステージング データベースの目的は、データ ソースからステージング データベースにデータ as-is を定期的に読み込む方法です。
その後、データ統合の残りの部分では、ステージング データベースをさらなる変換のソースとして使用し、ディメンション モデル構造に変換します。
データフローを使用して同じ方法に従うことをお勧めします。 ソース システムからデータ as-is を読み込むだけの一連のデータフローを作成します (必要なテーブルに対してのみ)。 結果は、データフローのストレージ構造 (Azure Data Lake Storage または Dataverse) に格納されます。 この変更により、ソース システムからの読み取り操作が最小限に抑えられます。
次に、ステージング データフローからデータをソースとする他のデータフローを作成できます。 このアプローチの利点は次のとおりです。
- ソース システムからの読み取り操作の数を減らし、結果としてソース システムの負荷を軽減します。
- オンプレミスのデータ ソースが使用されている場合のデータ ゲートウェイの負荷を軽減する。
- ソース システムのデータが変更された場合に備え、調整のためにデータの中間コピーを用意します。
- 変換データフローをソースに依存しません。
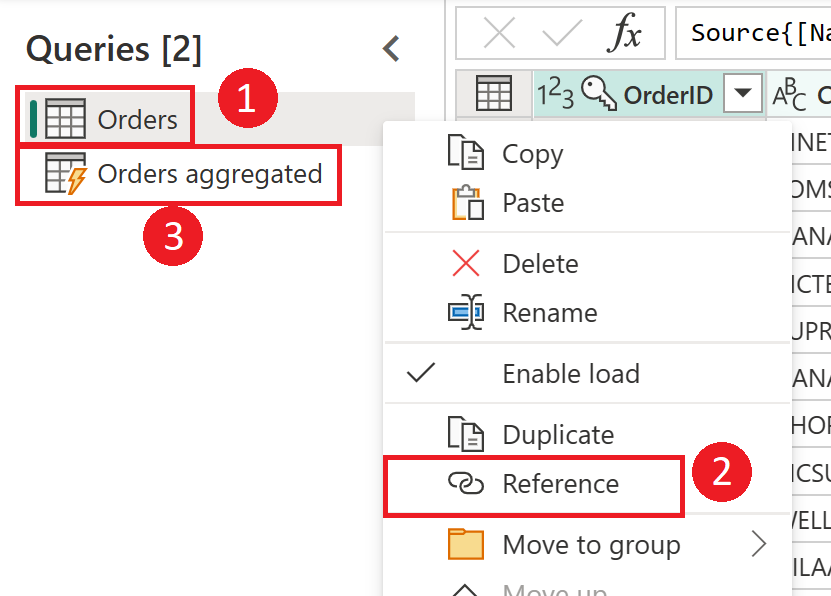
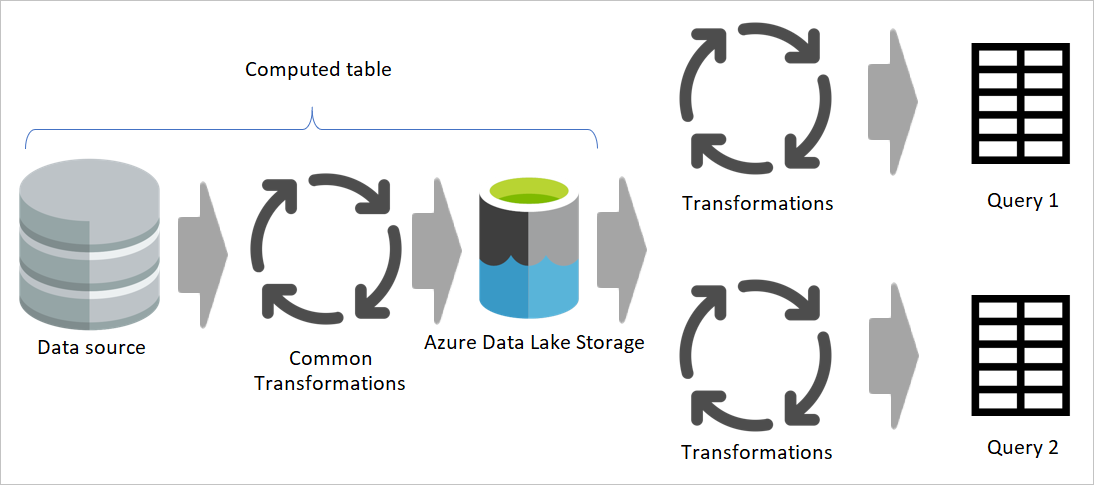
ステージング データフローとステージング ストレージを強調する図。 この図は、ステージング データフローによってデータ ソースからアクセスされるデータと、Cadavers または Azure Data Lake Storage に格納されているテーブルを示しています。 その後、テーブルは他のデータフローと共に変換され、クエリとして送信されます。
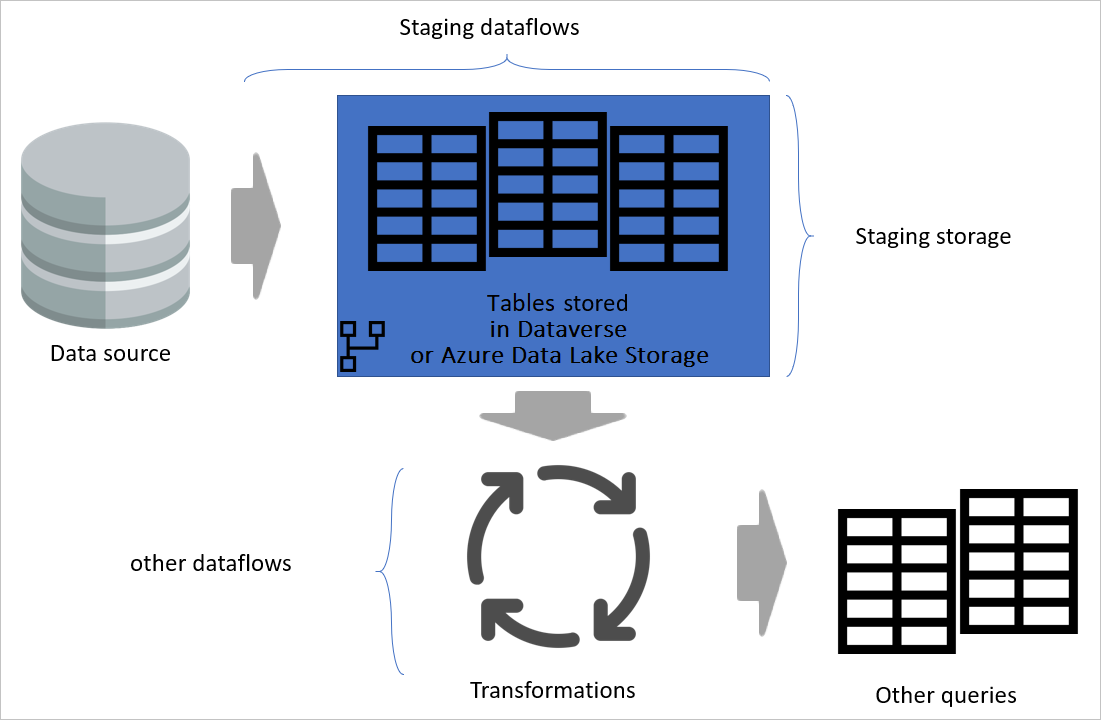
変換データフロー
変換データフローをステージング データフローから分離すると、変換はソースに依存しません。 この分離は、ソース システムを新しいシステムに移行する場合に役立ちます。 その場合に行う必要があるのは、ステージング データフローを変更することです。 変換データフローはステージング データフローからのみソース化されるため、問題なく動作する可能性があります。
この分離は、ソース システムの接続が遅い場合にも役立ちます。 変換データフローは、ソース システムからの低速接続を経由してレコードを取得するために長い時間待機する必要はありません。 ステージング データフローでは既にその部分が行われ、データは変換レイヤーの準備ができています。
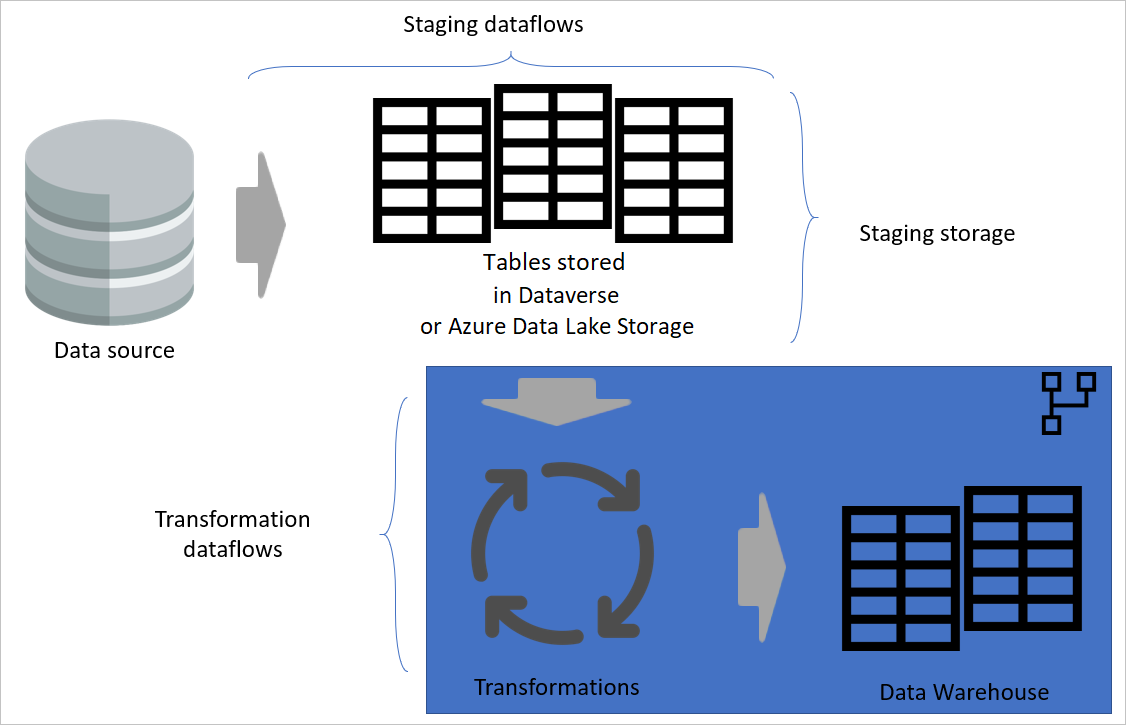
レイヤード アーキテクチャ
階層化アーキテクチャは、個別のレイヤーでアクションを実行するアーキテクチャです。 ステージングデータフローと変換データフローは、多層データフロー アーキテクチャの 2 つのレイヤーにすることができます。 レイヤーでアクションを実行しようとすると、必要な最小限のメンテナンスが保証されます。 何かを変更する場合は、配置されているレイヤーで変更するだけで済みます。 他のレイヤーはすべて正常に動作し続ける必要があります。
次の図は、Power BI セマンティック モデルでテーブルが使用されるデータフローの多層アーキテクチャを示しています。
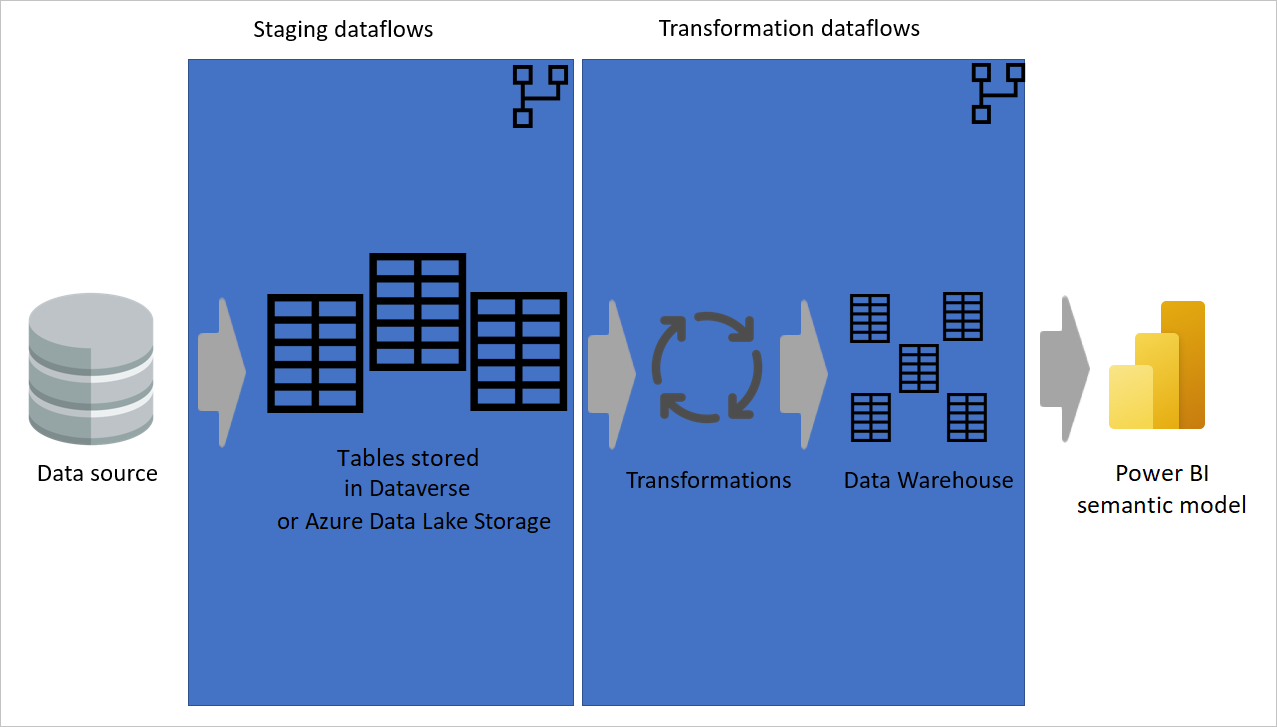
計算テーブルを可能な限り使用する
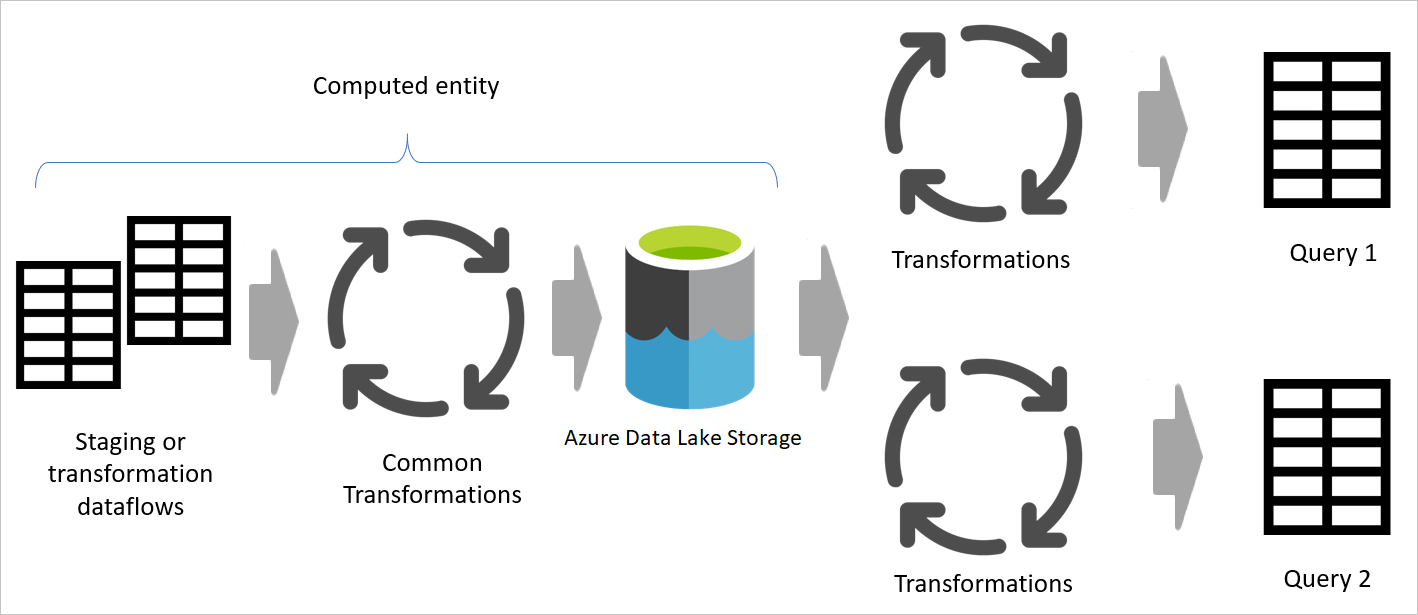
別のデータフローでデータフローの結果を使用する場合は、計算テーブルの概念を使用します。つまり、"既に処理されて格納されている" テーブルからデータを取得します。 データフロー内でも同じことが起こる可能性があります。 別のテーブルからテーブルを参照する場合は、計算テーブルを使用できます。 このメソッドは、 一般的な変換と呼ばれる複数のテーブルで実行する必要がある一連の変換がある場合に役立ちます。
前の図では、計算テーブルはソースから直接データを取得します。 ただし、ステージングデータフローと変換データフローのアーキテクチャでは、計算テーブルがステージング データフローからソース化される可能性があります。
スター スキーマを作成する
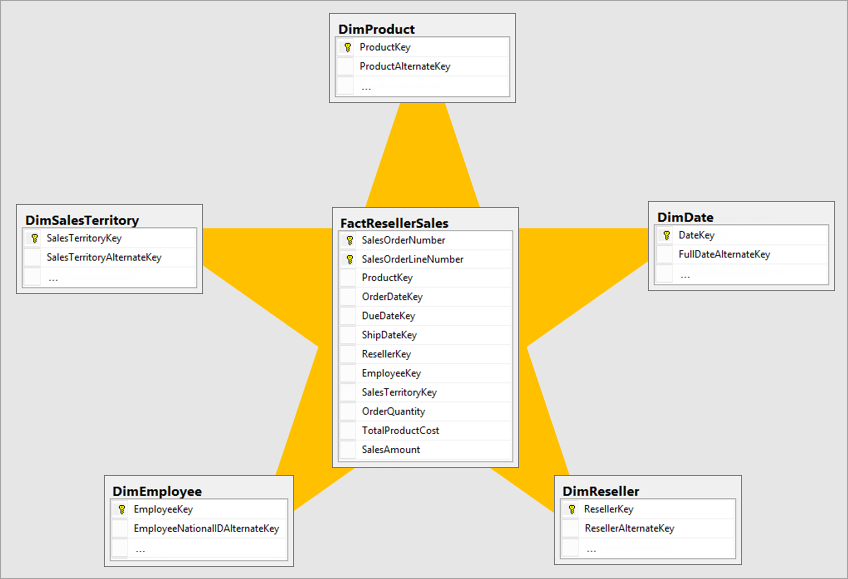
最適なディメンション モデルは、モデルからデータを照会する時間を最小限に抑えるために設計されたディメンションとファクト テーブルを持つスター スキーマ モデルです。 スター スキーマ モデルを使用すると、データ ビジュアライザーの理解も容易になります。
運用システムと同じレイアウトのデータを BI システムに取り込むのは理想的ではありません。 データ テーブルをリフォームする必要があります。 一部のテーブルは、説明情報を保持するディメンション テーブルの形式にする必要があります。 集計可能なデータを保持するために、一部のテーブルはファクト テーブルの形式にする必要があります。 ファクト テーブルとディメンション テーブルを形成するのに最適なレイアウトは、スター スキーマです。 詳細については、「 スター スキーマと Power BI の重要性について」を参照してください。
ディメンションに一意のキー値を使用する
ディメンション テーブルを作成するときは、それぞれにキーがあることを確認します。 このキーを使用すると、ディメンション間に多対多 (つまり"弱い") リレーションシップがなくなります。 何らかの変換を適用して、列または列の組み合わせがディメンション内の一意の行を返すようにすることで、キーを作成できます。 その後、列の組み合わせをデータフロー内のテーブルのキーとしてマークできます。
![[キーとしてマーク] オプションとテーブルの日付列のキー アイコンが強調されている [Power Query 変換] タブのスクリーンショット。](media/best-practices-for-dimensional-model/mark-as-key.png)
大規模なファクト テーブルに対して増分更新を実行する
ファクト テーブルは、常にディメンション モデル内で最大のテーブルです。 これらのテーブルに転送される行の数を減らすことをお勧めします。 非常に大きなファクト テーブルがある場合は、そのテーブルに対して増分更新を使用してください。 増分更新は、Power BI セマンティック モデルとデータフロー テーブルでも実行できます。
増分更新を使用すると、変更された部分であるデータの一部のみを更新できます。 更新するデータの一部と永続化する部分を選択するには、複数のオプションがあります。 詳細については、「 Power BI データフローでの増分更新の使用」を参照してください。

ディメンションとファクト テーブルを作成するための参照
ソース システムでは、多くの場合、データ ウェアハウスでファクト テーブルとディメンション テーブルの両方を生成するために使用するテーブルがあります。 これらのテーブルは、計算テーブルと中間データフローにも適しています。 プロセスの一般的な部分 (データのクリーニング、追加の行と列の削除など) は、1 回実行できます。 これらのアクションの出力からの参照を使用して、ディメンション テーブルとファクト テーブルを生成できます。 この方法では、一般的な変換に計算テーブルを使用します。