Dataverse にデータを統合するときに発生する一般的なシナリオの 1 つは、ソースとの同期を維持することです。 標準データフローを使用すると、Dataverse にデータを読み込むことができます。 この記事では、ソース システムとデータの同期を維持する方法について説明します。
キー列の重要度
リレーショナル データ ベース システムをソースとして使用している場合は、通常、テーブルにキー列があり、データが Dataverse に読み込まれる適切な形式になっています。 ただし、Excel ファイルのデータは、常にそれほどクリーンであるとは限りません。 多くの場合、キー列を持たないデータ シートを含む Excel ファイルがあります。 標準データフローのフィールド マッピングに関する考慮事項では、ソースにキー列がある場合、データフローのフィールド マッピングの代替キーとして簡単に使用できることがわかります。
Dataverse のテーブルでは、キー列を使用することが重要です。 キー列は行識別子です。この列には、各行に一意の値が含まれています。 キー列を持つことは、重複する行を回避するのに役立ちます。また、データをソース システムと同期するのにも役立ちます。 ソース システムから行が削除された場合、キー列を持つことは、それを見つけて Dataverse からも削除するのに役立ちます。
キー列の作成
データ ソース (Excel、テキスト ファイル、またはその他のソース) にキー列がない場合は、次の方法を使用して生成できます。
データをクリーンアップします。
キー列を作成する最初の手順は、不要な行をすべて削除し、データをクリーンアップし、空の行を削除し、重複する可能性がある場合は削除することです。
インデックス列を追加します。
データがクリーンアップされたら、次の手順ではキー列を割り当てます。 この目的で、[ 列の追加 ] タブからインデックス 列の追加 を使用できます。
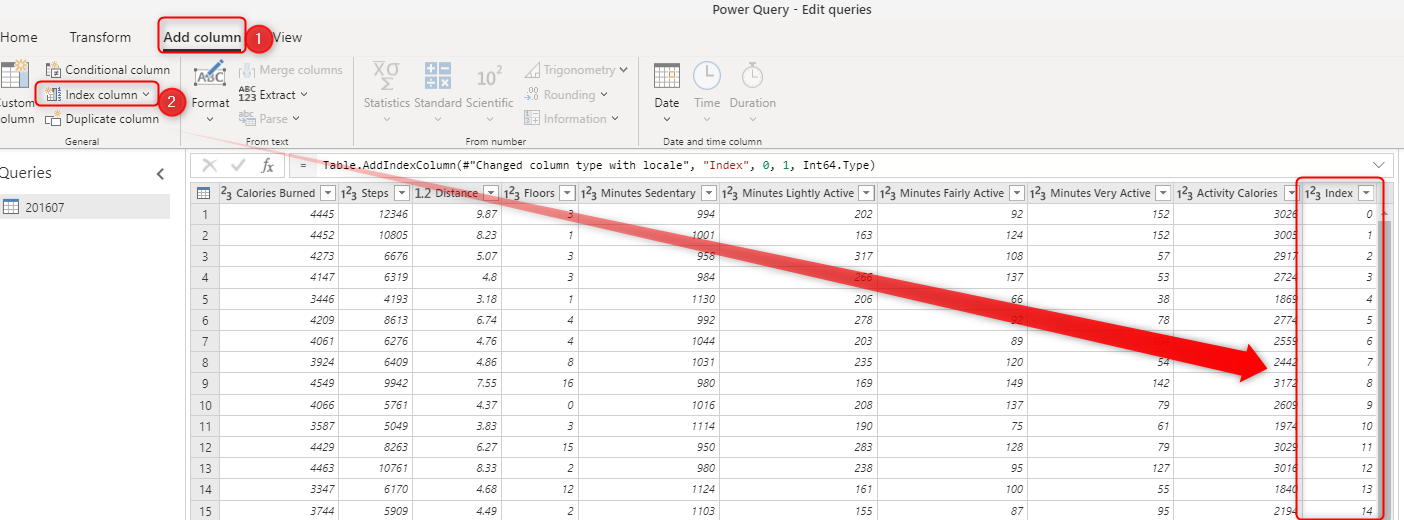
インデックス列を追加すると、開始番号のカスタマイズや毎回ジャンプする値の数など、インデックス列をカスタマイズするためのオプションがいくつかあります。 既定の開始値は 0 で、毎回 1 つの値がインクリメントされます。
代替キーとしてキー列を使用する
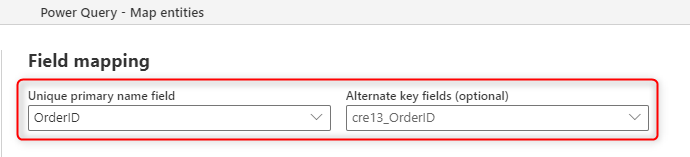
キー列が作成されたので、データフローのフィールド マッピングを代替キーに割り当てることができます。
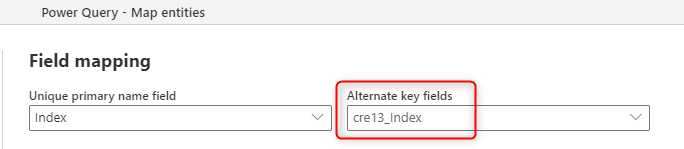
設定は単純で、代替キーを設定するだけで済みます。 ただし、複数のファイルまたはテーブルがある場合は、もう 1 つの手順を考慮する必要があります。
複数のファイルがある場合
Excel ファイル (またはシートまたはテーブル) が 1 つしかない場合は、前の手順の手順で代替キーを設定するだけで十分です。 ただし、同じ構造 (ただしデータが異なる) 複数のファイル (またはシートまたはテーブル) がある場合は、それらを追加します。
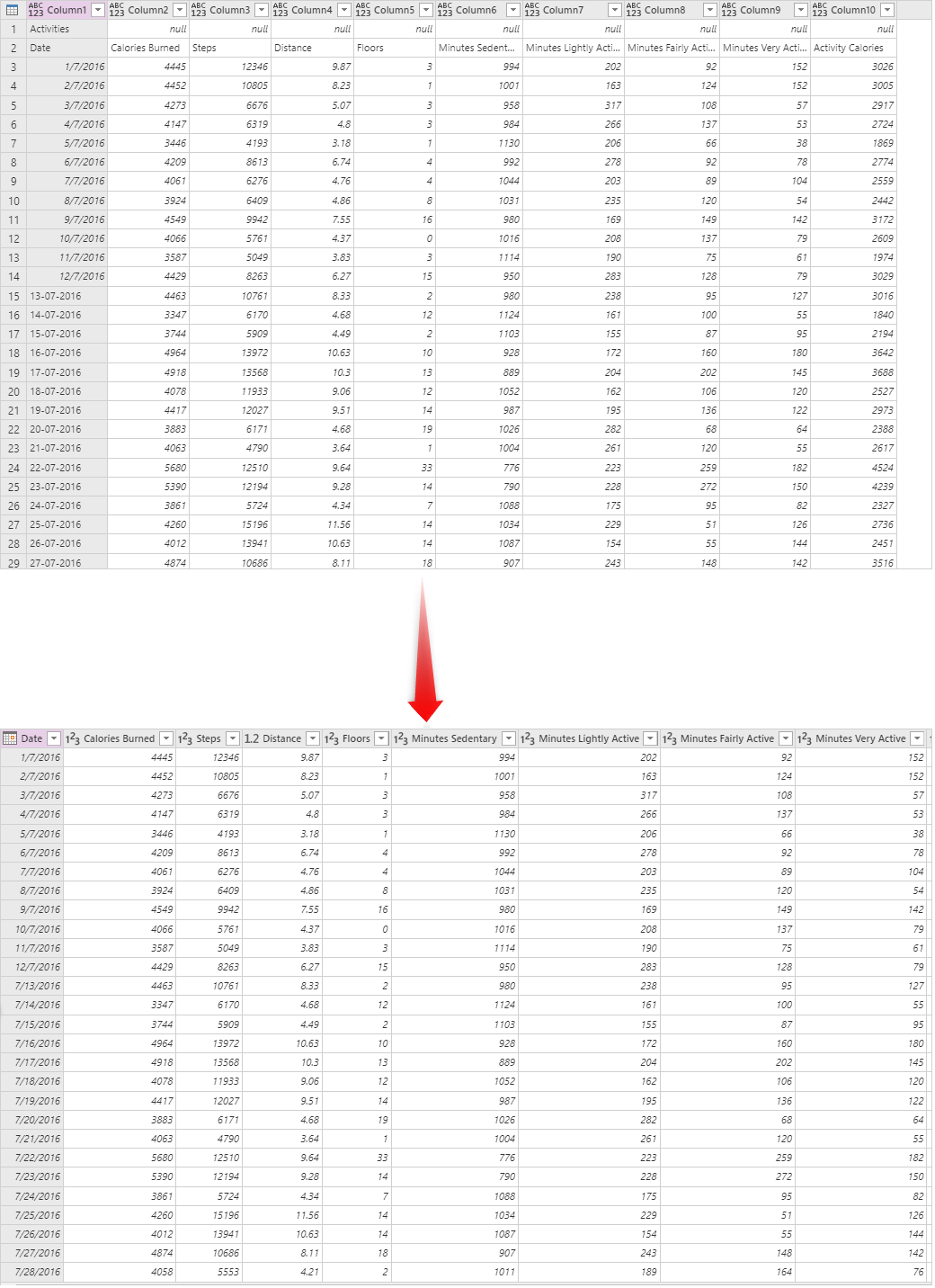
複数の Excel ファイルからデータを取得する場合、Power Query の [ ファイルの結合 ] オプションを使用すると、すべてのデータが自動的に追加され、出力は次の図のようになります。
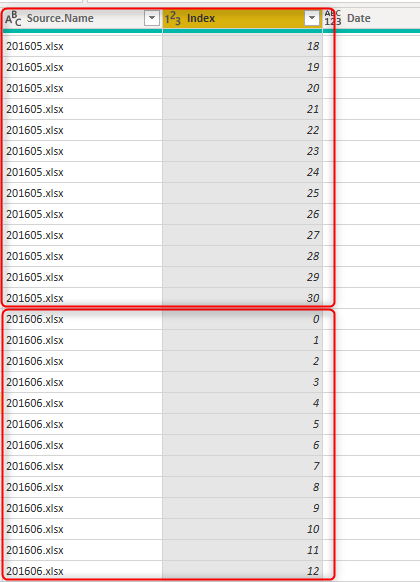
前の図に示すように、追加結果に加えて、Power Query はファイル名を含む Source.Name 列も取り込みます。 各ファイルのインデックス値は一意である可能性がありますが、複数のファイル間で一意ではありません。 ただし、Index 列と Source.Name 列の組み合わせは一意の組み合わせです。 このシナリオの複合代替キーを選択します。
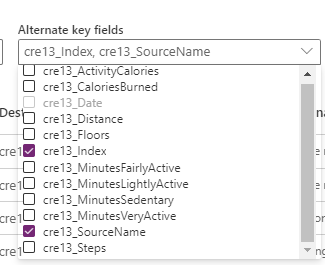
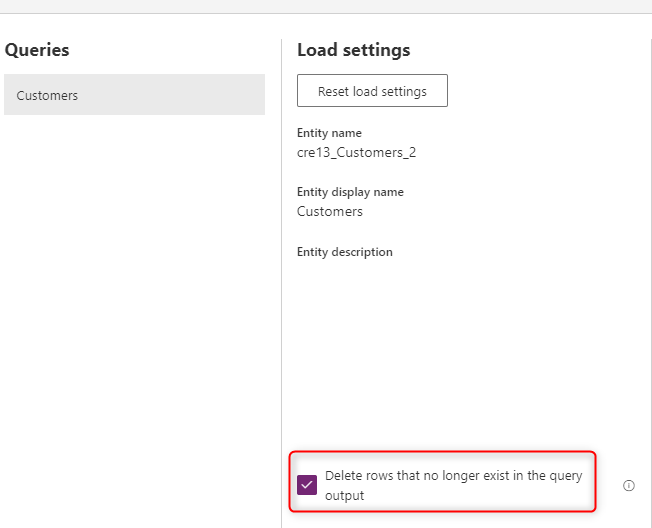
クエリ出力に存在しなくなった行を削除する
最後の手順では、 クエリ出力に存在しなくなった行の削除を選択します。 このオプションでは、Dataverse テーブル内のデータと、代替キー (複合キー) に基づいてソースから取得されたデータを比較し、存在しなくなった行を削除します。 その結果、Dataverse 内のデータは常にデータ ソースと同期されます。