TripPin パート 5 - ページング
このマルチパート チュートリアルでは、Power Query 用の新しいデータ ソース拡張機能の作成について説明します。 このチュートリアルは順番に実行することを目的としています。各レッスンは前のレッスンで作成したコネクタに基づいて構築され、コネクタに新しい機能が段階的に追加されます。
このレッスンの内容:
- コネクタにページング サポートを追加する
多くの REST API では "ページ" でデータを返します。これにより、クライアントで複数の要求を行って結果を結合する必要があります。 改ページには一般的な規則 (RFC 5988 など) がいくつかありますが、通常は API によって異なります。 幸い、TripPin は OData サービスであり、OData 標準によって、応答の本文で返される odata.nextLink 値を使用して改ページの方法が定義されます。
コネクタの以前のイテレーションを簡略化するために、TripPin.Feed 関数はページ対応ではありませんでした。 単に、要求から返された JSON を解析し、それをテーブルとして書式設定していました。 OData プロトコルに慣れている方は、応答の形式 (レコードの配列を含む value フィールドがあると仮定するなど) に対して、いくつかの誤った仮定が行われていることに気付いたかもしれません。
このレッスンでは、ページ対応にすることで、応答処理ロジックを改善します。 今後のチュートリアルでは、ページ処理ロジックがより堅牢になり、複数の応答形式 (サービスからのエラーを含む) を処理できるようになります。
Note
OData.Feed に基づくコネクタを使用して独自のページング ロジックを実装する必要はありません。これは、すべて自動的に処理されるためです。
ページングのチェックリスト
ページング サポートを実装する場合は、API に関して次の点を把握しておく必要があります。
- データの次のページを要求する方法
- ページング メカニズムに値の計算が含まれているか、応答から次のページの URL を抽出するか
- ページングを停止するタイミングを確認する方法
- 認識しておく必要があるページングに関連するパラメーターはあるか ("ページ サイズ" など)
これらの質問に対する答えは、ページング ロジックの実装方法に影響します。 ページングの実装間では、いくつかのコードを再利用できますが (Table.GenerateByPage の使用など)、ほとんどのコネクタではカスタム ロジックが必要になります。
Note
このレッスンには、特定の形式に従った OData サービスのページング ロジックが含まれます。 API のドキュメントを参照して、コネクタでページング形式をサポートするために必要な変更を判断してください。
OData ページングの概要
OData ページングは、応答ペイロード内に含まれる nextLink 注釈によって決定されます。 nextLink 値には、データの次のページへの URL が含まれています。 応答で最も外側にあるオブジェクトの odata.nextLink フィールドを検索することによって、別のデータ ページがあるかどうかを確認できます。 odata.nextLink フィールドがない場合は、すべてのデータが読み取られます。
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
OData サービスによっては、クライアントで最大ページ サイズの設定を提供できる場合がありますが、それを受け入れるかどうかは、サービスによって異なります。 Power Query はあらゆるサイズの応答を処理できる必要があるため、ページ サイズの設定について心配する必要はありません。サービスがスローするものはすべてサポートできます。
サーバードリブン ページングの詳細については、OData 仕様を参照してください。
TripPin のテスト
ページング実装を修正する前に、前のチュートリアルから、拡張機能の現在の動作を確認します。 次のテスト クエリによって、People テーブルが取得され、現在の行数を表示するためのインデックス列が追加されます。
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Fiddler を有効にして、Power Query SDK でクエリを実行します。 このクエリでは、8 行 (インデックス 0 から 7) のテーブルが返されることに注意してください。
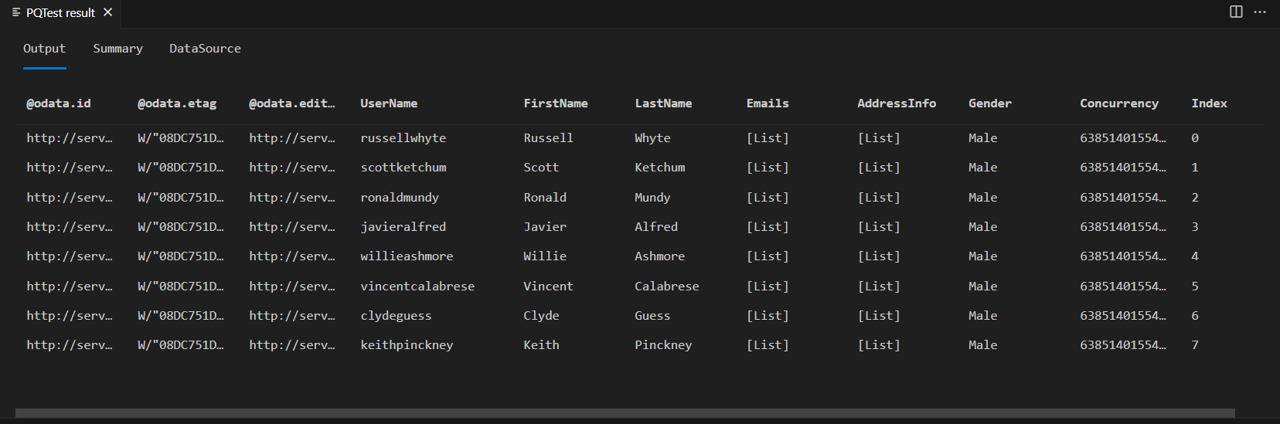
Fiddler からの応答の本文を確認すると、実際には、使用可能なデータのページがさらにあることを示す @odata.nextLink フィールドが含まれていることがわかります。
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
TripPin のページングの実装
ここで、拡張機能に次の変更を加えます。
- 共通関数
Table.GenerateByPageをインポートします Table.GenerateByPageを使用するGetAllPagesByNextLink関数を追加してすべてのページを連結します- 1 ページのデータを読み取ることができる
GetPage関数を追加します - 応答から次の URL を抽出する
GetNextLink関数を追加します - 新しいページ リーダー関数を使用するように
TripPin.Feedを更新します
Note
このチュートリアルで既に説明したように、ページング ロジックはデータ ソースによって異なります。 ここでの実装では、応答で返された 次のリンク を使用するソースに対して再利用できるように、ロジックを関数に分割します。
Table.GenerateByPage
ソースから返された (潜在的に) 複数のページを 1 つのテーブルに結合するには、Table.GenerateByPage を使用します。 この関数は引数として getNextPage 関数を受け取ります。この関数は、その名前が示すとおり、データの次のページをフェッチすることを実行します。 Table.GenerateByPage は繰り返し getNextPage関数を呼び出し、そのたびに最後に呼び出したときに生成された結果を渡します。その後、利用可能なページがもうないことを知らせるためにnull を返します。
この関数は Power Query の標準ライブラリの一部ではないため、そのソース コードを .pq ファイルにコピーする必要があります。
GetAllPagesByNextLink の実装
GetAllPagesByNextLink 関数の本体では、Table.GenerateByPage の getNextPage 関数引数が実装されます。 GetPage 関数が呼び出され、前の呼び出しの meta レコードの NextLink フィールドから、データの次のページの URL が取得されます。
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
GetPage の実装
GetPage 関数では、Web.Contents を使用して TripPin サービスから 1 ページのデータを取得し、応答をテーブルに変換します。 Web.Contents からの応答を GetNextLink 関数に渡して、次のページの URL を抽出し、返されたテーブル (データのページ) の meta レコードに設定します。
この実装は、前のチュートリアルからの TripPin.Feed 呼び出しの少し変更されたバージョンです。
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
GetNextLink の実装
GetNextLink 関数では、単に @odata.nextLink フィールドの応答の本文をチェックし、その値を返します。
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
まとめ
ページング ロジックを実装する最後の手順は、新しい関数を使用するために TripPin.Feed を更新することです。 ここでは、GetAllPagesByNextLink を呼び出すだけですが、以降のチュートリアルでは、新しい機能 (スキーマの適用やパラメーター ロジックのクエリなど) を追加します。
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
チュートリアルで前述したものと同じテスト クエリを再実行すると、ページ リーダーが動作していることがわかります。 応答に 8 行ではなく、24 行あることもわかります。
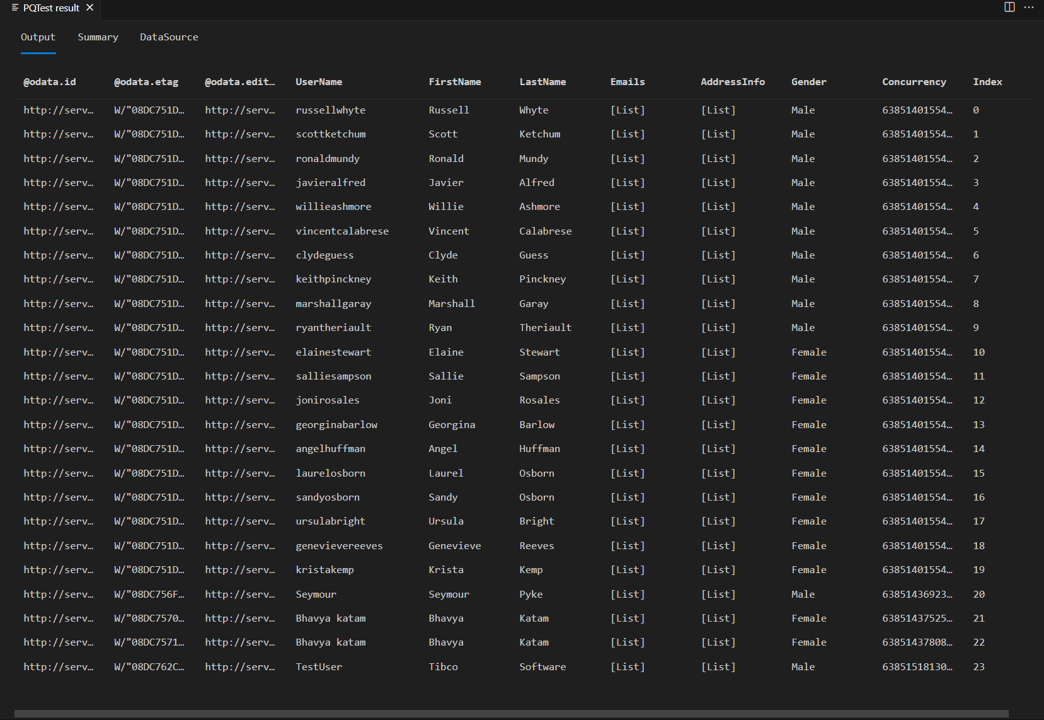
Fiddler の要求を確認すると、データの各ページに対して個別の要求が表示されるようになります。
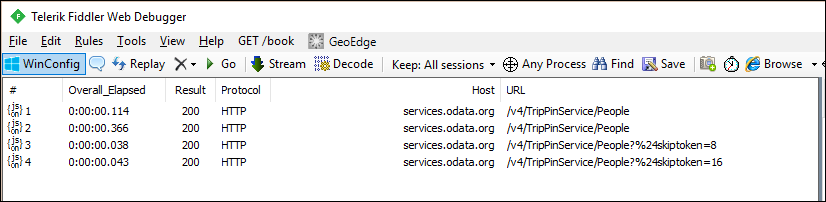
Note
サービスからのデータの最初のページに対して重複する要求があることがわかりますが、これは理想的ではありません。 余分な要求は、M エンジンのスキーマチェック動作の結果です。 現時点ではこの問題を無視し、次のチュートリアルで明示的なスキーマを適用して解決します。
まとめ
このレッスンでは、REST API の改ページ サポートを実装する方法を説明しました。 ロジックは API によって異なる可能性がありますが、ここで確立されたパターンは、わずかな変更で再利用できます。
次のレッスンでは、明示的なスキーマをデータに適用する方法について説明します。これは、Json.Document から取得される単純な text および number データ型を超えています。