バックグラウンド
現在、AI モデルはより大きくなっていくにつれて進化しており、効率的なモデル トレーニングのために高度なハードウェアとコンピューターのクラスターに対する需要が高まっています。 HPC Pack を使用すると、モデルのトレーニング作業を効果的に簡略化できます。
PyTorch 分散データ並列 (別名 DDP)
分散モデル トレーニングを実装するには、分散トレーニング フレームワークを利用する必要があります。 フレームワークの選択は、モデルの構築に使用されるフレームワークによって異なります。 この記事では、HPC Pack で PyTorch を続行する方法について説明します。
PyTorch には、分散トレーニングのためのいくつかの方法が用意されています。 これらの中で、分散データ並列 (DDP) は、現在の単一マシン トレーニング モデルに必要なシンプルさと最小限のコード変更により、広く好まれています。
AI モデル トレーニング用に HPC Pack クラスターをセットアップする
ローカル コンピューターまたは Azure 上の仮想マシン (VM) を使用して HPC Pack クラスターをセットアップできます。 これらのコンピューターに GPU が装備されていることを確認してください (この記事では、Nvidia GPU を使用します)。
通常、1 つの GPU は、分散トレーニング作業に対して 1 つのプロセスを持つことができます。 そのため、2 台のコンピューター (コンピューター クラスター内のノードとも呼ばれる) がある場合は、それぞれ 4 つの GPU を搭載し、1 つのモデル トレーニングで 8 に相当する 2 * 4 の並列プロセスを実現できます。 この構成により、1 回のプロセス トレーニングと比較してトレーニング時間が約 1/8 に短縮される可能性があります。これにより、プロセス間でデータを同期するオーバーヘッドを省略できます。
ARM テンプレートで HPC Pack クラスターを作成する
わかりやすくするために、GitHubの ARM テンプレート
テンプレート "Linux ワークロード用の単一ヘッド ノード クラスター" を選択し、[Azure へのデプロイ] をクリックします
ARM テンプレート を選択
また、HPC Pack を使用するために証明書を作成してアップロードする方法については、前提条件の を参照してください。
注意:
"HPC" でマークされたコンピューティング ノード イメージを選択する必要があります。 これは、GPU ドライバーがイメージにプレインストールされていることを示します。 これを行わないと、後の段階でコンピューティング ノードに GPU ドライバーを手動でインストールする必要があります。これは、GPU ドライバーのインストールが複雑なため、困難な作業になる可能性があります。 HPC イメージの詳細については、
こちらを参照してください。 HPC ノード イメージ を選択
GPU を使用してコンピューティング ノードの VM サイズを選択する必要があります。 これは、N シリーズの VM サイズ
です。 GPU を使用して VM サイズを選択
コンピューティング ノードに PyTorch をインストールする
各コンピューティング ノードで、コマンドを使用して PyTorch をインストールします
pip3 install torch torchvision torchaudio
ヒント: HPC Pack の "コマンドの実行" を利用して、一連のクラスター ノード間で並列でコマンドを実行できます。
共有ディレクトリをセットアップする
トレーニング ジョブを実行する前に、すべてのコンピューティング ノードからアクセスできる共有ディレクトリが必要です。 ディレクトリは、コードとデータ (入力データ セットと出力トレーニング済みモデルの両方) のトレーニングに使用されます。
ヘッド ノードに SMB 共有ディレクトリをセットアップし、次のように cifs を使用して各コンピューティング ノードにマウントできます。
ヘッド ノードで、
%CCP_DATA%\SpoolDirの下にディレクトリappを作成します。これは、既定で HPC Pack によってCcpSpoolDirとして既に共有されています。コンピューティング ノードで、次のように
appディレクトリをマウントします。sudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777手記:
- 対話型シェルでは、
passwordオプションを省略できます。 その場合は、入力を求められます。 -
dir_modeとfile_modeは 0777 に設定されているため、すべての Linux ユーザーが読み取り/書き込みを行うことができます。 制限付きアクセス許可が可能ですが、構成が複雑になります。
- 対話型シェルでは、
必要に応じて、
/etc/fstabに線を追加して、マウントを永続的に行います。//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2ここでは、
passwordが必要です。
トレーニング ジョブを実行する
2 つの Linux コンピューティング ノードがあり、それぞれに 4 つの NVidia v100 GPU があるとします。 また、各ノードに PyTorch をインストールしました。 また、共有ディレクトリ "app" もセットアップしています。 これで、トレーニング作業を開始できます。
ここでは、PyTorch DDP 上に構築されたシンプルなおもちゃモデルを使用しています。 GitHubでコードを
ヘッド ノード上の共有ディレクトリ %CCP_DATA%\SpoolDir\app に次のファイルをダウンロードします
- neural_network.py
- operations.py
- run_ddp.py
次に、リソースユニットとして Node を使用し、ジョブ用に 2 つのノードを持つジョブを作成します 。次に例を示します。
ジョブの詳細 を
GPU を使用して 2 つのノードを明示的に指定します(例:
ジョブ リソースの選択 を
次に、次のようにジョブ タスクを追加します。
ジョブ タスク 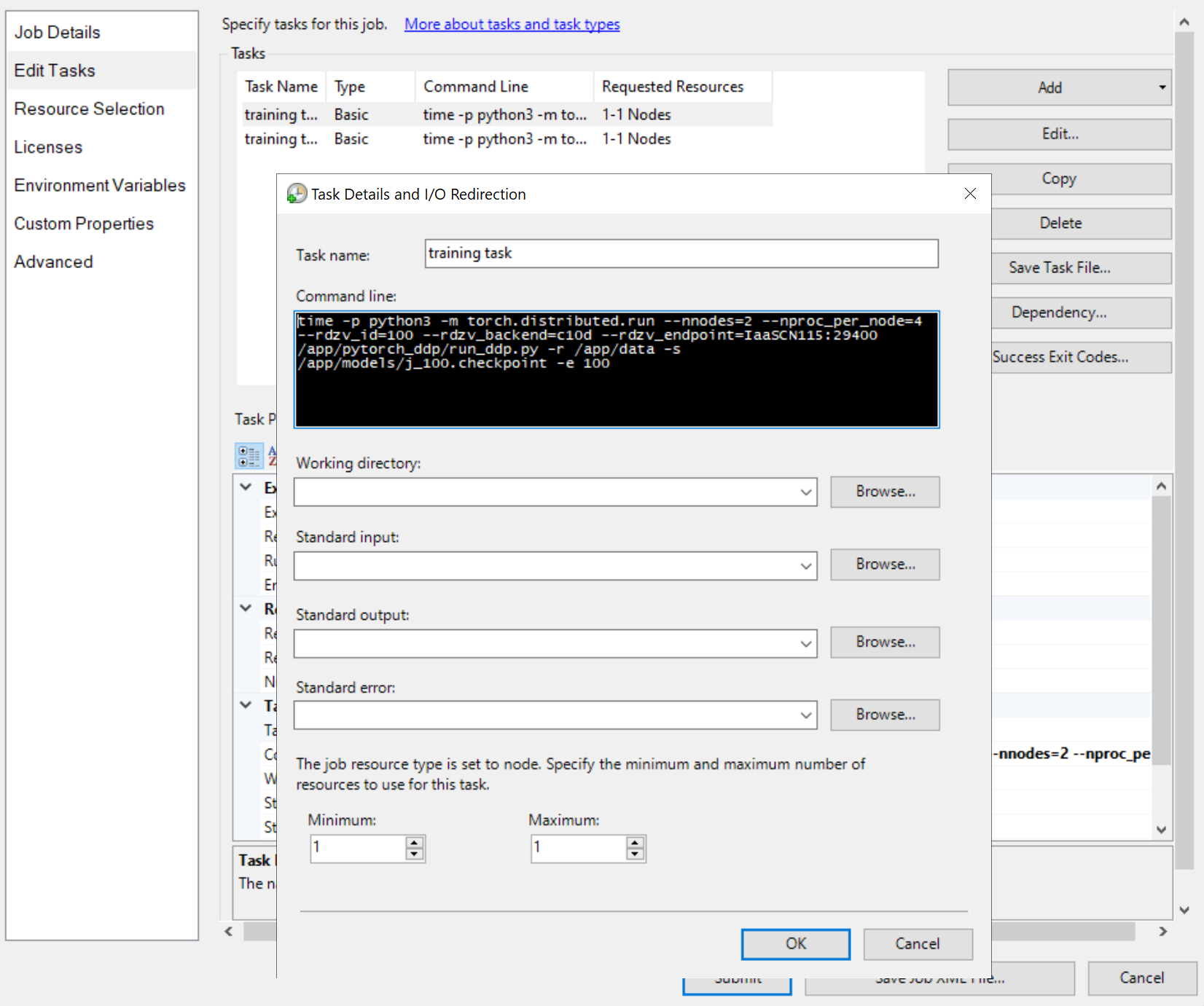
タスクのコマンド ラインはすべて同じです。
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesは、トレーニング ジョブのコンピューティング ノードの数を指定します。 -
nproc_per_nodeは、各コンピューティング ノード上のプロセスの数を指定します。 ノード上の GPU の数を超えすることはできません。 つまり、1 つの GPU に最大で 1 つのプロセスを含めることができます。 -
rdzv_endpointは、ランデブーとして機能するノードの名前とポートを指定します。 トレーニング ジョブ内の任意のノードが機能します。 - "/app/run_ddp.py" は、トレーニング コード ファイルへのパスです。
/appはヘッド ノード上の共有ディレクトリであることを忘れないでください。
ジョブを送信し、結果を待ちます。 次のように、実行中のタスクを表示できます。
ジョブ タスク を表示
長すぎる場合は、結果ペインに切り捨てられた出力が表示されることに注意してください。
これで問題が発生します。 私はあなたがポイントを取得し、HPC Packがあなたのトレーニング作業をスピードアップできることを願っています。