重要
2021 年 7 月 1 日以降、既存のワークスペースに新しいテストを追加したり、Network Performance Monitor で新しいワークスペースを有効にしたりできなくなります。 2021 年 7 月 1 日より前に作成されたテストは引き続き使用できます。 現在のワークロードに対するサービスの中断を最小限に抑えるには、2024 年 2 月 29 日より前に、テストを Network Performance Monitor から Azure Network Watcher の新しい接続モニター に移行。
Network Performance Monitor のパフォーマンス モニター機能は、ネットワーク内のさまざまなポイント間のネットワーク接続を監視するのに役立ちます。 クラウドのデプロイとオンプレミスの場所、複数のデータ センターとブランチ オフィス、ミッション クリティカルな多層アプリケーションまたはマイクロサービスを監視できます。 パフォーマンス モニターを使用すると、ユーザーが不平を言う前にネットワークの問題を検出できます。 主な利点は、次のことができることです。
- さまざまなサブネット間の損失と待機時間を監視し、アラートを設定します。
- ネットワーク上のすべてのパス (冗長パスを含む) を監視する。
- レプリケートが困難な一時的および特定の時点のネットワークの問題をトラブルシューティングします。
- パフォーマンスの低下を担当するネットワーク上の特定のセグメントを決定します。
- SNMP を必要とせずに、ネットワークの正常性を監視します。

コンフィギュレーション
Network Performance Monitor の構成を開くには、 Network Performance Monitor ソリューションを開き、[構成] を選択 します。
新しいネットワークを作成する
Network Performance Monitor のネットワークは、サブネットの論理コンテナーです。 これは、ニーズに応じてネットワーク インフラストラクチャの監視を整理するのに役立ちます。 フレンドリ名を使用してネットワークを作成し、ビジネス ロジックに従ってサブネットを追加できます。 たとえば、London という名前のネットワークを作成し、ロンドン のデータ センターにすべてのサブネットを追加できます。 または、 ContosoFrontEnd という名前のネットワークを作成し、アプリのフロントエンドを提供する Contoso という名前のすべてのサブネットをこのネットワークに追加できます。 ソリューションは、環境内で検出されたすべてのサブネットを含む既定のネットワークを自動的に作成します。
ネットワークを作成するたびに、そのネットワークにサブネットを追加します。 その後、そのサブネットは既定のネットワークから削除されます。 ネットワークを削除すると、そのすべてのサブネットが既定のネットワークに自動的に返されます。 既定のネットワークは、ユーザー定義ネットワークに含まれていないすべてのサブネットのコンテナーとして機能します。 既定のネットワークを編集または削除することはできません。 常にシステムに残ります。 必要な数のカスタム ネットワークを作成できます。 ほとんどの場合、組織内のサブネットは複数のネットワークに配置されます。 ビジネス ロジックのサブネットをグループ化する 1 つ以上のネットワークを作成します。
新しいネットワークを作成するには:
- [ ネットワーク ] タブを選択します。
- [ ネットワークの追加] を選択し、ネットワーク名と説明を入力します。
- 1 つ以上のサブネットを選択し、[ 追加] を選択します。
- 保存 を選択して、コンフィギュレーションを保存します。
監視ルールを作成する
パフォーマンス モニターは、2 つのサブネットワーク間または 2 つのネットワーク間のネットワーク接続のパフォーマンスのしきい値に違反すると、正常性イベントを生成します。 システムは、これらのしきい値を自動的に学習できます。 カスタムしきい値を指定することもできます。 システムは既定のルールを自動的に作成します。このルールは、ネットワークまたはサブネットワーク リンクのペア間の損失または待機時間がシステム学習のしきい値を超えるたびに正常性イベントを生成します。 このプロセスは、監視ルールを明示的に作成しない限り、ソリューションがネットワーク インフラストラクチャを監視するのに役立ちます。 既定のルールが有効になっている場合、すべてのノードは、監視を有効にした他のすべてのノードに代理トランザクションを送信します。 既定のルールは、小規模なネットワークで役立ちます。 たとえば、マイクロサービスを実行するサーバーの数が少なく、すべてのサーバーが相互に接続できることを確認するシナリオがあります。
注
既定のルールを無効にし、カスタム監視ルールを作成することをお勧めします。特に、監視に多数のノードを使用する大規模なネットワークの場合です。 カスタム監視ルールは、ソリューションによって生成されるトラフィックを減らし、ネットワークの監視を整理するのに役立ちます。
ビジネス ロジックに従って監視ルールを作成します。 たとえば、本社への 2 つのオフィス サイトのネットワーク接続のパフォーマンスを監視する場合です。 ネットワーク O1 の Office site1 内のすべてのサブネットをグループ化します。 次に、Office site2 のすべてのサブネットをネットワーク O2 にグループ化します。 最後に、ネットワーク H 内の本社内のすべてのサブネットをグループ化します。2 つの監視ルールを作成します。1 つは O1 と H の間、もう 1 つは O2 と H の間です。
カスタム監視ルールを作成するには:
- [監視] タブで [ルールの追加] を選択し、ルールの名前と説明を入力します。
- 一覧から監視するネットワーク リンクまたはサブネットワーク リンクのペアを選択します。
- ネットワーク ドロップダウン リストから、必要なサブネットワークを含むネットワークを選択します。 次に、対応するサブネットワーク ドロップダウン リストからサブネットワークを選択します。 ネットワーク リンク内のすべてのサブネットワークを監視する場合は、[ すべてのサブネットワーク] を選択します。 同様に、必要な他のサブネットワークを選択します。 特定のサブネットワーク リンクの監視を選択から除外するには、[例外の 追加] を選択します。
- 代理トランザクションを実行する ICMP プロトコルと TCP プロトコルを選択します。
- 選択した項目の正常性イベントを作成しない場合は、 このルールの対象となるリンクで [正常性の監視を有効にする] をオフにします。
- 監視条件を選択します。 正常イベント生成用のカスタムしきい値を設定するには、しきい値を入力します。 条件の値が、選択したネットワークまたはサブネットワーク のペアに対して選択したしきい値を超えると、正常性イベントが生成されます。
- 保存 を選択して、コンフィギュレーションを保存します。
監視ルールを保存したら、[アラートの作成] を選択して、そのルールを アラート管理と統合できます。 アラート ルールは、検索クエリを使用して自動的に作成されます。 その他の必須パラメーターが自動的に入力されます。 アラート ルールを使用すると、ネットワーク パフォーマンス モニター内の既存のアラートに加えて、電子メール ベースのアラートを受信できます。 アラートは、Runbook で修復アクションをトリガーすることも、Webhook を使用して既存のサービス管理ソリューションと統合することもできます。 [ アラートの管理 ] を選択してアラート設定を編集します。
パフォーマンス モニターのルールをさらに作成したり、ソリューション ダッシュボードに移動して機能を使用したりできるようになりました。
プロトコルの選択
Network Performance Monitor は代理トランザクションを使用して、パケット損失やリンク待機時間などのネットワーク パフォーマンス メトリックを計算します。 この概念をよりよく理解するには、ネットワーク リンクの一方の端に接続されている Network Performance Monitor エージェントを検討してください。 この Network Performance Monitor エージェントは、ネットワークの別の端に接続されている 2 つ目の Network Performance Monitor エージェントにプローブ パケットを送信します。 2 番目のエージェントは応答パケットで応答します。 このプロセスは数回繰り返されます。 応答の数と各応答の受信にかかる時間を測定することで、最初の Network Performance Monitor エージェントはリンクの待機時間とパケットのドロップを評価します。
これらのパケットの形式、サイズ、およびシーケンスは、監視ルールを作成するときに選択するプロトコルによって決まります。 パケットのプロトコルに基づいて、ルーターやスイッチなどの中間ネットワーク デバイスがこれらのパケットを異なる方法で処理する場合があります。 その結果、プロトコルの選択は結果の精度に影響します。 プロトコルの選択によって、Network Performance Monitor ソリューションを展開した後に手動で手順を実行する必要があるかどうかも決まります。
Network Performance Monitor では、代理トランザクションを実行するための ICMP プロトコルと TCP プロトコルを選択できます。 代理トランザクション ルールの作成時に ICMP を選択した場合、ネットワーク パフォーマンス モニター エージェントは ICMP ECHO メッセージを使用してネットワーク待機時間とパケット損失を計算します。 ICMP ECHO は、従来の ping ユーティリティによって送信されるのと同じメッセージを使用します。 プロトコルとして TCP を使用すると、ネットワーク パフォーマンス モニター エージェントはネットワーク経由で TCP SYN パケットを送信します。 この手順の後に TCP ハンドシェイクが完了し、RST パケットを使用して接続が削除されます。
プロトコルを選択する前に、次の情報を考慮してください。
複数のネットワーク ルートの検出。 TCP は複数のルートを検出する場合の精度が高く、各サブネットで必要なエージェントが少なくなります。 たとえば、TCP を使用する 1 つまたは 2 つのエージェントは、サブネット間のすべての冗長パスを検出できます。 同様の結果を得るには、ICMP を使用するいくつかのエージェントが必要です。 ICMP を使用すると、2 つのサブネット間に多数のルートがある場合は、ソースサブネットまたは宛先サブネットに 5N を超えるエージェントが必要です。
結果の精度。 ルーターとスイッチは、TCP パケットと比較して ICMP ECHO パケットに割り当てる優先順位が低くなる傾向があります。 特定の状況では、ネットワーク デバイスが頻繁に読み込まれると、TCP によって取得されたデータは、アプリケーションによって発生する損失と待機時間をより厳密に反映します。 これは、ほとんどのアプリケーション トラフィックが TCP 経由で流れるからです。 このような場合、ICMP は TCP と比較して精度の低い結果を提供します。
ファイアウォールの構成: TCP プロトコルでは、TCP パケットが宛先ポートに送信される必要があります。 Network Performance Monitor エージェントで使用される既定のポートは 8084 です。 エージェントを構成するときにポートを変更できます。 ネットワーク ファイアウォールまたはネットワーク セキュリティ グループ (NSG) 規則 (Azure) でポート上のトラフィックが許可されていることを確認します。 また、エージェントがインストールされているコンピューター上のローカル ファイアウォールがこのポートでトラフィックを許可するように構成されていることを確認する必要もあります。 PowerShell スクリプトを使用して、Windows を実行しているコンピューターでファイアウォール規則を構成できますが、ネットワーク ファイアウォールを手動で構成する必要があります。 これに対し、ICMP はポートを使用して動作しません。 ほとんどのエンタープライズ シナリオでは、ping ユーティリティなどのネットワーク診断ツールを使用できるように、ファイアウォール経由で ICMP トラフィックが許可されます。 あるマシンから別のマシンに ping を実行できる場合は、ファイアウォールを手動で構成しなくても ICMP プロトコルを使用できます。
注
一部のファイアウォールでは ICMP がブロックされ、再送信が発生し、セキュリティ情報とイベント管理システムで多数のイベントが発生する可能性があります。 選択したプロトコルがネットワーク ファイアウォールまたは NSG によってブロックされていないことを確認します。 それ以外の場合、ネットワーク パフォーマンス モニターはネットワーク セグメントを監視できません。 監視には TCP を使用することをお勧めします。 次のような TCP を使用できないシナリオでは、ICMP を使用します。
- Windows クライアントでは TCP 生ソケットが許可されていないため、Windows クライアント ベースのノードを使用します。
- ネットワーク ファイアウォールまたは NSG によって TCP がブロックされます。
- プロトコルを切り替える方法がわからない。
デプロイ中に ICMP を使用することを選択した場合は、既定の監視規則を編集することでいつでも TCP に切り替えることができます。
- ネットワーク パフォーマンス>Monitor>Configure>Monitor に移動します。 次に、[ 既定の規則] を選択します。
- [ プロトコル ] セクションまでスクロールし、使用するプロトコルを選択します。
- [保存] を選んで変更を適用します。
既定の規則で特定のプロトコルが使用されている場合でも、別のプロトコルで新しい規則を作成できます。 一部のルールでは ICMP を使用し、他のルールでは TCP を使用するルールを組み合わせて作成することもできます。
ウォークスルー
健康イベントの根本原因を簡単に見てみます。
ソリューション ダッシュボードの正常性イベントには、ネットワーク リンクが異常であることが示されます。 問題を調査するには、[ 監視対象のネットワーク リンク ] タイルを選択します。
ドリルダウン ページには、 DMZ2-DMZ1 ネットワーク リンクが異常であることが示されています。 ネットワークリンクのサブネットリンクを表示を選択します。
ドリルダウン ページには、 DMZ2-DMZ1 ネットワーク リンク内のすべてのサブネットワーク リンクが表示されます。 両方のサブネットワーク リンクの待機時間がしきい値を超えたため、ネットワーク リンクが異常になります。 また、両方のサブネットワーク リンクの待機時間の傾向を確認することもできます。 グラフの時間選択コントロールを使用して、必要な時間範囲に注目します。 待機時間がピークに達した時刻を確認できます。 この期間の後でログを検索して、問題を調査します。 [ ノード リンクの表示 ] を選択して、さらにドリルダウンします。
![[サブネットワーク リンク] ページ](media/network-performance-monitor-performance-monitor/subnetwork-links.png)
前のページと同様に、特定のサブネットワーク リンクのドリルダウン ページには、その構成ノード リンクが一覧表示されます。 前の手順と同様のアクションをここで実行できます。 [ トポロジの表示] を選択して、2 つのノード間のトポロジを表示します。
![[ノード リンク] ページ](media/network-performance-monitor-performance-monitor/node-links.png)
選択した 2 つのノード間のすべてのパスがトポロジ マップにプロットされます。 トポロジ マップ上の 2 つのノード間のルートのホップバイホップ トポロジを視覚化できます。 2 つのノード間に存在するルートの数と、データ パケットが実行するパスを明確に把握できます。 ネットワーク パフォーマンスのボトルネックが赤色で表示されます。 障害のあるネットワーク接続または障害のあるネットワーク デバイスを見つけるには、トポロジ マップ上の赤い要素を確認します。
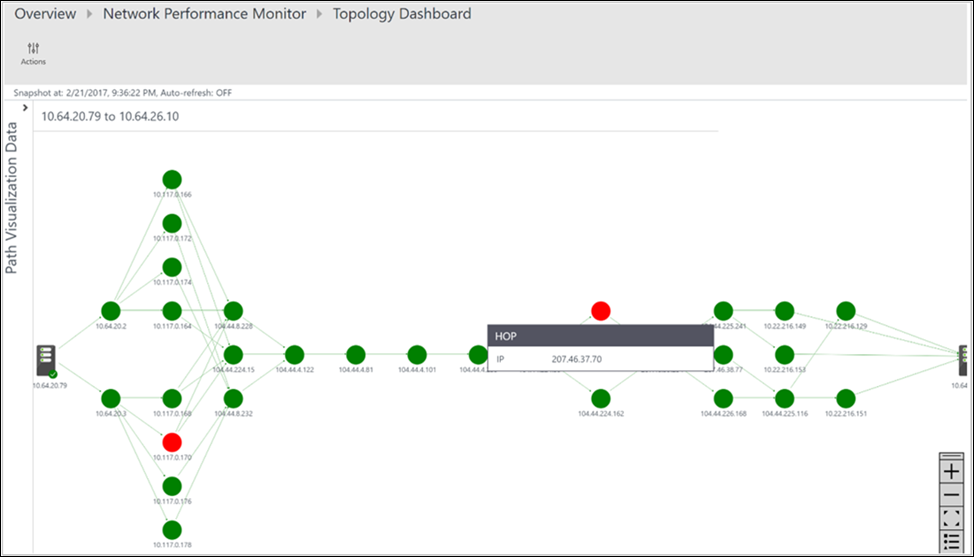
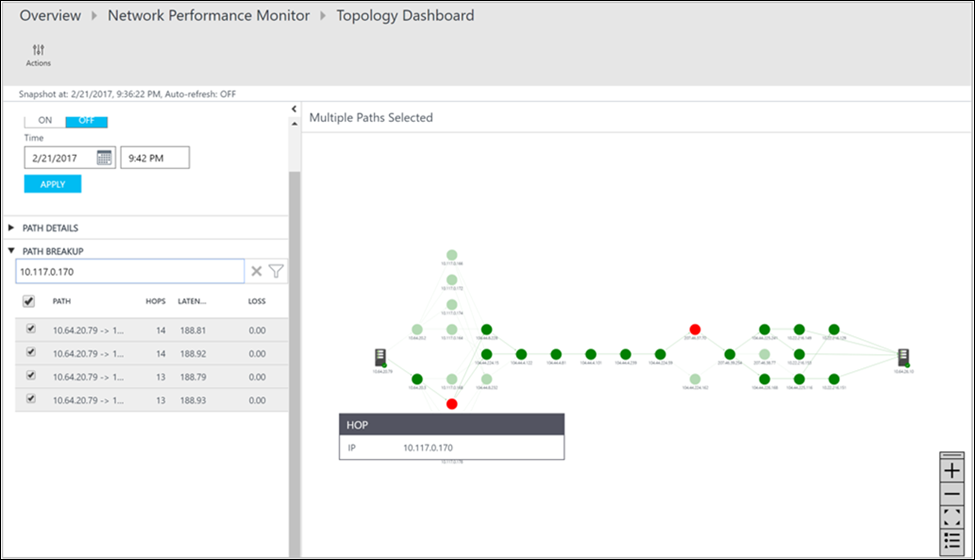
[操作] ウィンドウで、各パスの損失、待機時間、およびホップ数を確認できます。 異常なパスの詳細を表示するには、スクロール バーを使用します。 選択したパスのみのトポロジがプロットされるように、フィルターを使用して異常ホップを含むパスを選択します。 トポロジ マップを拡大または縮小するには、マウス ホイールを使用します。
次の図では、ネットワークの特定のセクションに対する問題領域の根本原因が赤いパスとホップに表示されます。 トポロジ マップ内のノードを選択して、FQDN と IP アドレスを含むノードのプロパティを表示します。 ホップを選択すると、ホップの IP アドレスが表示されます。
次のステップ
ログを検索 して、詳細なネットワーク パフォーマンス データ レコードを表示します。