チュートリアル:Azure Machine Learning と IoT Edge を使用したエンド ツー エンド ソリューション
適用対象: ![]() IoT Edge 1.1
IoT Edge 1.1
重要
IoT Edge 1.1 のサポート終了日は、2022 年 12 月 13 日でした。 本製品、サービス、テクノロジ、または API のサポート内容については、Microsoft 製品のライフサイクルに関するページをご確認ください。 最新バージョンの IoT Edge への更新の詳細については、「 Update IoT Edge」を参照してください。
IoT アプリケーションでインテリジェント クラウドやインテリジェント エッジを利用したいことはよくあります。 このチュートリアルでは、クラウド内の IoT デバイスから収集されたデータを使用して機械学習モデルをトレーニングし、そのモデルを IoT Edge にデプロイし、さらにモデルを定期的に保守および改良する方法について説明します。
注意
この一連のチュートリアルの概念は IoT Edge のすべてのバージョンに適用されますが、シナリオを試すために作成したサンプル デバイスは、IoT Edge バージョン 1.1 で実行されます。
このチュートリアルの主な目的は、特にエッジ上で、機械学習を使用した IoT データの処理を導入することです。 一般的な機械学習ワークフローの多くの側面に触れていますが、このチュートリアルは、機械学習の詳細な解説を目的にしたものではありません。 ある時点では、ユース ケース用に高度に最適化されたモデルを作成しようとはしません。IoT データ処理に実行可能なモデルを作成して使用するプロセスを説明するのに十分です。
チュートリアルのこのセクションでは、以下のことについて説明します。
- チュートリアルの以降のパートを完了するための前提条件。
- チュートリアルの対象読者。
- チュートリアルによってシミュレートされるユース ケース。
- ユース ケースを実現するためにチュートリアルで実行するプロセス全体。
Azure サブスクリプションをお持ちでない場合は、開始する前に Azure 無料アカウントを作成してください。
前提条件
このチュートリアルを完了するには、リソースを作成する権限を持つ Azure サブスクリプションへのアクセス権が必要です。 このチュートリアルで使用されるサービスのいくつかでは Azure の料金が発生します。 まだ Azure サブスクリプションを持っていない場合は、Azure の無料アカウントで開始できる可能性があります。
また、Azure 仮想マシンを開発用コンピューターとして設定するスクリプトを実行できる PowerShell がインストールされたコンピューターも必要です。
このドキュメントでは、次の一連のツールを使用します。
データ キャプチャのための Azure IoT Hub
データ準備と機械学習の実験のためのメインのフロント エンドとしての Azure Notebooks。 サンプル データのサブセットに対してノートブックで Python コードを実行することは、データの準備中に反復的で、かつ対話型の高速なターンアラウンドを得るための素晴らしい方法です。 また、Jupyter ノートブックを使用すると、コンピューティング バックエンドで大規模に実行するスクリプトを準備することもできます。
大規模な機械学習や機械学習イメージの生成のためのバックエンドとしての Azure Machine Learning。 Jupyter ノートブックで準備およびテストされたスクリプトを使用して Azure Machine Learning バックエンドを促進します。
機械学習イメージのクラウド外アプリケーションのための Azure IoT Edge
当然、他のオプションも使用できます。 たとえば、特定のシナリオでは、IoT デバイスから初期のトレーニング データをキャプチャするためのコード不要の代替手段として IoT Central を使用できます。
対象読者と役割
この一連の記事は、これまでに IoT の開発または機械学習の経験がない開発者を対象にしています。 エッジに機械学習をデプロイするには、広範囲にわたるテクノロジを接続する方法に関する知識が必要です。 そのため、このチュートリアルには、これらのテクノロジを IoT ソリューションのために 1 つに結合する方法を示すエンド ツー エンドのシナリオ全体が含まれています。 実際の環境では、これらのタスクが、異なる専門分野を持つ複数人の間で分散される可能性があります。 たとえば、開発者がデバイスまたはクラウド コードのどちらかに重点を置くのに対して、データ サイエンティストは分析モデルを設計します。 個々の開発者がこのチュートリアルを正常に完了できるようにするために、何を、なぜ実行しようとしているかを理解するために十分な詳細情報への分析情報とリンクを含む補足的なガイダンスを用意しています。
あるいは、別の役割を持つ仕事仲間とチームを組んで一緒にチュートリアルに従ったり、完全な専門知識を生かしたり、物事をどのように組み合わせるかをチームとして学習したりすることもできます。
いずれの場合も、読者の理解に役立つように、このチュートリアルの各記事ではユーザーの役割を示しています。 これらの役割には次が含まれます。
- クラウド開発 (DevOps の容量で作業しているクラウド開発者を含む)
- データ分析
ユース ケース:予測的なメンテナンス
このシナリオは、2008 年の Conference on Prognostics and Health Management (PHM08) で提供されたユースケースに基づいて作成しました。 その目標は、1 組のターボファン航空機エンジンの残存耐用年数 (RUL) を予測することです。 このデータは、MAPSS (Modular Aero-Propulsion System Simulation) ソフトウェアの商用バージョンである C-MAPSS を使用して生成されました。 このソフトウェアは、正常性、制御、およびエンジン パラメーターを便利にシミュレートするための柔軟なターボファン エンジン シミュレーション環境を提供します。
このチュートリアルで使用されるデータは、ターボファン エンジンの劣化シミュレーション データ セットから取得されました。
readme ファイルより:
実験のシナリオ
データ セットは、複数の多変量時系列で構成されています。 各データ セットはさらに、トレーニングとテストのサブセットに分割されます。 各時系列は異なるエンジンからのデータです。つまり、データは同じ種類のエンジンのフリートからであると見なすことができます。 各エンジンには、最初からユーザーにはわからない、程度の異なる初期摩耗と製造のばらつきがあります。 この摩耗やばらつきは正常と見なされます。つまり、障害状態とは見なされません。 エンジンのパフォーマンスに大きな影響を与える 3 つの動作設定があります。 これらの設定もデータに含まれています。 データはセンサー ノイズで汚染されます。
エンジンは、各時系列の開始時には正常に動作しており、時系列中のある時点で障害を発生させます。 トレーニング セットでは、システム障害になるまでこの障害が深刻さを増します。 テスト セットでは、システム障害になる前のある時点で時系列が終了します。 競合の目的は、テスト セットでの障害の前の残りの動作サイクルの数、つまり、エンジンが引き続き動作する、最後のサイクルの後の動作サイクルの数を予測することです。 また、テスト データのための真の残存耐用年数 (RUL) 値のベクトルも用意されています。
このデータは競合のために公開されたため、機械学習モデルを導き出すためのいくつかのアプローチが独立に公開されています。 特定の機械学習モデルの作成に関連したプロセスや推論を理解するには、例の調査が有効であることがわかりました。 たとえば、次を参照してください。
GitHub ユーザー jancervenka による航空機エンジンの障害予測モデル。
GitHub ユーザー hankroark によるターボファン エンジンの劣化。
Process
次の図は、このチュートリアルで従う大まかな手順を示しています。
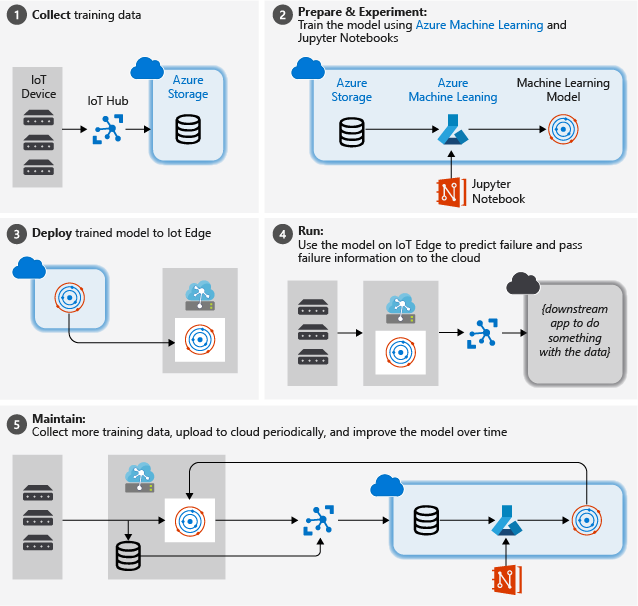
トレーニング データを収集する: このプロセスは、トレーニング データの収集で始まります。 データが既に収集され、データベースで、またはデータ ファイルの形式で使用可能になっている場合があります。 その他、特に IoT のシナリオでは、データを IoT デバイスやセンサーから収集し、クラウドに格納する必要がある場合もあります。
ターボファン エンジンのコレクションがないと仮定しているため、プロジェクト ファイルには、NASA デバイス データをクラウドに送信する単純なデバイス シミュレーターが含まれています。
データを準備する。 ほとんどの場合、デバイスやセンサーから収集された生データには機械学習のための準備が必要です。 この手順には、データのクリーンアップ、データの再フォーマット、または機械学習が識別できる追加情報を挿入するための前処理が含まれる場合があります。
航空機エンジン マシンのデータの場合、データを準備するには、データに対する実際の観察に基づいてサンプル内のデータ ポイントごとの障害までの明示的な時間を計算する必要があります。 この情報により、機械学習アルゴリズムは、エンジンの実際のセンサー データのパターンと予測される残存有効期間の間の相関関係を見つけることができます。 この手順は、高度にドメイン固有です。
機械学習モデルを構築する。 これで、準備されたデータに基づいて、モデルをトレーニングするための異なる機械学習アルゴリズムやパラメーター化で実験し、それらの結果を互いに比較できるようになりました。
この場合は、テストのために、モデルによって計算された予測される結果を 1 組のエンジンに対して観察された実際の結果と比較します。 Azure Machine Learning では、モデル レジストリ内に作成するモデルの異なるイテレーションを管理できます。
モデルをデプロイする。 成功の基準を満たすモデルが用意されたら、デプロイに移行できます。 それには、REST 呼び出しを使用してデータを指定すると分析結果を返すことができる Web サービス アプリにモデルをラッピングする必要があります。 その後、この Web サービス アプリは Docker コンテナーにパッケージ化され、これをさらにクラウド内に、または IoT Edge モジュールとしてデプロイできます。 この例では、IoT Edge へのデプロイに重点を置いています。
モデルを保守および改良する。 モデルがデプロイされたら、もう作業は実行されません。 多くの場合は、データの収集を続行し、そのデータをクラウドに定期的にアップロードします。 その後、このデータを使用してモデルを再トレーニングおよび改良し、次にそれを IoT Edge に再デプロイできます。
リソースをクリーンアップする
このチュートリアルはセットの一部であり、各記事は前の記事の作業が行われたことが前提になっています。 最後のチュートリアルを完了するまで、リソースのクリーンアップはしないでください。
次のステップ
このチュートリアルは、次のセクションに分かれています。
- 開発用コンピューターと Azure サービスを設定します。
- 機械学習モジュールのためのトレーニング データを生成します。
- 機械学習モジュールをトレーニングしてデプロイします。
- 透過的なゲートウェイとして機能するように IoT Edge デバイスを構成します。
- IoT Edge モジュールを作成してデプロイします。
- IoT Edge デバイスにデータを送信します。
開発用コンピューターを設定し、Azure リソースをプロビジョニングするには、次の記事に進んでください。