適用対象: Machine Learning Studio (クラシック)
Machine Learning Studio (クラシック)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
Machine Learning Studio (クラシック) で独自のデータを使用して予測分析ソリューションを開発し、トレーニングする場合、次の場所のデータを使用できます。
- ローカル ファイル - 事前にハード ドライブからローカル データを読み込み、ワークスペースにデータセット モジュールを作成します
- オンライン データ ソース - データのインポート モジュールを使用して、実験を実行している間に、いずれかのオンライン ソースのデータにアクセスします
- Machine Learning Studio (クラシック) の実験 - Machine Learning Studio (クラシック) にデータセットとして保存されたデータを使用します
- SQL Server データベース - 手動でデータをコピーせずに、SQL Server データベースのデータを使用します
注
Machine Learning Studio (クラシック) には、トレーニング データで使用できるさまざまなサンプル データセットが用意されています。 詳細については、「Machine Learning Studio (クラシック) におけるサンプル データセットの使用」を参照してください。
データを準備する
Machine Learning Studio (クラシック) は、区切られたテキスト データやデータベースからの構造化されたデータなど、四角形のデータや表形式のデータで作業するように設計されています。場合によっては、四角形以外のデータが使用されることもあります。
Studio (クラシック) にインポートする前に、比較的クリーンなデータを用意することをお勧めします。 たとえば、引用符で囲まれていない文字列などの問題に対処します。
ただし、Studio (クラシック) には、データをインポートした後に実験内でデータを操作できるモジュールが用意されています。 使用する機械学習アルゴリズムに応じて、値の欠落やスパース データなどのデータ構造上の問題を処理する際に、その対処方法を決定する必要があります。そのような場合に、これらのモジュールが役に立ちます。 これらの関数を実行するモジュールは、モジュール パレットの [Data Transformation] セクションで確認します。
実験中は、出力ポートをクリックすることで、モジュールで生成されたデータをいつでも表示またはダウンロードできます。 モジュールによっては、使用可能なダウンロードのオプションが異なる場合があります。また、Web ブラウザーのデータを Studio (クラシック) で視覚化できる場合もあります。
サポートされるデータ形式とデータ型
データのインポートに使用するメカニズムや、データの送信元に応じて、さまざまなデータ型を実験にインポートできます。
- プレーン テキスト (.txt)
- コンマ区切り値 (CSV) - ヘッダー付き (.csv) またはヘッダーなし (.nh.csv)
- タブ区切り値 (TSV) - ヘッダー付き (.tsv) またはヘッダーなし (.nh.tsv)
- Excel ファイル
- Azure テーブル
- Hive テーブル
- SQL データベース テーブル
- OData 値
- SVMLight データ (.svmlight) (形式の詳細については、「 SVMLight の定義 」をご覧ください)。
- 属性関係ファイル形式 (ARFF) データ (.arff) (「 ARFF の定義 」をご覧ください)。
- Zip ファイル (.zip)
- R オブジェクトまたはワークスペース ファイル (.RData)
メタデータを含む ARFF などの形式でデータをインポートする場合、Studio (クラシック) はこのメタデータを使用して各列の見出しとデータ型を定義します。
このメタデータが含まれていない TSV や CSV 形式などのデータをインポートする場合、Studio (クラシック) は、データをサンプリングすることによって、各列のデータ型を推論します。 また、データに列見出しがない場合、Studio (クラシック) は既定の名前を提供します。
メタデータの編集 モジュールを使用して、列の見出しやデータ型を明示的に指定または変更できます。
次のデータ型は、Studio (クラシック) によって認識されます。
- 文字列
- 整数
- ダブル
- Boolean
- 日付と時刻
- TimeSpan
Studio は データ テーブル と呼ばれる内部データ型を使用し、モジュール間でデータを渡します。 データセットへの変換モジュールを使用して、データ テーブル形式にデータを明示的に変換できます。
データ テーブル以外の形式を受け取るどのモジュールでも、次のモジュールに渡す前に、サイレント モードでデータをデータ テーブルに変換します。
必要に応じて、その他の変換モジュールを使用して CSV、TSV、ARFF、SVMLight 形式にデータ テーブル形式をもう一度変換できます。 これらの関数を実行するモジュールについては、モジュール パレットの [Data Format Conversions] セクションを確認してください。
データ容量
Machine Learning Studio (クラシック) のモジュールは、一般的に、最大 10 GB の高密度数値データのデータセットをサポートしています。 モジュールが 1 つ以上の入力を受け取る場合、10 GB という値はすべての入力サイズの合計です。 Hive または Azure SQL Database のクエリを使用して、さらに大きなデータセットをサンプリングしたり、データをインポートする前に、前処理としてカウントによる学習を使用したりできます。
次の種類のデータは、特徴の正規化の際に、より大きなデータセットに展開できますが、10 GB 未満に制限されています。
- まばら
- カテゴリー別
- 文字列
- バイナリ データ
次のモジュールは、10 GB 未満のデータセットに制限されています。
- 推奨モジュール
- 合成マイノリティ過剰サンプリング技法 (Synthetic Minority Oversampling Technique, SMOTE) モジュール
- スクリプト モジュール: R、Python、SQL
- 出力データ サイズが入力データ サイズを超えるモジュール ("結合"、"特徴ハッシュ" など)
- イテレーションの数が非常に大きい場合には、クロスバリデーション、モデルのハイパーパラメーター調整、順序回帰、一対全多クラス分類を行います。
数 GB を超えるデータセットの場合は、ローカル ファイルから直接アップロードするのではなく、Azure Storage または Azure SQL Database にデータをアップロードするか、Azure HDInsight を使用する必要があります。
画像インポート モジュールのリファレンスで、画像データに関する情報を見つけることができます。
ローカル ファイルからインポートする
ハード ドライブからデータ ファイルをアップロードして、Studio (クラシック) でトレーニング データとして使用することができます。 データ ファイルをインポートするときは、ワークスペースでの実験に使用する準備のできたデータセット モジュールを作成します。
ローカル ハード ドライブからデータをインポートするには、次の手順を実行します。
- Studio (クラシック) ウィンドウの下部にある [+新規] をクリックします。
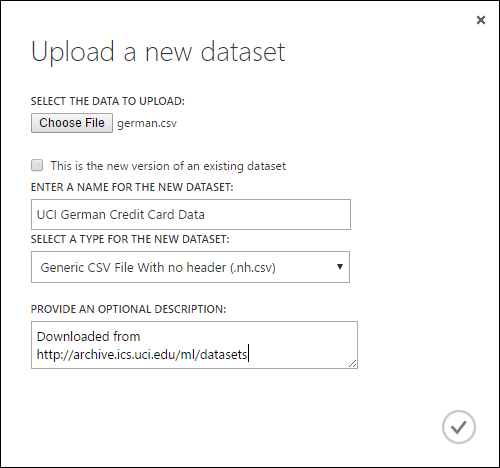
- [データセット] と [FROM LOCAL FILE] を選択します。
- [Upload a new dataset]\(新しいデータセットのアップロード\) ダイアログ ボックスで、アップロードするファイルを参照します。
- 名前を入力し、データ型を指定したら、必要に応じて説明を入力します。 データの特徴を記録しておくと、後でデータを使用する際に参照できるため、説明を入力しておくことをお勧めします。
- チェックボックス [This is the new version of an existing dataset] をオンにしておくことにより、新しいデータで既存のデータセットを更新できます。 そのためには、このチェック ボックスをクリックし、既存のデータセット名を入力します。
アップロード時間は、データのサイズと、サービスへの接続速度に依存します。 ファイルの処理に時間がかかる場合、待機している間に Studio (クラシック) で他の作業も実行できます。 ただし、データのアップロードが完了する前にブラウザーを閉じるとアップロードは失敗します。
データがアップロードされると、データセット モジュールに格納され、ワークスペース内のすべての実験で使用できるようになります。
実験を編集するときは、モジュール パレットの [保存されたデータセット] 一覧の [マイ データセット] 一覧に、アップロード済みのデータセットが表示されます。 データセットを別の分析と機械学習に使用する場合は、データセットを実験キャンバスにドラッグ アンド ドロップします。
オンライン データ ソースからインポートする
実験を実行している間に、データのインポート モジュールを使用して、さまざまなオンライン データ ソースから実験にデータをインポートできます。
注
この記事では、データのインポート モジュールに関する一般的な情報を提供します。 アクセスできるデータの種類、形式、パラメーターの詳細や、よく寄せられる質問への回答については、データのインポート モジュールのリファレンス トピックをご覧ください。
実験を実行している間に、データのインポート モジュールを使用して、次のいずれかのオンライン データ ソースのデータにアクセスできます。
- HTTP を使用した Web URL
- HiveQL を使用した Hadoop
- Azure Blob ストレージ
- Azure テーブル
- Azure SQL データベース。 SQL Managed Instance、または SQL Server
- データ フィード プロバイダー (現在は OData)
- Azure Cosmos DB
このトレーニング データは実験中にアクセスされるため、利用できるのは、その実験が行われている間だけです。 一方、データセット モジュールに保存されているデータには、ワークスペース内の任意の実験からアクセスできます。
Studio (クラシック) の実験でオンライン データ ソースにアクセスするには、データのインポート モジュールを実験に追加します。 次に、[プロパティ] の下にある [Launch Import Data Wizard]\(データ インポート ウィザードの起動\) を選択し、ステップ形式の指示に従ってデータ ソースを選択および構成します。 または、[プロパティ] の下にある [データ ソース] を手動で選択し、データへのアクセスに必要なパラメーターを指定することができます。
サポートされているオンライン データ ソースは、以下の表にまとめました。 サポートされているファイル形式と、データにアクセスするためのパラメーターも記載されています。
重要
現在、データのインポート モジュールと データのエクスポート モジュールでは、クラシック デプロイ モデルを使用して作成された Azure Storage からのみ、データの読み取りと書き込みを行うことができます。 つまり、ホット ストレージ アクセス層またはクール ストレージアクセス層を利用できる新しい Azure BLOB ストレージ アカウントの種類は、まだサポートされていません。
一般的に、このサービス オプションが利用可能になる前に作成された可能性のある Azure ストレージ アカウントに、影響が及ぶことはありません。 新しいアカウントを作成する必要がある場合は、デプロイメント モデルとして [クラシック] を選択するか、Resource Manager を使用して、[アカウントの種類] に [Blob ストレージ] ではなく [General (汎用)] を選択します。
詳細については、「 Azure Blob Storage: ホット層とクール層」を参照してください。
サポートされるオンライン データ ソース
Machine Learning Studio (クラシック) の Import Data モジュールでは、次のデータ ソースがサポートされています。
| データ ソース | 説明 | パラメーター |
|---|---|---|
| HTTP を使用する Web URL | コンマ区切り (CSV)、タブ区切り (TSV)、ARFF (Attribute-Relation File Format)、サポート ベクター マシン (SVM-Light) の各形式のデータを HTTP を使用する任意の Web URL から読み取ります。 |
URL: サイトの URL とファイル名、拡張子を含むファイルの完全名を指定します。 データ形式: サポートされているいずれかのデータ形式 (CSV、TSV、ARFF、SVM-light) を指定します。 データにヘッダー行がある場合、その行が列名の割り当てに使用されます。 |
| Hadoop/HDFS | Hadoop の分散ストレージからデータを読み取ります。 必要なデータは、HiveQL という SQL に似たクエリ言語で指定します。 Studio (クラシック) にデータを追加する前に、HiveQL を使用してデータを集計したり、データのフィルタリングを実行したりすることもできます。 |
Hive データベース クエリ: データを生成するために使用する Hive クエリを指定します。 HCatalog サーバー URI: <your cluster name>.azurehdinsight.net 形式でクラスターの名前を指定します。 Hadoop ユーザー アカウント名: クラスターをプロビジョニングするために使用する Hadoop ユーザー アカウント名を指定します。 Hadoop ユーザー アカウントのパスワード: クラスターをプロビジョニングするために使用する資格情報を指定します。 詳細については、HDInsight での Hadoop クラスターの作成に関する記事をご覧ください。 出力データの場所: データを Hadoop 分散ファイル システム (HDFS) に保存するか、Azure に保存するかを指定します。
出力データを Azure に保存する場合は、Azure ストレージ アカウント名、ストレージ アクセス キー、ストレージ コンテナー名を指定する必要があります。 |
| SQL データベース | Azure SQL Database または SQL Managed Instance に格納されているデータ、または Azure 仮想マシン上で実行されている SQL Server データベースに格納されているデータを読み取ります。 |
データベース サーバー名: データベースが実行されているサーバーの名前を指定します。
Azure 仮想マシン上でホストされる SQL Server の場合は、tcp:<Virtual Machine DNS Name>, 1433 という形式で入力します。 データベース名: サーバー上のデータベースの名前を指定します。 サーバー ユーザー アカウント名: データベースへのアクセス権限を持つアカウントのユーザー名を指定します。 サーバー ユーザー アカウントのパスワード: ユーザー アカウントのパスワードを指定します。 データベース クエリ: 読み取るデータを記述した SQL ステートメントを入力します。 |
| オンプレミス SQL データベース | SQL データベースに格納されているデータを読み取ります。 |
データ ゲートウェイ: SQL Server データベースにアクセスできるコンピューターにインストールされている Data Management Gateway の名前を指定します。 ゲートウェイの設定については、SQL Server のデータを使用する Machine Learning Studio (クラシック) での高度な分析の実行に関する記事をご覧ください。 データベース サーバー名: データベースが実行されているサーバーの名前を指定します。 データベース名: サーバー上のデータベースの名前を指定します。 サーバー ユーザー アカウント名: データベースへのアクセス権限を持つアカウントのユーザー名を指定します。 ユーザー名とパスワード: [Enter values (値の入力)] をクリックして、データベース資格情報を入力します。 SQL Server の構成方法に応じて、Windows 統合認証または SQL Server 認証を使用できます。 データベース クエリ: 読み取るデータを記述した SQL ステートメントを入力します。 |
| Azure テーブル | Azure Storage の Table service からデータを読み取ります。 大量のデータを低頻度で読み取る場合、Azure Table service を使用してください。 高い柔軟性、非リレーショナル (NoSQL)、圧倒的なスケーラビリティ、低コスト、高い可用性を特徴とするストレージ ソリューションです。 |
アクセスの対象がパブリックな情報であるか、ログイン資格情報を必要とするプライベートなストレージ アカウントであるかによってデータのインポートのオプションは変化します。 その点を決めるのが、認証の種類です。"PublicOrSAS" と "Account" のいずれかの値になります。その値によって、一連のパラメーターが異なります。 パブリックな URI または Shared Access Signature (SAS) の URI: パラメーターは次のとおりです。
プロパティ名のスキャン対象となる行を指定します: 指定した行数をスキャンする場合は TopN を、テーブル内のすべての行を取得する場合は ScanAll を値として指定します。 データが均一で予測可能である場合は、TopN を選択し、N の値を入力することをお勧めします。大きなテーブルでは、その方が読み取り時間が短くなります。 データを構成する一連のプロパティが、テーブルの深さと位置によって異なる場合は、ScanAll オプションを選択してすべての行をスキャンしてください。 これによって、プロパティとメタデータの変換結果に整合性を確保することができます。
アカウント キー: アカウントに関連付けられているストレージ キーを指定します。 テーブル名: 読み取るデータを含んだテーブルの名前を指定します。 プロパティ名のスキャン対象となる行: 指定した行数をスキャンする場合は TopN を、テーブル内のすべての行を取得する場合は ScanAll を値として指定します。 データが均一で予測可能である場合は、TopN を選択し、N の値を入力することをお勧めします。大きなテーブルでは、その方が読み取り時間が短くなります。 データを構成する一連のプロパティが、テーブルの深さと位置によって異なる場合は、ScanAll オプションを選択してすべての行をスキャンしてください。 これによって、プロパティとメタデータの変換結果に整合性を確保することができます。 |
| Azure Blob Storage (アジュール・ブロブ・ストレージ) | 画像、非構造化テキスト、バイナリ データなど、Azure Storage の Blob service に保存されているデータを読み取ります。 Blob service を使用して、データをパブリックに公開したり、アプリケーション データをプライベートに保存したりすることができます。 HTTP または HTTPS 接続を使用してどこからでもデータにアクセスできます。 |
アクセスの対象がパブリックな情報であるか、ログイン資格情報を必要とするプライベートなストレージ アカウントであるかによってデータのインポート モジュールのオプションは変化します。 その点を決めるのが認証の種類です。"PublicOrSAS" と "Account" のいずれかの値になります。 パブリックな URI または Shared Access Signature (SAS) の URI: パラメーターは次のとおりです。
ファイル形式: Blob service のデータの形式を指定します。 サポートされている形式は、CSV、TSV、ARFF です。
アカウント キー: アカウントに関連付けられているストレージ キーを指定します。 コンテナー、ディレクトリ、BLOB のパス: 読み取るデータを含んだ BLOB の名前を指定します。 BLOB ファイル形式: Blob service のデータの形式を指定します。 サポートされているデータ形式は CSV、TSV、ARFF、CSV (エンコーディング指定付き)、Excel です。
Excel を選択すると、Excel ブックからデータを読み取ることができます。 [Excel データ形式] オプションで、データの保存先が Excel ワークシートの範囲か Excel テーブルかを指定してください。 [Excel sheet or embedded table (Excel シートまたは埋め込みテーブル)] オプションで、読み取りの対象となるシートまたはテーブルの名前を指定します。 |
| データ フィード プロバイダー | サポートされているフィード プロバイダーからデータを読み取ります。 現在サポートされているのは Open Data Protocol (OData) 形式だけです。 |
データ コンテンツの種類: OData 形式を指定します。 ソース URL: データ フィードに使用する完全 URL を指定します。 たとえば、https://services.odata.org/northwind/northwind.svc/ という URL の場合、Northwind のサンプル データベースから読み取ります。 |
別の実験からインポートする
ある実験の中間結果を別の実験の一部として使用することが必要になる場合があります。 この場合は、モジュールをデータセットとして保存します。
- データセットとして保存するモジュールの出力をクリックします。
- [データセットとして保存]をクリックします。
- メッセージが表示されたら、名前と、データセットを簡単に識別できるような説明を入力します。
- [OK] チェックマークをクリックします。
保存が完了すると、ワークスペースのどの実験でもデータセットを使用できるようになります。 データセットは、モジュール パレットの [保存されたデータセット] リストから検索できます。
次のステップ
データのインポートおよびデータのエクスポート モジュールを使用する Machine Learning Studio (クラシック) Web サービスをデプロイする