Machine Learning Studio (クラシック) でモデルの結果を解釈する
適用対象:  Machine Learning Studio (クラシック)
Machine Learning Studio (クラシック)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
このトピックでは、Machine Learning Studio (クラシック) で予測結果を視覚化および解釈する方法について説明します。 モデルのトレーニングと予測 (「モデルのスコア付け」) が完了したら、予測結果を理解し、解釈する必要があります。
Machine Learning Studio (クラシック) には、機械学習モデルの主な種類として次の 4 つがあります。
- 分類
- クラスタリング
- 回帰
- レコメンダー システム
これらのモデルに基づく予測には、次のモジュールが使用されます。
- 分類と回帰のためのモデルのスコア付けモジュール
- クラスタリングのためのクラスターへの割り当てモジュール
- 推奨システムのためのマッチボックス レコメンダーのスコア付け
ML Studio (classic) でアルゴリズムを最適化するためにパラメーターを選択する方法について説明します。
モデルを評価する方法については、モデルのパフォーマンスを評価する方法に関する記事を参照してください。
ML Studio (classic) を初めて使用する場合は、簡単な実験を作成する方法を参照してください。
分類
分類問題には 2 つのサブ カテゴリがあります。
- 2 つのクラス (2 クラスまたは二項分類) のみに関する問題
- 3 つ以上のクラス (多クラス分類) に関する問題
Machine Learning Studio (クラシック) には、これらの各種類の分類に対処するためのさまざまなモジュールが含まれていますが、それらの予測結果を解釈するための方法はほぼ同じです。
Two-class classification (2 クラス分類)
実験例
2 クラス分類問題の例では、あやめの分類を使用します。 ここでのタスクは、特徴に基づいてあやめを分類することです。 Machine Learning Studio (クラシック) で提供されるあやめのデータ セットは、2 つの花の種 (クラス 0 と 1) のみのインスタンスが含まれた一般的なあやめのデータ セットのサブセットです。 それぞれの花には 4 種類の特徴 (がくの長さ、がくの幅、花弁の長さ、花弁の幅) があります。

図 1. あやめの 2 クラス分類問題の実験
この問題を解決するために、図 1 に示すとおり実験が実行されました。 2 クラスのブースト デシジョン ツリー モデルがトレーニングされ、スコア付けされました。 これで、モデルのスコア付けモジュールの出力ポートをクリックしてから [視覚化] をクリックすることによって、モデルのスコア付けモジュールの予測結果を視覚化できるようになりました。
図 2 に示すように、スコア付けの結果が表示されます。
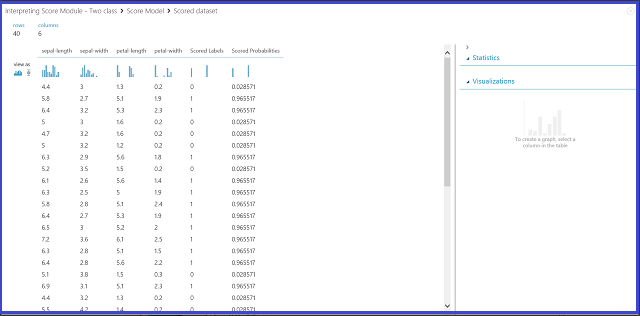
図 2. 2 クラス分類でモデルのスコア付けの結果を視覚化する
結果の解釈
結果テーブルには、6 つの列があります。 左の 4 つの列は、4 種類の特徴です。 右側の 2 つの列、「Scored Labels (スコア付けラベル)」と「Scored Probabilities (スコア付け確率)」は予測結果です。 「Scored Probabilities」列は、花が正のクラス (クラス 1) に属する確率を示しています。 たとえば、列の最初の数字 (0.028571) は、最初の花がクラス 1 に属する確率が 0.028571 であることを意味しています。 「Scored Labels」列は、各花の予測クラスを示しています。 これは、「Scored Probabilities」列に基づいています。 花のスコア付け確率が 0.5 よりも高い場合は、クラス 1 と予測され、 それ以外の場合はクラス 0 と予測されます。
Web サービスの発行
予測結果を理解し、結果の妥当性が確認できたら、実験を Web サービスとして発行できます。発行すると、さまざまなアプリケーションでデプロイして呼び出し、新しいあやめに関するクラスの予測を取得できます。 トレーニング実験をスコアリング実験に変更し、それを Web サービスとして公開する方法については、「 Tutorial 3: 信用リスク モデルのデプロイを参照してください。 この手順に従うと、図 3 で示すスコア付け実験を実行できます。
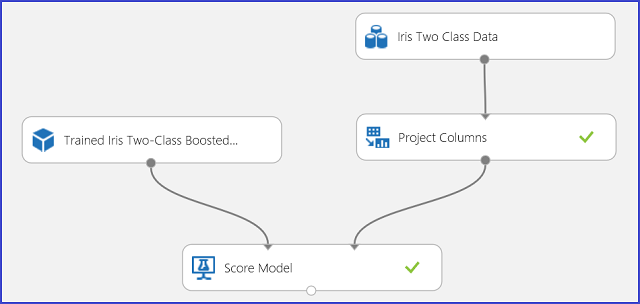
図 3。 あやめの 2 クラス分類問題のスコア付け実験
次は、Web サービスの入力と出力を設定する必要があります。 この入力は、モデルのスコア付けの右の入力ポート (あやめの特徴の入力) です。 どの出力を選択するかは、予測されたクラス (スコア付けラベル)、スコア付け確率、その両方のどれを使用するかによって異なります。 この例では両方を使用します。 目的の出力列を選択するには、データセット内の列の選択モジュールを使用します。 [データセット内の列の選択]、[列セレクターの起動] の順にクリックし、[スコア付けラベル] と [スコア付け確率] を選択します。 データセット内の列の選択の出力ポートを設定し、それを再度実行したら、[Web サービスの発行] をクリックすることによりスコア付け実験を Web サービスとして発行する準備ができました。 最終的な実験は、図 4 のようになります。

図 4 あやめの 2 クラス分類問題の最終スコア付け実験
Web サービスを実行し、テスト インスタンスの特徴の値を入力すると、結果として 2 つの数値が返されます。 1 つ目の数値はスコア付けラベルで、2 つ目の数値はスコア付け確率です。 この花は 0.9655 の確率でクラス 1 と予測されました。


図 5。 あやめの 2 クラス分類の Web サービス結果
Multi-class classification (多クラス分類)
実験例
この実験では、多クラス分類の例として、文字認識タスクを実行します。 分類子は、手書きの画像から抽出されたいくつかの手書き属性値に基づいて、特定の文字 (クラス) を予測しようとします。

トレーニング データには、手書き文字の画像から抽出された特徴が 16 個あります。 26 個の文字から、26 個のクラスが形成されています。 図 6 に示す実験は、文字認識用に多クラス分類モデルをトレーニングし、テスト データセットと同じ特徴のセットを予測します。

図 6。 文字認識の多クラス分類問題の実験
モデルのスコア付けモジュールの出力ポートをクリックしてから [視覚化] をクリックすることによって、モデルのスコア付けモジュールの結果を視覚化すると、図 7 に示す内容が表示されます。
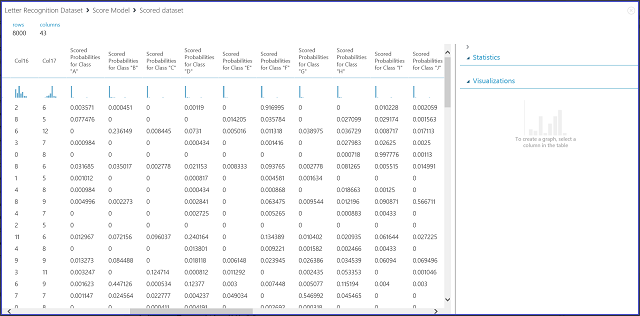
図 7. 多クラス分類でモデルのスコア付けの結果を視覚化する
結果の解釈
左の 16 列は、テスト セットの特徴の値を示します。 「Scored Probabilities for Class "XX"」という名前の列は、2 クラスの場合における「Scored Probabilities」列と同じです。 これらの列は、対応するエントリが特定のクラスに分類される確率を示しています。 たとえば、最初のエントリが "A" である確率は 0.003571 であり、"B" である確率は 0.000451 であることを示しています。 最後の列 (Scored Labels) は、2 クラス分類の場合の「Scored Labels」と同じです。 対応するエントリの予測クラスとして、最も高いスコア付け確率を持つクラスを選択します。 たとえば最初のエントリでは、最も確率が高いのは "F" (0.916995) であるため、Scored Labels は "F" になります。
Web サービスの発行
各エントリのスコア付けラベルと、そのスコア付けラベルの確率を取得することもできます。 基本的なロジックは、すべてのスコア付け確率の中から最も高い確率を見つけることです。 これを行うには、R スクリプトの実行モジュールを使用する必要があります。 図 8 に R コードを、図 9 に実験の結果を示します。

図 8. スコア付けラベルとそのラベルに関連付けられた確率を抽出する R コード

図 9. 文字認識の多クラス分類問題の最終スコア付け実験
Web サービスを発行して実行し、一部の入力特徴値を入力した後に返される結果は、図 10 のようになります。 抽出された 16 の特徴を持つこの手書き文字は、0.9715 の確率で "T" であると予測されます。


図 10. 多クラス分類の Web サービス結果
回帰
回帰問題は分類問題とは異なります。 分類問題では、あやめが属するクラスなどの個別のクラスを予測しますが、 回帰問題では、次の例に示すように、自動車価格などの連続変数を予測します。
実験例
回帰の例として、自動車価格の予測を使用します。 製造、燃料の種類、車体タイプ、駆動輪などの特徴に基づいて、自動車価格を予測します。 図 11 に実験を示します。

図 11. 自動車価格の回帰問題の実験
モデルのスコア付けモジュールを視覚化すると、結果は図 12 のようになります。
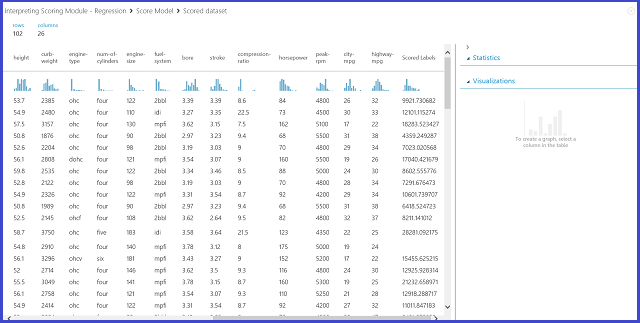
図 12. 自動車価格の予測問題のスコア付け結果
結果の解釈
このスコア付け結果では、「Scored Labels」が結果の列になります。 数値は、各車に対して予測された価格です。
Web サービスの発行
回帰実験を Web サービスに発行し、2 クラス分類で使用した場合と同じ方法で自動車価格の予測を呼び出すことができます。

図 13. 自動車価格の回帰問題のスコア付け実験
Web サービスを実行して返された結果は、図 14 のようになります。 この車の予測価格は 15,085.52 ドルです。
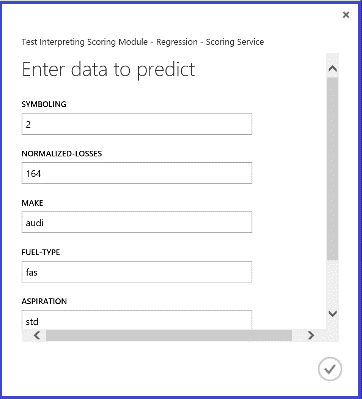

図 14: 自動車価格の回帰問題の Web サービス結果
クラスタリング
実験例
あやめのデータ セットもう一度使用して、クラスタリングの実験をビルドします。 ここでは、データセットでクラス ラベルを除外し、クラスタリングで使用可能な特徴のみが含まれるようにします。 このあやめの使用例では、トレーニング プロセス中のクラスター数を 2 に設定することで、花を 2 つのクラスにクラスタリングします。 図 15 に実験を示します。

図 15: あやめのクラスタリング問題の実験
クラスタリングは、トレーニング データ セットがグランドトルースのラベルを単独で持たない点で、分類とは異なります。 クラスタリングでは、トレーニング データセットのインスタンスを個別のクラスターにグループ化します。 トレーニング プロセス中に、モデルは特徴ごとの違いを学習してエントリにラベルを付けます。 その後、トレーニング済みモデルを使用して、後続のエントリをさらに分類できます。 クラスタリング問題で使用する結果には 2 つのパートがあります。 最初のパートでは、トレーニング データセットにラベルを付け、2 つ目のパートでは、トレーニング済みモデルを使用して新しいデータセットを分類します。
結果の最初のパートは、クラスタリング モデルのトレーニングの左の出力ポートをクリックしてから [視覚化] をクリックすることによって視覚化できます。 図 16 は、その視覚化を示しています。

図 16: トレーニング データセットのクラスタリング結果を視覚化する
図 17 には、2 つ目のパートの結果である、トレーニング済みクラスタリング モデルによる新しいエントリのクラスタリングを示します。
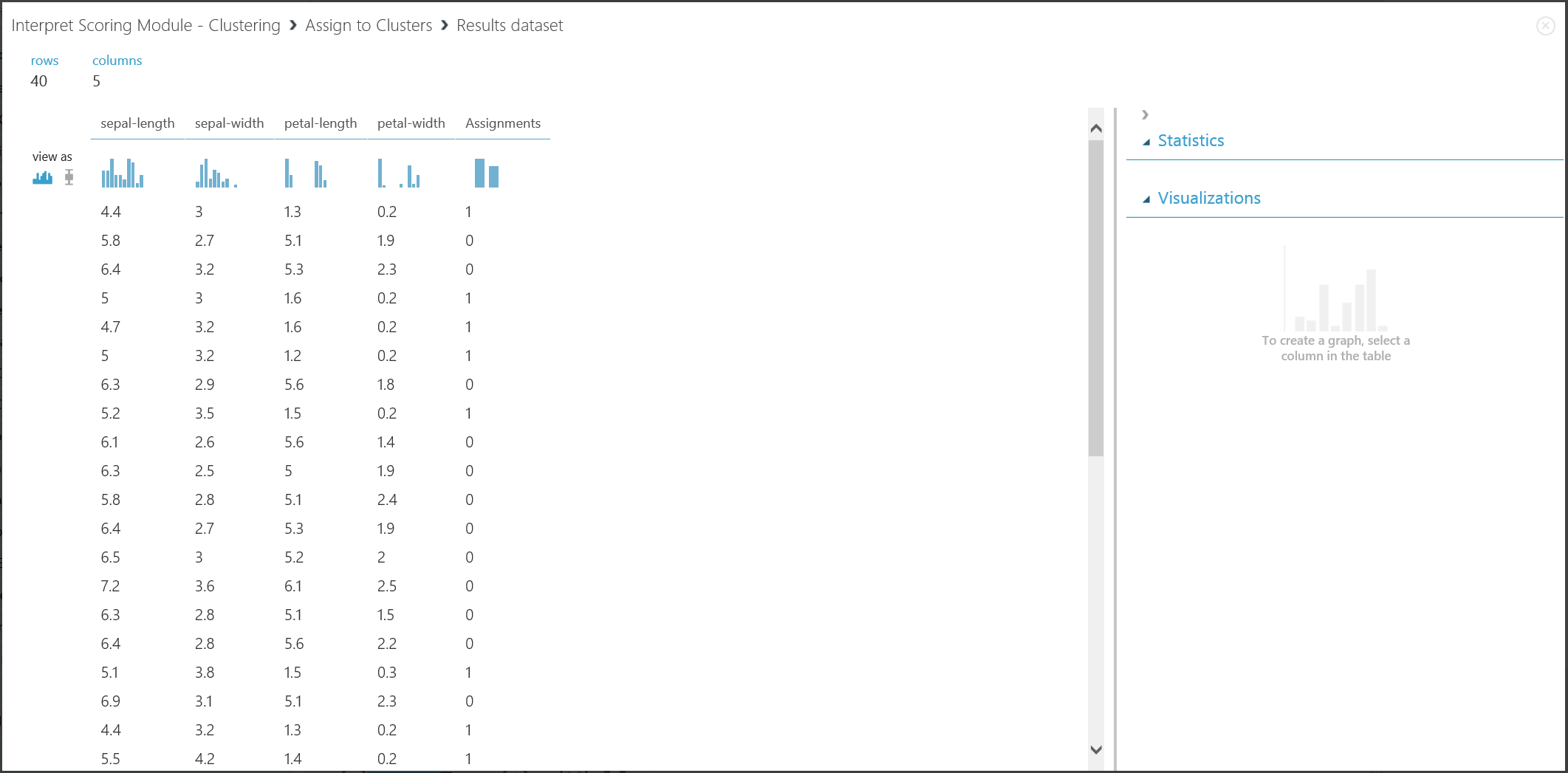
図 17: 新しいデータセットのクラスタリング結果を視覚化する
結果の解釈
2 つのパートの結果は別の実験ステージから生じていますが、外観は同じであり、同じ方法で解釈されます。 最初の 4 つの列が特徴です。 最後の「Assignments」列は、予測結果です。 同じ番号が割り当てられているエントリは、同じクラスターにあると予測されます。すなわち、何らかの方法 (この実験では既定のユークリッド距離メトリックを使用) で類似点を共有します。 クラスターの数を 2 に指定したため、「Assignments」列のエントリは、0 または 1 とラベル付けされます。
Web サービスの発行
クラスタリング実験を Web サービスに発行し、2 クラス分類で使用した場合と同じ方法でクラスタリング予測用に呼び出すことができます。
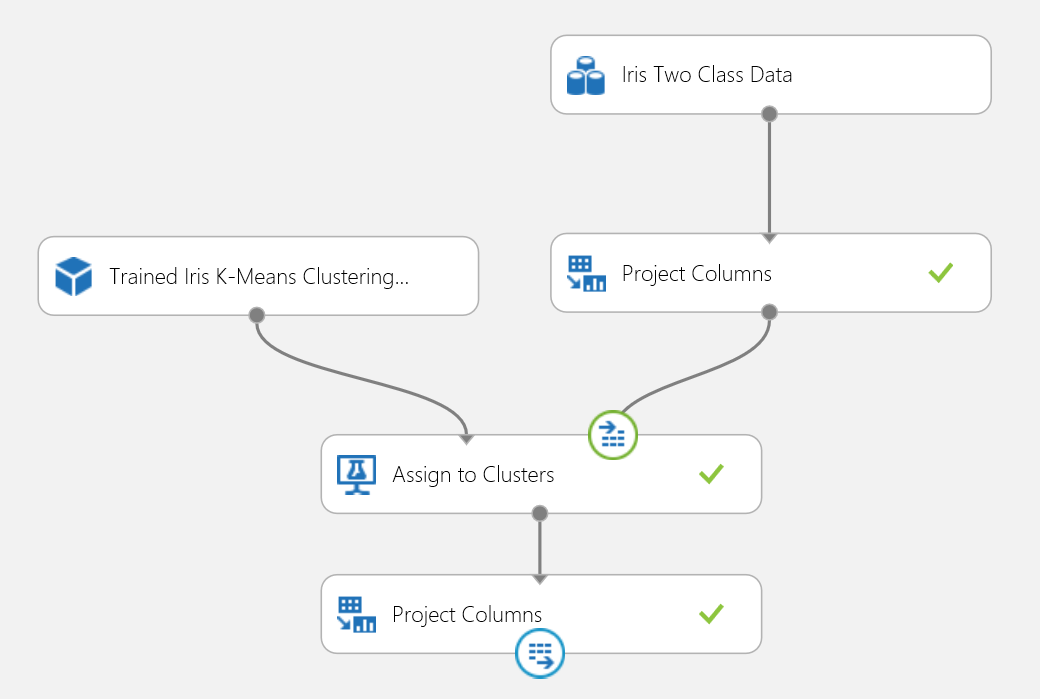
図 18: あやめのクラスタリング問題のスコア付け実験
Web サービスを実行して返された結果は、図 19 のようになります。 この花は、クラスター 0 に属していると予測されます。


図 19: あやめの 2 クラス分類の Web サービス結果
レコメンダー システム
実験例
レコメンダー システムでは、顧客の評価履歴に基づいて顧客にレストランを勧める、レストランの推奨問題を例として使用します。 入力データは、3 つのパートで構成されます。
- 顧客によるレストランの評価
- 顧客の特徴データ
- レストラン特徴データ
Machine Learning Studio (クラシック) のマッチボックス レコメンダーのトレーニング モジュールを使用すると、次のいくつかのことを実行できます。
- 特定のユーザーと項目の評価を予測する
- 特定のユーザーに項目を推奨する
- 特定のユーザーに関連するユーザーを検索する
- 特定のユーザーに関連する項目を検索する
[Recommender prediction kind] メニューにある 4 つのオプションから実行内容を選択できます。 ここでは、4 つのシナリオすべてについて説明します。

レコメンダー システム用の一般的な Machine Learning Studio (クラシック) の実験は図 20 のようになります。 これらのレコメンダー システム モジュールを使用する方法については、マッチボックス レコメンダーのトレーニングおよびマッチボックス レコメンダーのスコア付けに関するページを参照してください。

図 20: レコメンダー システムの実験
結果の解釈
特定のユーザーと項目の評価を予測する
[Recommender prediction kind] で [Rating Prediction] を選択し、レコメンダー システムで特定のユーザーと項目に対する評価を予測するよう指定します。 マッチボックス レコメンダーのスコア付けの出力の視覚化は図 21 のようになります。

図 21: レコメンダー システムのスコア付け結果を視覚化する - 評価予測
最初の 2 つの列は、入力データによって提供されるユーザーと項目のペアです。 3 つ目の列は、特定の項目に対して予測されるユーザーの評価です。 たとえば最初の行では、顧客 U1048 がレストラン 135026 を 2 と評価することが予測されます。
特定のユーザーに項目を推奨する
[Recommender prediction kind] メニューで [Item Recommendation] を選択し、レコメンダー システムで特定のユーザーに対して項目を勧めるよう指定します。 このシナリオでは、最後に Recommended item selection パラメーターも選ぶ必要があります。 オプション [From Rated Items (for model evaluation)] は主に、トレーニング プロセス中のモデルの評価で使用します。 この予測ステージでは、 [From All Items]を選択します。 マッチボックス レコメンダーのスコア付けの出力の視覚化は図 22 のようになります。

図 22: レコメンダー システムのスコア付け結果を視覚化する - 項目の推奨
6 つの列のうち、最初の列は入力データによって提供される、推奨項目に対する特定のユーザー ID を示します。 他の 5 つの列は、ユーザーに勧める項目を、関連性が高い順に並べ替えて示します。 たとえば最初の行では、顧客 U1048 に対して最も推奨されるレストランが 134986 であり、その後に 135018、134975、135021、132862 が続いています。
特定のユーザーに関連するユーザーを検索する
[Recommender prediction kind] メニューで [Related Users] を選択し、レコメンダー システムで特定のユーザーに関連するユーザーを検索するよう指定します。 関連するユーザーとは、類似する嗜好を持つユーザーのことです。 このシナリオでは、最後に Related user selection パラメーターも選ぶ必要があります。 オプション [From Users That Rated Items (for model evaluation)] は主に、トレーニング プロセス中のモデルの評価で使用します。 この予測ステージでは、[From All Users] を選択します。 マッチボックス レコメンダーのスコア付けの出力の視覚化は図 23 のようになります。

図 23: レコメンダー システムのスコア付け結果を視覚化する - 関連ユーザー
6 つの列のうち、最初の列は入力データによって提供される、関連ユーザーの検索に必要な特定のユーザー ID です。 他の 5 つの列は、ユーザーに関連することが予測されるユーザーを、関連性の高い順に並べ替えて表示します。 たとえば最初の行では、顧客 U1048 に最も関連性が高い顧客は U1051 であり、その後に U1066、U1044、U1017、U1072 が続いています。
特定のユーザーに関連する項目を検索する
[Recommender prediction kind] で [Related Items] を選択し、レコメンダー システムで特定の項目に関連する項目を検索するよう指定します。 関連アイテムとは、同じユーザーが満足する可能性が最も高い項目です。 このシナリオでは、最後に Related item selection パラメーターも選ぶ必要があります。 オプション [From Rated Items (for model evaluation)] は主に、トレーニング プロセス中のモデルの評価で使用します。 この予測ステージでは、 [From All Items] を選択します。 マッチボックス レコメンダーのスコア付けの出力の視覚化は図 24 のようになります。

図 24: レコメンダー システムのスコア付け結果を視覚化する - 関連項目
6 つの列のうち、最初の列は入力データによって提供される、関連する項目の検索に必要な特定の項目 ID を表示します。 他の 5 つの列は、項目に関連することが予測される項目を、関連性が高い順に並べ替えて表示します。 たとえば、最初の行では、項目 135026 に最も関連する項目は 135074 であり、その後に 135035、132875、135055、134992 が続きます。
Web サービスの発行
これらの実験を Web サービスとして発行し、予測を得るプロセスは、4 つのシナリオで類似しています。 ここでは、2 つ目のシナリオ (特定のユーザーへの推奨項目) を例として使用します。 その他の 3 つのシナリオでも、同じ手順を実行できます。
トレーニング済みモデルとしてトレーニング済みレコメンダー システムを保存し、入力データを指定した 1 人のユーザー ID 列にフィルター処理します。図 25 のように実験を組み立て、Web サービスとして発行できます。

図 25: レストランの推奨問題のスコア付け実験
Web サービスを実行して返された結果は、図 26 のようになります。 ユーザー U1048 に対して推奨される 5 つのレストランは、134986、135018、134975、135021、132862 です。


図 26: レストランの推奨問題の Web サービス結果