データ ディスクを Linux 仮想マシンに接続する方法
重要
クラシック VM は 2023 年 3 月 1 日に廃止される予定です。
ASM の IaaS リソースを使用する場合は、すぐに移行の計画を開始し、2023 年 3 月 1 日までに完了してください。ASM の IaaS リソースを使用する場合は、すぐに移行の計画を開始し、2023 年 3 月 1 日までに完了してください。 Azure Resource Manager の多数の機能強化を活用するために、早急に切り替えを行うことをお勧めします。
詳細については、「2023 年 3 月 1 日までに IaaS リソースを Azure Resource Manager に移行する」を参照してください。
Note
Azure には、リソースの作成と操作に関して、2 種類のデプロイ モデルがあります。Resource Manager とクラシックです。 この記事では、クラシック デプロイ モデルの使用方法について説明します。 最新のデプロイメントでは、リソース マネージャー モデルを使用することをお勧めします。 Resource Manager デプロイ モデルを使用してデータ ディスクを接続する方法を参照してください。
空のディスクと、データが含まれているディスクのどちらも Azure VM に接続できます。 どちらの種類のディスクも、Azure ストレージ アカウントの .vhd ファイルです。 Linux マシンへのディスクの追加では、ディスクを接続した後、初期化とフォーマットを行って使用できるようにする必要があります。 この記事では、空のディスクと、データが含まれているディスクの両方を Azure VM に接続し、新しいディスクを初期化してフォーマットする方法について詳しく説明します。
Note
仮想マシンのデータを格納するには、1 つ以上の個別のディスクを使用することをお勧めします。 Azure の仮想マシンを作成するとき、オペレーティング システム ディスクと一時ディスクが表示されます。 永続データの格納に一時ディスクを使用しないでください。 名前が示すとおり、D ドライブは一時的なストレージのみを提供します。 Azure Storage に配置されていないため、冗長性やバックアップは提供しません。
一時ディスクは通常、Azure Linux Agent によって管理され、/mnt/resource (または Ubuntu イメージでは /mnt) に自動的にマウントされます。 一方で、データ ディスクには Linux カーネルによって /dev/sdc のような名前が付けられる場合があります。その場合、このリソースをパーティション分割し、フォーマットしてからマウントする必要があります。 詳細については、「Azure Linux エージェント ユーザー ガイド」を参照してください。
ディスクの詳細については、仮想マシン用のディスクと VHD に関するページを参照してください。
Attach an empty disk
Azure クラシック CLI を開いて、Azure サブスクリプションに接続します。 Azure サービス管理モード (
azure config mode asm) であることを確認します。次の例に示すように「
azure vm disk attach-new」と入力し、新しいディスクを作成して接続します。 myVM は Linux 仮想マシンの名前で置き換え、ディスクのサイズを GB 単位で指定します (この例では 100 GB)。azure vm disk attach-new myVM 100データ ディスクが作成されて接続されると、次の例に示すように
azure vm disk list <virtual-machine-name>の出力に表示されます。azure vm disk list TestVM出力は次の例のようになります。
info: Executing command vm disk list * Fetching disk images * Getting virtual machines * Getting VM disks data: Lun Size(GB) Blob-Name OS data: --- -------- -------------------------------- ----- data: 30 myVM-2645b8030676c8f8.vhd Linux data: 0 100 myVM-76f7ee1ef0f6dddc.vhd info: vm disk list command OK
既存のディスクの接続
既存のディスクを接続する場合は、ストレージ アカウントで利用できる .vhd を持っている必要があります。
Azure クラシック CLI を開いて、Azure サブスクリプションに接続します。 Azure サービス管理モード (
azure config mode asm) であることを確認します。接続する VHD が Azure サブスクリプションに既にアップロードされているかどうかを確認します。
azure vm disk list出力は次の例のようになります。
info: Executing command vm disk list * Fetching disk images data: Name OS data: -------------------------------------------- ----- data: myTestVhd Linux data: TestVM-ubuntuVMasm-0-201508060029150744 Linux data: TestVM-ubuntuVMasm-0-201508060040530369 info: vm disk list command OK使用するディスクが見つからない場合は、
azure vm disk createまたはazure vm disk uploadを使用してローカル VHD をサブスクリプションにアップロードできます。disk createの例は、次のようになります。azure vm disk create myVhd .\TempDisk\test.VHD -l "East US" -o Linux出力は次の例のようになります。
info: Executing command vm disk create + Retrieving storage accounts info: VHD size : 10 GB info: Uploading 10485760.5 KB Requested:100.0% Completed:100.0% Running: 0 Time: 25s Speed: 82 KB/s info: Finishing computing MD5 hash, 16% is complete. info: https://mystorageaccount.blob.core.windows.net/disks/myVHD.vhd was uploaded successfully info: vm disk create command OKazure vm disk uploadを使用して、特定のストレージ アカウントに VHD をアップロードすることもできます。 Azure 仮想マシン データ ディスクの管理用コマンドの詳細については、こちらを参照してください。ここで、必要な VHD を仮想マシンに接続します。
azure vm disk attach myVM myVhdmyVM は仮想マシンの名前に、myVHD は目的の VHD に置き換えてください。
ディスクが仮想マシンに接続されたことを確認するには、
azure vm disk list <virtual-machine-name>を使用します。azure vm disk list myVM出力は次の例のようになります。
info: Executing command vm disk list * Fetching disk images * Getting virtual machines * Getting VM disks data: Lun Size(GB) Blob-Name OS data: --- -------- -------------------------------- ----- data: 30 TestVM-2645b8030676c8f8.vhd Linux data: 1 10 test.VHD data: 0 100 TestVM-76f7ee1ef0f6dddc.vhd info: vm disk list command OK
Note
データ ディスクを追加した後、仮想マシンがストレージとしてそのディスクを使用できるように、仮想マシンにログオンしてディスクを初期化する必要があります (ディスクを初期化する方法の詳細については次の手順を参照)。
Linux での新しいデータ ディスクの初期化
VM に SSH 接続します。 詳細については、「Linux を実行する仮想マシンにログオンする方法」を参照してください。
次に、データ ディスクの初期化のためにデバイスの ID を検索する必要があります。 この作業を実行する 2 つの方法があります。
a) 次のコマンドのように、ログの SCSI デバイスを検索します。
sudo grep SCSI /var/log/messages最新の Ubuntu ディストリビューションの場合は、
/var/log/messagesへのログ記録が既定で無効になっていることがあるため、sudo grep SCSI /var/log/syslogの使用が必要になる場合があります。表示されたメッセージで、最後に追加されたデータ ディスクの識別子を確認できます。

OR
b)
lsscsiコマンドを使用してデバイス ID を調べます。lsscsiは、yum install lsscsi(Red Hat ベースのディストリビューション) またはapt-get install lsscsi(Debian ベースのディストリビューション) のいずれかでインストールできます。 検索対象のディスクは、その LUN ( 論理ユニット番号) で検索できます。 たとえば、ディスクに割り当てた LUN は、azure vm disk list <virtual-machine>から以下のように簡単に確認することができます。azure vm disk list myVM次のように出力されます。
info: Executing command vm disk list + Fetching disk images + Getting virtual machines + Getting VM disks data: Lun Size(GB) Blob-Name OS data: --- -------- -------------------------------- ----- data: 30 myVM-2645b8030676c8f8.vhd Linux data: 0 100 myVM-76f7ee1ef0f6dddc.vhd info: vm disk list command OKこのデータを、同じサンプル仮想マシンに対する
lsscsiの出力と比較します。[1:0:0:0] cd/dvd Msft Virtual CD/ROM 1.0 /dev/sr0 [2:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [3:0:1:0] disk Msft Virtual Disk 1.0 /dev/sdb [5:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdc各行のタプルの最後の番号は lun です。 詳細については、「
man lsscsi」を参照してください。プロンプトで、次のコマンドを入力して、デバイスを作成します。
sudo fdisk /dev/sdc表示されるプロンプトで「n」と入力すると、パーティションが作成されます。

求められたら、「 p 」と入力して、パーティションをプライマリ パーティションにします。 「 1 」と入力して最初のパーティションにし、Enter キーを押してシリンダーの既定値をそのまま使用します。 システムによっては、シリンダーではなく、最初と最後のセクターの既定値が表示される場合があります。 これらの既定値をそのまま使用することもできます。

「 p 」を入力すると、パーティション分割されたディスクに関する詳細情報が表示されます。

「 w 」と入力すると、ディスクの設定が書き込まれます。

これで、新しいパーティションにファイル システムを作成できます。 パーティション番号をデバイス ID に追加します (次の例では
/dev/sdc1)。 次の例では、ext4 パーティションを /dev/sdc1 に作成します。sudo mkfs -t ext4 /dev/sdc1
Note
SuSE Linux Enterprise 11 システムでは、ext4 ファイル システムへのアクセスは読み取り専用のみサポートされます。 これらのシステムには ext4 ではなく ext3 として新しいファイル システムの書式設定することをお勧めします。
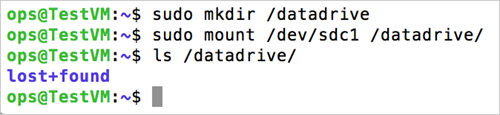
次のように、新しいファイル システムをマウントするディレクトリを作成します。
sudo mkdir /datadrive最後に、次のように、ドライブをマウントできます。
sudo mount /dev/sdc1 /datadriveこれで、データ ディスクを /datadriveとして使用する準備ができました。
新しいドライブを /etc/fstab に追加します。
再起動後にドライブを自動的に再マウントするために、そのドライブを /etc/fstab ファイルに追加する必要があります。 また、ドライブを参照する際に、デバイス名 (つまり /dev/sdc1) だけではなく、UUID (汎用一意識別子) を /etc/fstab で使用することもお勧めします。 UUID を使用すると、OS が起動中にディスク エラーを検出した場合に、間違ったディスクが特定の場所にマウントされて残りのデータ ディスクにそれらのデバイス ID が割り当てられるのを防ぐことができます。 新しいドライブの UUID を検索するには、 blkid ユーティリティを使用します。
sudo -i blkid出力は次の例のようになります。
/dev/sda1: UUID="11111111-1b1b-1c1c-1d1d-1e1e1e1e1e1e" TYPE="ext4" /dev/sdb1: UUID="22222222-2b2b-2c2c-2d2d-2e2e2e2e2e2e" TYPE="ext4" /dev/sdc1: UUID="33333333-3b3b-3c3c-3d3d-3e3e3e3e3e3e" TYPE="ext4"Note
/etc/fstab ファイルを不適切に編集すると、システムが起動できなくなる可能性があります。 編集方法がはっきりわからない場合は、このファイルを適切に編集する方法について、ディストリビューションのドキュメントを参照してください。 編集する前に、/etc/fstab ファイルのバックアップを作成することもお勧めします。
次に、テキスト エディターで /etc/fstab ファイルを開きます。
sudo vi /etc/fstabこの例では、前の手順で作成した新しい /dev/sdc1 デバイスに対して UUID 値を使用し、マウント ポイントとして /datadrive を使用します。 次の行を /etc/fstab ファイルの末尾に追加します。
UUID=33333333-3b3b-3c3c-3d3d-3e3e3e3e3e3e /datadrive ext4 defaults,nofail 1 2または、SuSE Linux に基づいたシステムでは、わずかに異なる形式を使用する必要がある場合があります。
/dev/disk/by-uuid/33333333-3b3b-3c3c-3d3d-3e3e3e3e3e3e /datadrive ext3 defaults,nofail 1 2注意
nofailオプションを使用すると、ファイル システムが壊れているか、ブート時にディスクが存在しない場合でも VM が起動されるようになります。 このオプションがないと、「 FSTAB エラーが原因で Linux VM に SSH 接続できない」の説明に従って動作が発生する可能性があります。これで、ファイル システムが正しくマウントされるかどうかをテストできます。そのためには、ファイル システムをマウント解除してから、もう一度マウントします。つまり、前の手順で作成したサンプルのマウント ポイント
/datadriveを使用します。sudo umount /datadrive sudo mount /datadrivemountコマンドでエラーが発生した場合、/etc/fstab ファイルの構文が正しいかどうかを確認してください。 追加のデータ ドライブやパーティションを作成する場合は、それらも /etc/fstab に個別に入力します。次のコマンドを使用して、ドライブを書き込み可能にします。
sudo chmod go+w /datadrive注意
この後、fstab を編集せずにデータ ディスクを削除すると VM は起動できません。 これが頻繁に発生する場合、大部分のディストリビューションでは
nofailまたはnobootwaitfstab オプションが提供されます。これによって、起動時にディスクのマウントが失敗してもシステムを起動することができます。 これらのパラメーターの詳細については、使用しているディストリビューションのドキュメントを参照してください。
Azure における Linux の TRIM/UNMAP サポート
一部の Linux カーネルでは、ディスク上の未使用ブロックを破棄するために TRIM/UNMAP 操作がサポートされます。 これらの操作は主に、Standard Storage で、削除されたページが無効になり、破棄できるようになったことを Azure に通知するときに役立ちます。 ページを破棄すると、サイズの大きいファイルを作成して削除する場合のコストを節約できます。
Linux VM で TRIM のサポートを有効にする方法は 2 通りあります。 通常どおり、ご使用のディストリビューションで推奨される方法をお問い合わせください。
次のように、
/etc/fstabでdiscardマウント オプションを使用します。UUID=33333333-3b3b-3c3c-3d3d-3e3e3e3e3e3e /datadrive ext4 defaults,discard 1 2場合によっては、
discardオプションがパフォーマンスに影響する可能性があります。 または、fstrimコマンドを手動でコマンド ラインから実行するか、crontab に追加して定期的に実行することができます。Ubuntu
sudo apt-get install util-linux sudo fstrim /datadriveRHEL/CentOS
sudo yum install util-linux sudo fstrim /datadrive
トラブルシューティング
データ ディスクを Linux VM に追加するときに、LUN 0 にディスクが存在しないと、エラーが発生することがあります。
azure vm disk attach-new コマンドを使用して手動でディスクを追加していて、Azure プラットフォームに適切な LUN を判定させるのではなく、LUN を指定する (--lun) 場合は、LUN 0 にディスクが既に存在するようにするか、今後存在するようにしてください。
lsscsiからの出力のスニペットを示す次の例を考えてみましょう。
[5:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdc
[5:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdd
2 つのデータ ディスクは LUN 0 と LUN 1 に存在します (lsscsi の出力詳細の最初の列は [host:channel:target:lun] です)。 両方のディスクには、VM 内からアクセスできる必要があります。 LUN 1 で追加対象の最初のディスク、LUN 2 で 2 番目のディスクを手動で指定した場合は、VM 内からこれらのディスクを正しく見ることはできません。
Note
これらの例では Azure の host 値は 5 ですが、選択したストレージの種類によっては変わる可能性があります。
このディスクの動作は Azure の問題ではなく、Linux カーネルが SCSI の仕様に従う仕組みです。 Linux カーネルが接続されているデバイスの SCSI バスをスキャンするときに、デバイスが LUN 0 で検出される必要があります。システムが他のデバイスのスキャンを続行できるようにするためです。 そのため、次のようにしてください。
- データ ディスクを追加した後に
lsscsiの出力を確認し、LUN 0 にディスクがあることを確認します。 - ディスクが VM 内に正しく表示されない場合は、ディスクが LUN 0 に存在することを確認します。
次の手順
以下の記事で、Linux VM の使用方法について詳しい情報を得ることができます。