Windows PowerShell正規表現を記述する
Don Jones
192.168.4.5、\\Server57\Share、および johnd@contoso.com。これら 3 つの項目が IP アドレス、汎用名前付け規則 (UNC) パス、および電子メール アドレスであることは簡単にわかると思います。皆さんの脳がこのような形式を認識しているのです。4 つに区切られた数字、円記号、アット マーク (@)、およびその他の手がかりが、これらの文字列が
表すデータの種類を示しています。ほとんど考えなくても、192.168 だけでは有効な IP アドレスにならないこと、7\\Server2\\Share が有効な UNC ではないこと、および joe@contoso が有効な電子メール アドレスではないことはすぐにわかります。
残念ながら、コンピュータがこのような複雑な形式を "理解" するには、もう少し機能が向上する必要があります。ここで活躍するのが、正規表現です。正規表現とは、特殊な正規表現言語で記述された文字列です。正規表現は、コンピュータが IP アドレス、UNC、電子メール アドレスなど、特定の形式の文字列を識別するのに役立ちます。適切に記述された正規表現を使用すると、Windows PowerShellTM スクリプトで有効なデータを許可したり、指定した形式に従っていない無効なデータを拒否したりできます。
単純な一致を検出する
Windows PowerShell の –match 演算子は、文字列を正規表現 (regex) と比較し、文字列が正規表現に一致するかどうかに応じて、True または False を返します。最も単純な正規表現は、特別な構文を使用せずに、リテラル文字だけで記述できます。次に例を示します。
"Microsoft" –match "soft"
"Software" –match "soft"
"Computers" –match "soft"
最初の 2 つの式を Windows PowerShell で実行すると True が返されますが、3 番目の式を実行すると False が返されます。どの式も、文字列の後に –match 演算子があり、その後に正規表現があります。既定では、正規表現は文字列全体を調べて一致を検出します。"soft" という文字は、Software と Microsoft の両方で検出されますが、それぞれ位置が異なります。また、既定では、正規表現は大文字と小文字を区別しません。"soft" は、大文字の S が使われている "Software" でも検出されます。
ただし、必要に応じて、–cmatch という別の演算子を使用して、次のように大文字と小文字を区別した正規表現との比較を実行できます。
"Software" –cmatch "soft"
大文字と小文字を区別した比較では、文字列 "soft" が "Software" と一致しないので、この式は False を返します。また、–match の既定の動作ではありますが、明示的に大文字と小文字を区別しない場合は、–imatch 演算子を利用できます。
ワイルドカードとリピータ
正規表現には、いくつかのワイルドカード文字を含めることができます。たとえば、ピリオド (.) は任意の 1 文字に一致します。疑問符 (?) は任意の 0 文字、または 1 文字に一致します。次に例を示します。
"Don" –match "D.n" (True)
"Dn" –match "D.n" (False)
"Don" –match "D?n" (True)
"Dn" –match "D?n" (True)
最初の式では、ピリオドが 1 文字に一致するので、True が返されます。2 番目の式では、ピリオドに対応する 1 文字が文字列に含まれていないので、False が返されます。3 番目と 4 番目の式が示すように、疑問符は任意の 1 文字または 0 文字に一致します。最後に、4 番目の式では、"D" と "n" の間に文字が存在しなくても、これらの文字は両方一致するので、True が返されます。このように、疑問符は省略可能な文字を表していると考えることができます。その位置に文字がない場合でも True が返されます。
また、正規表現ではアスタリスク (*) およびプラス記号 (+) がリピータとして認識されます。これらの記号の前には 1 文字以上を含める必要があります。アスタリスクは指定された文字列内の 0 文字以上に一致し、プラス記号は指定された文字列内の 1 文字以上に一致します。次にいくつか例を示します。
"DoDon" –match "Do*n" (True)
"Dn" -match "Do*n" (True)
"DoDon" -match "Do+n" (True)
"Dn" -match "Do+n" (False)
アスタリスクとプラス記号は、どちらも "o" だけでなく "Do" にも一致していることがわかります。これらのリピータは 1 文字だけではなく、一連の文字に一致するよう設計されているからです。
ピリオド、アスタリスク、疑問符、またはプラス記号自体を検索する場合はどうすればよいでしょうか。その場合は、これらの記号の前に、円記号を追加するだけです。円記号は正規表現のエスケープ文字です。
"D.n" -match "D\.n" (True)
これは Windows PowerShell のエスケープ文字 (アクサン グラーブ) とは異なりますが、業界標準の正規表現構文に準拠しています。
文字クラス
文字クラスはワイルドカードのより幅広い形式で、文字のグループ全体を表します。Windows PowerShell では、多くの文字クラスが認識されます。たとえば、次のような文字クラスがあります。
- \w は単語に使用される任意の文字、つまり文字と数字に一致します。
- \s はタブやスペースなどの任意の空白文字に一致します。
- \d は任意の数字に一致します。
また、否定の文字クラスもあります。\W は単語に使用される文字以外の任意の文字、\S は空白以外の文字、\D は数字以外の文字にそれぞれ一致します。これらのクラスの後にアスタリスクやプラス記号を記述して、複数の文字を許可するよう指定することができます。次にいくつか例を示します。
"Shell" -match "\w" (True)
"Shell" -match "\w*" (True)
今月のコマンドレット
Write-Debug コマンドレットは、テキスト文字列などのオブジェクトをデバッグ パイプラインに記述するのに非常に便利です。しかし、このコマンドレットをシェルで実行すると、何も処理が実行されていないように見えるため、がっかりするかもしれません。
種明かしをすると、これはデバッグ パイプラインが既定で無効になっているからです。変数 $DebugPreference は、"SilentlyContinue" に設定されています。ただし、この変数を "Continue" に設定すると、Write-Debug で送信したすべての内容がコンソールに黄色い文字で表示されます。この方法は、トレース コードをスクリプトに追加し、複雑なスクリプトの実行を追跡する場合に最適です。黄色は、スクリプトの追跡結果と通常の出力の区別に役立ちます。また、Write-Debug ステートメントをすべて削除することなく、いつでもデバッグ メッセージを無効にすることができます。もう一度 $DebugPreference = "SilentlyContinue" と設定するだけで、デバッグ テキストは表示されなくなります。
どちらの式も True を返しますが、一致する対象はまったく異なります。さいわい、–match 演算子が内部でどのように動作しているかを知る方法があります。検索が実行されるたびに、$matches という特別な変数に、検索結果、つまり演算子で比較された正規表現に一致した文字列内のすべての文字が格納されます。この $matches 変数は、–match 演算子を使用した別の肯定の検索が実行されるまで、値を保持します。図 1 は先ほど説明した 2 つの式の違いを示しています。ご覧のとおり、\w は "Shell" の "S" に一致しましたが、リピータが含まれた \w* は単語全体に一致しました。
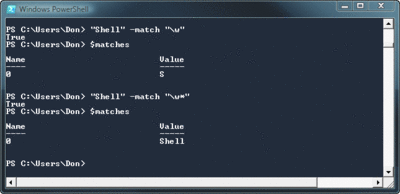
図 1** アスタリスクによる大きな違い **(画像を拡大するには、ここをクリックします)
文字グループ、範囲、およびサイズ
正規表現には、文字のグループや範囲を角かっこで囲んで含めることもできます。たとえば、[aeiou] は、角かっこの中に含まれているいずれかの文字 (a、e、i、o、または u) に一致することを意味します。[a-zA-Z] は、a ~ z または A ~ Z の任意の文字に一致することを表しています (ただし、大文字と小文字を区別しない –match 演算子を使用する場合は、a-z または A-Z をそれぞれ単独で使用するだけで同じ結果を得ることができます)。次に例を示します。
"Jeff" -match "J[aeiou]ff" (True)
"Jeeeeeeeeeeff" -match "J[aeiou]ff" (False)
また、中かっこで最小文字数と最大文字数を指定できます。{3} は指定した文字列のうち 3 文字、{3,} は 3 文字以上、{3,4} は 3 文字以上 4 文字以下に一致することを表しています。これは次のような IP アドレスの正規表現を作成するのに最適な方法です。
"192.168.15.20" -match "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}" (True)
この正規表現は、リテラル文字のピリオドで区切られた、それぞれ 1 桁から 3 桁までの数字で構成される 4 つのグループに一致します。しかし、次の例について考えてみましょう。
"300.168.15.20" -match "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}" (True)
これは正規表現の限界を示しています。この文字列の形式は IP アドレスのようですが、明らかに有効な IP アドレスではありません。正規表現では、データが実際に有効かどうかまでは判定できません。判定されるのは、データの見た目上の形式が適切かどうかだけです。
文字列全体を比較しないようにする
正規表現のトラブルシューティングは厄介な作業になる場合があります。たとえば、次の正規表現では、UNC パスが \\Server2\Share という形式で記述されているかどうかをテストしています。
"\\Server2\Share" -match "\\\\\w+\\\w+" (True)
ここでは、テスト対象であるリテラル文字の円記号をすべてもう 1 つの円記号でエスケープする必要があるため、読みにくい正規表現になります。この正規表現は正しく機能するように見えますが、実際は正しく機能しません。次に例を示します。
"57\\Server2\Share" -match "\\\\\w+\\\w+" (True)
この 2 番目の例は、(少なくとも皆さんと私にとっては) 明らかに有効な UNC パスではありませんが、正規表現ではまったく問題ないと判断されます。なぜでしょうか。正規表現は既定で文字列全体を比較することに注意してください。この正規表現では、単に 2 つの円記号、1 文字以上の文字または数字、もう 1 つの円記号、およびその後に続く文字または数字を検索しているだけです。文字列内にはこのパターンが存在しますが、先頭に不要な数字があるので、有効な UNC パスではありません。このため、正規表現に、文字列全体を比較するのではなく、文字列の最初の文字から比較を開始するよう指定することが重要です。これを行うには、次の式を使用します。
"57\\Server2\Share" -match "^\\\\\w+\\\w+" (False)
カレット (^) は、文字列の先頭を表します。カレットを追加した正規表現では、先頭の 2 文字が円記号である文字列を検索しますが、この場合は円記号ではないので、無効な UNC パスとして False が返されます。
同様に、ドル記号 ($) で文字列の末尾を指定できます。UNC パスの場合、この記号はそれほど便利ではありません。UNC パスでは、\\Server2\Share\Folder\File など、さらに深い階層を指定する場合があるからです。しかし、文字列の末尾を指定すると役立つ状況もたくさんあると思います。
正規表現のヘルプ
Windows PowerShell では、about_regular_expressions を指定すると表示されるヘルプ トピックで正規表現言語の基本的な構文を確認できますが、オンライン リソースではさらに多くの情報を入手できます。たとえば、www.RegExLib.com は私のお気に入りの Web サイトの 1 つです。このサイトでは、一般の人々がさまざまな目的で投稿した、正規表現の無料ライブラリが提供されています。"e-mail" (電子メール) や "UNC" などのキーワードで検索して、ニーズに合った正規表現、または少なくとも参考になる正規表現を簡単に探すことができます。すばらしい正規表現を作成できたときは、ライブラリに投稿して他の人に公開することもできます。
また、RegexBuddy (www.RegexBuddy.com) も私のお気に入りです。これはグラフィカルな正規表現エディタを提供する安価なツールです。RegexBuddy を利用すると複雑な正規表現を簡単に作成できます。また、正規表現をテストして、適切に有効な文字列が許可され、無効な文字列が拒否されているかどうかを簡単に確認できます。他の大勢のソフトウェア開発者も、無料、シェアウェア、および商用の正規表現エディタやテスト ツールを作成しており、これらは必ず皆さんの役に立つと思います。
正規表現を使用する
実際に正規表現を使う状況があるかどうか、疑問に思う人もいるでしょう。たとえば、CSV ファイルから情報を読み取り、その情報を使用して Active Directory® の新しいユーザーを作成する状況を想像してみてください。他のだれかが CSV ファイルを生成した場合、ファイルのデータが適切な形式で記述されているかどうかを検証する必要があります。正規表現はこのような作業に最適です。たとえば、\w+ のような単純な正規表現で、氏名に特殊文字や記号が含まれていないことを確認できます。さらに複雑な正規表現では、電子メール アドレスが社内基準を満たしているかどうかを確認できます。たとえば、次の正規表現を使用できます。
"^[a-z]+\.[a-z]+@contoso.com$"
この正規表現では、名と姓に文字だけが含まれていて、その間がピリオドで区切られている、don.jones@contoso.com のような形式で電子メール アドレスが構成されているかどうかを確認できます。ところで、電子メール アドレスは、正規表現を記述するのが最も難しい文字列です。特定の社内基準に絞り込むことができる場合、記述は簡単になります。
先頭と末尾の指定 (カレットとドル記号) を忘れないでください。これらの記号を含めることにより、"contoso.com" の後ろに何もなく、ユーザーの名を構成する文字の前にも何もない文字列を検出できます。
実際、Windows PowerShell で正規表現を使用するのは非常に簡単です。変数 $email に CSV ファイルから読み取った電子メール アドレスが含まれているとすると、次のような正規表現を使用して、電子メール アドレスが有効であるかどうかを確認できます。
$regex = "^[a-z]+\.[a-z]+@contoso.com$"
If ($email –notmatch $regex) {
Write-Error "Invalid e-mail address $email"
}
また、この例では新しい演算子が登場しています。-notmatch は、指定された正規表現に文字列が一致しない場合、True を返します (大文字と小文字を区別した比較を実行する –cnotmatch もあります)。
ここでは取り上げませんでしたが、正規表現については、他の文字クラス、高度な操作、演算子 (まだいくつかあります) など、説明することがまだたくさんあります。また、Windows PowerShell でサポートされている [regex] オブジェクト型についても説明が必要です。しかし、正規表現の作成を始めるには、この正規表現構文の概要で取り上げた内容を理解すれば十分です。非常に複雑な正規表現について悩んでいて、サポートが必要な場合は、いつでも www.ScriptingAnswers.com からご連絡ください。
Don Jones は TechNet Magazine の編集に携わっており、『Windows PowerShell: **TFM』(SAPIEN Press) の共著者でもあります。また、彼は Windows PowerShell に関するトレーニングの講師も勤めています (www.ScriptingTraining.com を参照)。ScriptingAnswers.com で公開されている Web サイトから、彼と連絡を取ることができます。
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; 許可なしに一部または全体を複製することは禁止されています.