SQL Server
SQL Server のブロッキングを最小限に抑える
Cherié Warren
概要:
- ロックのエスカレートが発生する理由
- 不要なブロッキングの発生を回避する
- クエリを最適化する
- ロックがパフォーマンスに与える影響を監視する
ロックは、データベースに対して同時に行われる読み取り操作と書き込み操作をサポートするために不可欠な処理ですが、ブロッキングはシステムのパフォーマンスに悪影響を及ぼす可能性があり、場合によっては、そのしくみは複雑です。この記事では、SQL Server 2005 データベースまたは SQL Server 2008 データベースを最適化してブロッキングの発生率を最小限に抑える方法、
およびシステムを監視してロックがパフォーマンスに与える影響を適切に把握する方法について説明します。
ロックとエスカレート
SQL Server® では、影響を受けるレコードの数、およびシステム上で行われる同時操作の種類に基づいて、最も適切なロックの粒度が選択されます。既定では、SQL Server では可能な限り最も粒度の細かいロックが選択されます。粒度の粗いロックが選択されるのは、システム メモリをより効果的に使用できる場合のみです。SQL Server では、全体的なシステムのパフォーマンスが向上すると判断された場合、ロックがエスカレートされます。エスカレートが発生するのは、特定のスキャンで検出されたロックの数が 5,000 個を上回った場合、またはシステムによってロックに使用されるメモリの量が、次のように使用可能な量を上回った場合です (図 1 参照)。
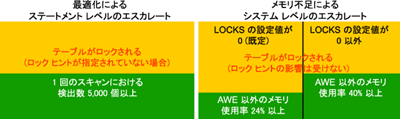
Figure 1** ロックのエスカレートが発生する条件 **(画像を拡大するには、ここをクリックします)
- locks の値が 0 に設定されているときに、データベース エンジンによって使用される Address Windowing Extensions (AWE) 以外のメモリの量が 24% を超えた場合
- locks が 0 以外の値に設定されているときに、データベース エンジンによって使用される AWE 以外のメモリの量が 40% を超えた場合
エスカレートが発生する場合、ロックは常にテーブル ロックになります。
不要なブロッキングの発生を回避する
ブロッキングはすべてのロックの粒度で発生しますが、エスカレートが発生すると、ブロッキングの発生率は高くなります。ロックのエスカレートが発生するということは、アプリケーションの設計、コーディング、または構成が効果的ではない可能性があります。
ブロッキングの発生を回避するには、データベースの設計が基本的な要件 (正規化されたスキーマと厳密なキーを使用する、トランザクション システムでデータの一括操作を実行しないようにするなど) を満たしている必要があります。このような原則に従わなかった場合 (トランザクション システムからレポート システムを分離する、業務時間外にデータ フィードを処理するなど)、システムのチューニングは困難になります。
インデックスは、データへのアクセスに必要なロックの数に大きく影響を与える可能性があります。インデックスによって、データベース エンジンが実行する内部参照の回数が減少するので、クエリがアクセスするレコードの数も減少します。たとえば、テーブルに格納されている、インデックスが作成されていない列から 1 つの行を選択する場合は、目的のレコードが特定されるまで、テーブル内の各行を一時的にロックする必要があります。これに対し、列にインデックスが作成されている場合、必要なロックは 1 つのみです。
SQL Server 2005 と SQL Server 2008 には、動的管理ビュー (sys.dm_db_missing_index_group_stats、sys.dm_db_missing_index_groups、sys.dm_db_missing_index_details) が含まれています。これらの動的管理ビューは、使用状況の累積統計情報に基づいて、インデックスからメリットを得ることができるテーブルと列を特定します。
データが断片化していると、データベース エンジンが多くのページにアクセスする必要があるので、パフォーマンスが低下する可能性があります。また、統計が適切でないことが原因で、クエリ オプティマイザがあまり効果的ではないプランを選択する可能性もあります。
インデックスを使用すると、データ アクセスの速度は向上しますが、データ変更の速度は低下することに注意してください。この理由は、基になるデータを変更するだけでなく、インデックスも更新する必要があるからです。動的管理ビューの sys.dm_db_index_usage_stats は、インデックスの使用頻度を示します。効率的でないインデックスの一般的な例としては、複合インデックスが挙げられます。つまり、同じ列に単独インデックスと複合インデックスの両方が作成されている場合です。SQL Server はインデックスの左から右へとアクセスするので、左端の列が有用であると判断された場合、その列に設定されているインデックスが使用されます。
テーブルをパーティション分割すると、システムを最適化できる (その結果ブロッキングの発生率が低下します) だけでなく、テーブルのデータを、個別にアクセスできる複数の物理オブジェクトに分割できます。行のパーティションを有効にするとデータを明示的に分割できますが、もう 1 つの選択肢として、データを行方向にパーティション分割することも考慮します。また、同時に複数の処理がデータへの排他アクセスする機会を減らすために、意図的に非正規化を行う場合もあります。つまり、1 つのテーブルを複数のテーブルに分割し、それぞれのテーブルに同数の行とキー、および異なる列を使用します。
アプリケーションが特定の行へのアクセスに使用する方法の種類、およびその行に含まれる列の数が多ければ多いほど、列のパーティション分割を使用する方法は魅力的です。場合によっては、アプリケーション キューと状態テーブルに関するメリットを得ることができます。SQL Server 2008 では、パーティション単位 (テーブルでパーティションが有効になっていない場合はテーブル単位) でロックのエスカレートを無効にする機能が追加されています。
クエリの最適化
パフォーマンスを強化するうえで、クエリの最適化は重要な役割を果たします。考えられる 3 つの方法を次に示します。
トランザクションのサイズを小さくする ブロッキングの発生回数を減らし、全体的なパフォーマンスを向上させる最も重要な方法の 1 つは、トランザクションのサイズをできるだけ小さくすることです。トランザクションの整合性にとって大きな問題にならない処理 (関連データの参照、インデックスの作成、データの最適化など) をすべて除外して、トランザクションのサイズを小さくする必要があります。
SQL は、各ステートメントを暗黙的なトランザクションとして扱います。ステートメントが大量の行に影響を与える場合、1 つのステートメントでも大きなトランザクションを構成する可能性があります (特に、大量の列が関与する場合や、列にサイズの大きなデータ型が含まれている場合)。また、FILL FACTOR に大きな値が設定されている場合や、UPDATE ステートメントが、割り当てられた範囲よりも大きな値を列に格納している場合、1 つのステートメントでもページの分割が発生する可能性があります。このような状況では、トランザクションを行のグループに分割し、1 つのグループの処理が完了してから次のグループの処理を実行するとよいでしょう。バッチ処理は、個々のステートメントまたはステートメントのグループを小さい (成功または失敗した場合に、1 つの作業単位として完了したと見なすことができる) バッチに分割できる場合のみ考慮することをお勧めします。
トランザクションを順序付ける トランザクション内のステートメントを意図的に順序付けることで、ブロッキングの発生率が低下する場合があります。このときに考慮する原則は 2 つあります。1 つ目は、すべての SQL コード内で、同じ順序を使用してシステム内のオブジェクトにアクセスすることです。順序に一貫性がない場合、2 つの競合する処理が異なる順序でデータにアクセスし、そのことが原因でデッドロックが発生する可能性があります。この場合、どちらかの処理でシステム エラーが発生します。2 つ目は、頻繁にアクセスするオブジェクト、またはアクセスに時間がかかるオブジェクトをトランザクションの最後に配置することです。SQL は、トランザクション内でオブジェクトが要求されるまで、それらのオブジェクトをロックしません。アクセスが集中するオブジェクトへのアクセスを遅延させることによって、これらのオブジェクトがロックを保持する時間を短縮できます。
ロック ヒントを使用する ロック ヒントは、特定のテーブルとビューにセッション レベルまたはステートメント レベルで使用できます。セッション レベルのヒントを使用する一般的なシナリオは、データ ウェアハウスのバッチ処理です。つまり、特定の時間にあるデータ セットに対して唯一実行されるのがそのバッチ処理であることを開発者が把握している場合です。ストアド プロシージャの冒頭で SET ISOLATION LEVEL READ UNCOMMITTED などのコマンドを使用すると、SQL Server は読み取りロックを予約しません。したがって、ロックによって発生する全体的なオーバーヘッドが軽減され、パフォーマンスが向上します。
ステートメント レベルのヒントを使用する一般的なシナリオとしては、ダーティ リードが安全に発生することを開発者が把握している場合 (テーブルから 1 つの行を読み取るとき、同時に実行される他の処理でその行が要求されない場合など) や、他のすべてのパフォーマンス チューニング作業 (スキーマの設計、インデックスの設計と管理、およびクエリのチューニング) が失敗し、コンパイラで特定の種類のヒントを使用する必要がある場合などが挙げられます。
行ロックのヒントを使用するシナリオは、より粒度の粗いロックが発生し、ほとんどのレコードがクエリの影響を受けない場合です。この場合、行ロックのヒントを使用することによって、ブロッキングの発生率を低下させることができます。テーブル ロックのヒントを使用するシナリオは、テーブル内のほぼすべてのレコードがクエリによる影響を受けず、より粒度の細かいロックが (エスカレートされずに) 発生する場合です。この場合、テーブル ロックのヒントを使用することによって、ロックの保持に必要なシステム リソースを削減することができます。ここで注意する必要があるのは、ロック ヒントを指定しても、ロックの数がシステム メモリのしきい値に達したときにロックがエスカレートされる場合があることです。ただし、ロック ヒントを指定すると、その他の場合に発生するすべてのエスカレートを回避することができます。
構成を調整する
図 2 が示すように、SQL Server システムを構成するときは、多くの要素を考慮する必要があります。
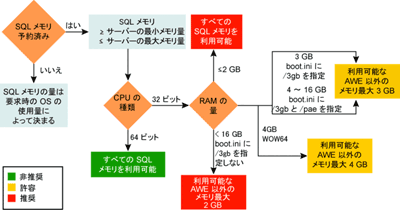
Figure 2** SQL Server がロックに使用するメモリの量を決定する流れ **(画像を拡大するには、ここをクリックします)
メモリ ロックは常に AWE 以外のメモリで保持されるので、AWE 以外のメモリ サイズを増加させれば、システムはより多くのロックを保持できるようになります。
より多くのロックを保持できるようにするには、まず 64 ビット アーキテクチャの導入を検討することをお勧めします。その理由は、32 ビット アーキテクチャでは AWE 以外のメモリが 4 GB に制限されるのに対し、64 ビットではまったく制限されないからです。
32 ビット システムでは、/3GB スイッチを Boot.ini ファイルに追加することによって、SQL Server に使用できるオペレーティング システムのメモリを 1 GB 増加させることができます。
SQL Server の構成設定 sp_configure を使用して、ロックに関連するさまざまな設定を調整できます。locks 設定を使用すると、エラーがスローされるまでにシステムが保持できるロックの数を構成できます。既定では、この値は 0 に設定されています。0 に設定されている場合、同時にメモリを要求した他の処理によって予約されるロックをサーバーが動的に調整します。SQL は最初に 2,500 個のロックを予約します。また、各ロックは 96 バイトのメモリを使用します。ページ メモリは使用されません。
min memory および max memory 設定を使用すると、SQL Server が使用するメモリの量を予約できます。つまり、メモリを静的に保持するようにサーバーを構成します。ロックのエスカレートが発生するかどうかは、使用可能なメモリの量によって決まるので、競合する他の処理用のメモリを予約することによって、エスカレートの発生率も変化する可能性があります。
接続設定 既定では、処理をブロックしているロックがタイムアウトすることはありませんが、@@LOCK_TIMEOUT 設定を使用すると、ロックを解放するまでの待機時間を指定して、その時間が経過したときにエラーを発生させることができます。
トレース フラグ 特にロックのエスカレートに関連しているトレース フラグは 2 つあります。1 つ目は、ロックのエスカレートを無効にするトレース フラグ 1211 です。使用可能な量を超えるメモリがロックに使用された場合、エラーがスローされます。もう 1 つは、ステートメント単位でロックのエスカレートを無効にするトレース フラグ 1224 です。
システムを監視する
関連資料
- インサイド Microsoft SQL Server 2005 (Kalen Delaney 著)**
- SQL Server 2005 および SQL Server 2000 のブロッキングを監視する方法
- SQL Server 2005 のパフォーマンス統計情報を取得するスクリプト
- SQL Server でロックのエスカレーションが原因で発生するブロッキング問題を解決する方法
- ロックのエスカレーション (データベース エンジン)
ブロッキングとロックがシステム全体のパフォーマンスに与える影響を監視するには、特定の間隔 (1 時間など) で状態データをポーリングし、保持されているロックの状態に関する統計情報をキャプチャします。キャプチャする重要な情報は、次のとおりです。
- 影響を受けるオブジェクト、粒度、およびロックの種類
- ロックとブロッキングの期間
- 発行された SQL コマンド (ストアド プロシージャ名、SQL ステートメントの内容)
- パフォーマンスに影響を与えるブロッキング チェーンの情報
- システムがロックに使用しているメモリの量
図 3 のようなスクリプトを実行してこの情報をキャプチャし、関連するタイムスタンプと共にテーブルに書き込むことができます。さらに、ブロックされているデータの ResourceId を確認するには、図 4 のようなスクリプトを実行します。
Figure 4 Learning more about blocked data
DECLARE @SQL nvarchar(max)
, @CallingResourceType varchar(30)
, @Objectname sysname
, @DBName sysname
, @resource_associated_entity_id int
-- TODO: Set the variables for the object you wish to look up
SET @SQL = N'
USE ' + @DbName + N'
DECLARE @ObjectId int
SELECT @ObjectId = CASE
WHEN @CallingResourceType = ''OBJECT''
THEN @resource_associated_entity_id
WHEN @CallingResourceType IN (''HOBT'', ''RID'', ''KEY'',''PAGE'')
THEN (SELECT object_id
FROM sys.partitions
WHERE hobt_id = @resource_associated_entity_id)
WHEN @CallingResourceType = ''ALLOCATION_UNIT''
THEN (SELECT CASE
WHEN type IN (1, 3)
THEN (SELECT object_id
FROM sys.partitions
WHERE hobt_id = allocation_unit_id)
WHEN type = 2
THEN (SELECT object_id
FROM sys.partitions
WHERE partition_id = allocation_unit_id)
ELSE NULL
END
FROM sys.allocation_units
WHERE allocation_unit_id = @resource_associated_entity_id)
ELSE NULL
END
SELECT @ObjectName = OBJECT_NAME(@ObjectId)'
EXEC dbo.sp_executeSQL
@SQL
, N'@CallingResourceType varchar(30)
, @resource_associated_entity_id int
, @ObjectName sysname OUTPUT'
, @resource_associated_entity_id = @resource_associated_entity_id
, @CallingResourceType = @CallingResourceType
, @ObjectName = @ObjectName OUTPUT
Figure 3 Capturing locking stats
SELECT er.wait_time AS WaitMSQty
, er.session_id AS CallingSpId
, LEFT(nt_user_name, 30) AS CallingUserName
, LEFT(ces.program_name, 40) AS CallingProgramName
, er.blocking_session_id AS BlockingSpId
, DB_NAME(er.database_id) AS DbName
, CAST(csql.text AS varchar(255)) AS CallingSQL
, clck.CallingResourceId
, clck.CallingResourceType
, clck.CallingRequestMode
, CAST(bsql.text AS varchar(255)) AS BlockingSQL
, blck.BlockingResourceType
, blck.BlockingRequestMode
FROM master.sys.dm_exec_requests er WITH (NOLOCK)
JOIN master.sys.dm_exec_sessions ces WITH (NOLOCK)
ON er.session_id = ces.session_id
CROSS APPLY fn_get_sql (er.sql_handle) csql
JOIN (
-- Retrieve lock information for calling process, return only one record to
-- report information at the session level
SELECT cl.request_session_id AS CallingSpId
, MIN(cl.resource_associated_entity_id) AS CallingResourceId
, MIN(LEFT(cl.resource_type, 30)) AS CallingResourceType
, MIN(LEFT(cl.request_mode, 30)) AS CallingRequestMode
-- (i.e. schema, update, etc.)
FROM master.sys.dm_tran_locks cl WITH (nolock)
WHERE cl.request_status = 'WAIT' -- Status of the lock request = waiting
GROUP BY cl.request_session_id
) AS clck
ON er.session_id = clck.CallingSpid
JOIN (
-- Retrieve lock information for blocking process
-- Only one record will be returned (one possibility, for instance,
-- is for multiple row locks to occur)
SELECT bl.request_session_id AS BlockingSpId
, bl.resource_associated_entity_id AS BlockingResourceId
, MIN(LEFT(bl.resource_type, 30)) AS BlockingResourceType
, MIN(LEFT(bl.request_mode, 30)) AS BlockingRequestMode
FROM master.sys.dm_tran_locks bl WITH (nolock)
GROUP BY bl.request_session_id
, bl.resource_associated_entity_id
) AS blck
ON er.blocking_session_id = blck.BlockingSpId
AND clck.CallingResourceId = blck.BlockingResourceId
JOIN master.sys.dm_exec_connections ber WITH (NOLOCK)
ON er.blocking_session_id = ber.session_id
CROSS APPLY fn_get_sql (ber.most_recent_sql_handle) bsql
WHERE ces.is_user_process = 1
AND er.wait_time > 0
SQL Server Profiler (Lock:Escalation イベント) や dm_db_index_operational_stats 動的管理ビュー (index_lock_promotion_count) を使用したり、定期的にシステムのロックに関する情報をポーリングすることによって、システムで発生するエスカレートを監視できます。エスカレートの監視では、特定の処理が原因でエスカレートが発生しているかどうかを調査します。特定の処理がエスカレートの原因ではない場合、関連するストアド プロシージャがパフォーマンスに関する問題の根本的な原因となっている可能性があります。また、最も重点的に評価する必要があるのは、大量のデータが格納されているテーブルや、同時に使用する頻度が高いテーブルです。
ロック、ブロッキング、およびエスカレートに関するデータを収集したら、それらのデータを分析して、発生したブロッキングとロックの累積時間をオブジェクト単位で確認できます (発生回数に発生期間を掛けて算出します)。これで通常は、変更の展開、監視、分析、および修正という作業から構成されるパフォーマンス チューニングのサイクルを開始できます。場合によっては、インデックスの追加などの簡単な変更を加えるだけで、大幅にパフォーマンスが向上したり、これまでとは異なる領域が、システムで最も大きなパフォーマンスのボトルネックになったりすることがあります。
SQL Server でのブロッキングの発生率を最小限に抑える方法については、補足記事「関連資料」を参照してください。設計、コーディング、および安定化という各段階で、トランザクションのサイズを抑えることに注意が向けられれば、ブロッキングに関する問題の発生率を最小限に抑えることができます。また、適切なハードウェアを使用することによって、不要なエスカレートが発生する可能性を大幅に低下させることができます。さらに、どのような場合でも、システムで発生するブロッキングを継続的に評価すれば、パフォーマンスに関する問題の根本的な原因をすばやく特定できます。
Cherié Warren は、Microsoft IT の上級開発責任者です。現在マイクロソフトで、非常に大規模なトランザクション データベースの開発を担当しています。ブロッキングの原因に関するコンサルティングを行ったり、ブロッキングによって発生するパフォーマンスの問題に対処したりすることもよくあります。10 年間にわたって、企業レベルの SQL Server データベースを専門とした業務に従事しています。
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; 許可なしに一部または全体を複製することは禁止されています.