SQL Server 2008
拡張イベントを使用した高度なトラブルシューティング
Paul S. Randal
概要:
- トラブルシューティングが必要な理由
- SQL Server のトラブルシューティング ツール
- 拡張イベントの概要とアーキテクチャ
- 拡張イベントを使用する
目次
SQL Server 2005 のトラブルシューティング
拡張イベント
パフォーマンスに関する考慮事項
イベントのライフサイクル
拡張イベントを使用する
system_health 拡張イベント セッション
まとめ
世界中の SQL Server DBA は、永遠に解決しないと思われる問題を抱えています。それは、トラブルシューティングです。このトラブルシューティングの大部分は、パフォーマンスに関する問題を解決する目的で行われます。最大限の注意を払って設計およびテストされたアプリケーション システムでも、時と共に変更が加えられ、それが原因でパフォーマンスが大幅に低下する可能性があります。
たとえば、ワークロード (同時接続ユーザー、実行するクエリ、月末報告書など) が変化したり、処理するデータの量が増加したりする可能性があります。また、システムを実行するハードウェア (プロセッサ コアの数、サーバー上の利用可能なメモリの量、I/O サブシステムの容量) が変化したり、新しい同時実行ワークロード (トランザクション レプリケーション、データベース ミラーリング、Change Data Capture など) が加わったりすることも考えられます。
ただし、問題はこれらに限定されません。アプリケーション システムを設計およびテストするときに、予想していなかった設計上の問題が見つかることはよくあり、その後のトラブルシューティングが必要になります。もちろん、アプリケーション ライフサイクルのどの段階で問題が見つかっても、トラブルシューティングを行って、その原因と解決方法を特定する必要があります。
複雑なアプリケーション システムでは、分析が必要になる可能性のある多くのハードウェアとソフトウェアが使用されますが、その中で私が携わっているのは SQL Server です。パフォーマンスのトラブルシューティングに使用されるさまざまな方法論については (この記事の範囲外のため) 取り上げませんが、SQL Server のトラブルシューティングに必要なツールについて見ていきましょう。
SQL Server 2005 のトラブルシューティング
SQL Server のここ数回のリリースの間に、パフォーマンスのトラブルシューティングに使用できるツールの数は大幅に増加しました。SQL Server では、データベース エンジンの各部分の状態を確認できる、大量のデータベース コンソール コマンド (DBCC) が常に提供されてきました。また、SQL Server Profiler を使用する方法や、基になる SQL トレース メカニズムをプログラムから使用する方法もあります。
SQL Server で提供されるトラブルシューティング ツールは継続的に強化されていますが、これらのツールにはいくつかの問題があります。まず、DBCC 出力の後処理は複雑で、出力された結果を使用するには、それらを一時テーブルにダンプする必要があります。また、SQL トレースと SQL Profiler が正しく構成されていない場合 (負荷の高いシステムですべての Lock: Acquired イベントと Lock: Released イベントをトレースし、各イベントの DatabaseId 列と ObjectId 列にフィルタを適用するのを忘れた場合など)、パフォーマンスが低下する可能性があります。図 1 のスクリーンショットは、新しいトレース用のフィルタを構成するためのダイアログ ボックスを示しています。
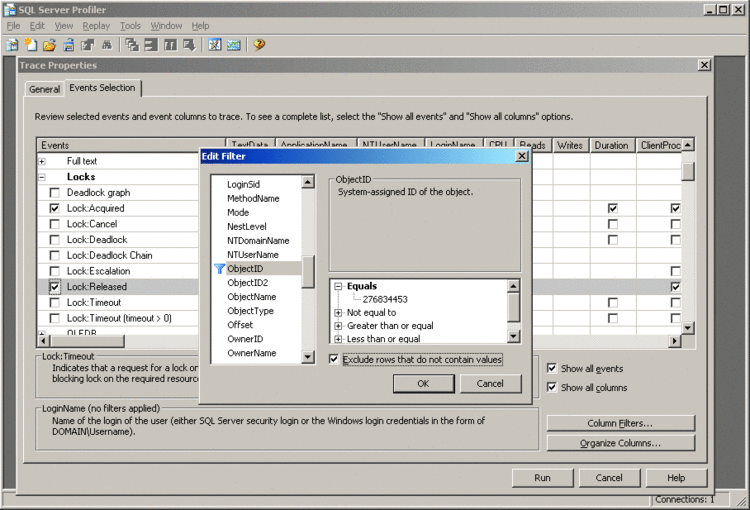
図 1 SQL Server 2008 Profiler でのフィルタの構成
SQL Server 2005 では、情報をデータベース エンジンから取得する方法として、動的管理ビューと動的管理関数 (まとめて DMV と呼ばれています) が追加されました。DMV は、いくつかの DBCC コマンド、システム テーブル、およびストアド プロシージャに取って代わる機能で、データベース エンジンのより多くの部分の状態を確認することを可能にします。DMV は構成可能な優れたコマンドで、複雑な T-SQL ステートメント内で使用することによって、DMV の結果にフィルタを適用し、後処理を実行できます。
たとえば、図 2 のコードは、データベースに含まれるすべてのインデックスの断片化とページ密度 (どちらも丸められます) をリーフ レベルで検出し、断片化レベルでフィルタを適用して返します。従来の DBCC SHOWCONTIG コマンドでは、このような結果を簡単に返すことはできません (DMV の詳細については、「動的管理ビューおよび関数 (Transact-SQL)」を参照してください)。また、SQL Server 2005 では、他にもデータ定義言語 (DDL) トリガやイベント通知など、トラブルシューティングに使用できるさまざまな機能が追加されました。
図 2 DMV を使用した役立つ結果の取得
SELECT
OBJECT_NAME (ips.[object_id]) AS 'Object Name',
si.name AS 'Index Name',
ROUND (ips.avg_fragmentation_in_percent, 2) AS 'Fragmentation',
ips.page_count AS 'Pages',
ROUND (ips.avg_page_space_used_in_percent, 2) AS 'Page Density'
FROM sys.dm_db_index_physical_stats (
DB_ID ('SQLskillsDB'), NULL, NULL, NULL, 'DETAILED') ips
CROSS APPLY sys.indexes si
WHERE
si.object_id = ips.object_id
AND si.index_id = ips.index_id
AND ips.index_level = 0 -- only the leaf level
AND ips.avg_fragmentation_in_percent > 10; -- filter on fragmentation
GO
マイクロソフトの各チームからも、パフォーマンスのトラブルシューティングに使用できる便利なツールが提供されました。たとえば、SQLdiag ユーティリティ、RML Utilities for SQL Server、SQL Server 2005 Performance Dashboard Reports、DMVStats などが挙げられます。さらに、SQL Server 2005 向けの Event Tracing for Windows (ETW) プロバイダも提供されています。このプロバイダを使用すると、SQL トレース イベントを Windows の他のコンポーネントのイベントと統合できるようになります。
SQL Server 2005 の登場によって、DBA はデータベース エンジンのトラブルシューティングを非常に行いやすくなりましたが、それでも DBA は、効率的にトラブルシューティングを行うことがほぼ不可能なシナリオに数多く直面しました。よく例として引き合いに出されますが、一部のクエリが過剰な量の CPU リソースを使用していても、DMV からは原因のアドホック クエリを正確に特定できるだけの情報が提供されません。ただし、SQL Server 2005 とは異なり、SQL Server 2008 では SQL Server 拡張イベントという新機能を使用して、そのような制約に対処できます。
拡張イベント
拡張イベント システムの容量は、これまでの SQL Server で提供されてきたイベント追跡およびトラブルシューティング メカニズムの容量をはるかに上回ります。私が考える拡張イベント システムの特徴は、次のとおりです。
- イベントは同期を取って開始されますが、そのイベントの処理は、同期を取って実行することも非同期に実行することもできます。
- どのターゲットでも任意のイベントを使用でき、どのアクションも任意のイベントと対応付けることができるので、厳重な監視システムが実現されます。
- "高度な" 述語を使用して、ブール ロジックを使用する複雑なルールを作成できます。
- Transact-SQL を使用して、拡張イベント セッションを完全に制御できます。
- パフォーマンスが重視されるコードを、パフォーマンスに影響を与えることなく監視できます。
先に進む前に、いくつかの新しい用語を簡単に定義します。
イベント イベントは、コード内で定義される特定の時点です。たとえば、T-SQL ステートメントの実行が完了した時点、ロックの取得が完了した時点などがあります。各イベントには定義済みのペイロード (イベントによって返される一連の列) が含まれます。これらのイベントは ETW モデル (どのイベントからもチャネルとキーワードがペイロードの一部として返されます) を使用して定義されているので、ETW と統合できます。SQL Server 2008 の最初のリリースでは 254 種類の定義済みイベントが提供されましたが、今後さらに追加されることが予想されます。
次のコードを使用すると、定義済みイベントの一覧を確認できます。
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'event'
ORDER BY xp.[name];
また、次のコードを使用すると、特定のイベントのペイロードを確認できます。
SELECT * FROM sys.dm_xe_object_columns
WHERE [object_name] = 'sql_statement_completed';
GO
拡張イベント システムでは、イベントやターゲットなどのあらゆる要素に関する説明が提供される、包括的な一連の情報 DMV を利用できます。詳細については、「SQL Server 拡張イベントの動的管理ビュー」を参照してください。
述語 述語は、イベントが使用される前に一連の論理的なルールを使用してイベントをフィルタ選択するための方法で、イベントのペイロードとして返されるいずれかの列に特定の値が含まれるかどうかの確認など、単純な操作に使用できます (たとえば、オブジェクト ID に基づいて、ロックを取得したイベントをフィルタ選択できます)。
また、述語を使用して高度な操作を行うこともできます。たとえば、セッション中に特定のイベントが発生した回数を数えたり、イベントの発生後にのみそのイベントの使用を許可したり、述語自体を動的に更新して、類似したデータを含むイベントの使用が発生しないようにしたりできます。
ブール ロジックを使用する述語を記述し、可能な限り処理を高速化することもできます。これにより、イベントを使用するかどうかを決定する前に実行される同期処理の量を最小限に抑えることができます。
アクション アクションは、イベントが使用される前に同期を取って実行される一連のコマンドです。どのアクションも任意のイベントに関連付けることができます。通常、アクションでは、データ (T-SQL スタックやクエリ実行プランなど) を収集するか、計算を実行して結果を取得し、それらをイベントのペイロードに追加します。
アクションはコストが高くなる可能性があるので、イベントに関連付けられたアクションは、いずれかの述語が評価された後にのみ実行されます。理由は、評価の結果、イベントが使用されないことになった場合、同期を取ってアクションを実行した意味がなくなるからです。次のコードを使用すると、定義済みアクションの一覧を確認できます。
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'action'
ORDER BY xp.[name];
ターゲット ターゲットでは単純に、イベントを使用する方法が提供されます。どのターゲットでも任意のイベントを使用できます (少なくとも、ターゲットで実行する処理がない場合にイベントを破棄することはできます。たとえば、監査ターゲットが監査以外のイベントを受け取った場合などがあります)。ターゲットでは、同期を取ってイベントを実行する (イベントを開始したコードがイベントの使用を待機する場合など) ことも、非同期にイベントを実行することもできます。
イベント ファイルやリング バッファなどの単純なコンシューマから、イベントを組み合わせることができる複雑なコンシューマまで、さまざまなターゲットがあります。次のコードを使用すると、使用可能なターゲットの一覧を確認できます。
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'target'
ORDER BY xp.[name];
ターゲットの詳細については、「SQL Server 拡張イベント ターゲット」を参照してください。
パッケージ パッケージは、拡張イベント オブジェクト (イベント、アクション、ターゲットなど) を定義するコンテナで、そのパッケージを記述するモジュール (実行可能ファイルや DLL など) 内に格納されます (図 3 参照)。
.gif)
図 3 モジュール、パッケージ、および拡張イベント オブジェクトの関係
パッケージが拡張イベント エンジンに登録されると、そのパッケージによって定義されるすべてのオブジェクトが使用可能になります。パッケージについて、および拡張イベントに関する用語の定義については、「SQL Server 拡張イベント パッケージ」を参照してください。
セッション セッションは、複数の拡張イベント オブジェクトを関連付けて処理する方法の 1 つで、ターゲットによって使用されるアクションを含むイベントです。セッションでは、登録された任意のパッケージに含まれるオブジェクトを関連付けることができます。また、同じイベントやアクションなどを、任意の数のセッションで使用できます。次のコードを使用すると、定義済みの拡張イベント セッションを確認できます。
SELECT * FROM sys.dm_xe_sessions;
Go
セッションを作成、削除、変更、および停止するには、T-SQL コマンドを使用します。ご想像のとおり、これによって高い柔軟性が提供されるだけでなく、セッションによってキャプチャされるデータをプログラムで分析し、その結果に基づいて動的にセッションを変更できるようになります。セッションの詳細については、「SQL Server 拡張イベント セッション」を参照してください。
パフォーマンスに関する考慮事項
CREATE EVENT SESSION を使用して拡張イベント セッションを作成するときに、いくつかの設定を注意深く正確に構成しなかった場合、予期せずパフォーマンスが低下する可能性があります。まず判断することは、同期を取ってイベントを使用するか、非同期にイベントを使用するかです。ご想像のとおり、同期ターゲットの方が、非同期ターゲットよりも、監視するコードのパフォーマンスに大きな影響を与えます。
先ほど説明したように、同期を取ってイベントを使用する場合、そのイベントを開始したコードは、イベントが使用されるまで待機する必要があります。イベントの使用が複雑な処理である場合、当然コードのパフォーマンスは低下します。
たとえば、1 秒間に小規模なトランザクションを何千件も処理する負荷の高いシステムで sql_statement_completed イベントが発生したときに、そのイベントを使用してクエリ プランをキャプチャするアクションを実行すると、非常に高い確率でパフォーマンスが低下します。また、述語は常に同期を取って実行されるので、パフォーマンスを重視するコードによって開始されるイベント用に、あまり複雑な述語を作成しないようにしてください。
一方、同期を取ってイベントを使用せざるを得ない場合もあります。特定のイベントの発生回数を数えるための最も簡単な方法は、おそらく synchronous_event_counter ターゲットを使用することです。
2 つ目の考慮事項は、非同期ターゲットを使用するときに、イベントのバッファ処理をどのように構成するかです。既定では、イベントのバッファ処理に使用できるメモリの量は 4 MB です。また、ターゲットがイベントを開始してから使用するまでの間に発生するディスパッチ待機時間の既定値は 30 秒です。たとえば、10 秒ごとにイベントに関するなんらかの統計情報を生成する場合は、この待機時間を調整する必要があります。
イベントのバッファ処理に関する設定を構成することは、イベントのバッファ処理に使用するメモリのパーティション分割方法を決定することを意味します。既定では、インスタンス全体に対して 1 つのバッファ群が作成されます。対称マルチプロセッサ (SMP) および NUMA (Non-uniform Memory Access) コンピュータでこの構成を使用すると、プロセッサがメモリへのアクセスを待機する必要が生じるので、パフォーマンスが低下する可能性があります。
3 つ目の考慮事項は、イベントの損失にどのように対処するかです。拡張イベント セッションを定義する場合、イベントが失われてもよいかどうか、つまり、イベントをバッファ処理できるだけのメモリがない場合、そのイベントを単純に破棄してもよいかどうかを指定できます。既定では、1 つのイベントが破棄されますが、バッファ処理されたイベントをすべて同時に破棄 (イベント バッファがすぐにいっぱいになる場合) したり、イベントを破棄しないように指定したりすることもできます。
最後のオプションを指定した場合、イベントを格納するバッファ メモリに空きが生じるまで、そのイベントを開始したコードが待機する必要があることに注意してください。このオプションを指定すると、ほぼ確実にパフォーマンスが低下します。ただし、誤ってこのオプションを指定した場合でも、その指定を解除できないほどサーバーの応答が遅くなることはありません。
通常は、3 つの設定をすべて考慮した方がよいでしょう。あまり一般的なベスト プラクティスは存在せず、私に言えるのは、これらの設定を考慮しなければパフォーマンスが低下する可能性があることだけです。これらの設定の詳細については、「CREATE EVENT SESSION (T-SQL)」を参照してください。
イベントのライフサイクル
拡張イベント セッションが定義および開始されると、監視対象のコード内でイベントが発生するまで、通常どおり処理が続行されます。図 4 は、拡張イベント システム内で発生する手順を大まかに示しています。これらの手順は、次のとおりです。
- いずれかの拡張イベント セッションによって特定のイベントが監視されているかどうかを確認します。監視されていない場合は、そのイベントを含むコードに制御を返し、処理を続行します。
- イベントのペイロードを特定し、必要な情報をメモリ内に収集します。つまり、イベントのペイロードを構築します。
- イベント用の述語が定義されている場合は、それらを実行します。ここで、述語の結果として、イベントを使用しないことが決定される場合もあります。その場合は、イベントを含むコードに制御を返し、処理を続行します。
- イベントが使用されることをシステムが認識し、そのイベントに関連付けられたすべてのアクションを実行します。ペイロードは完成していて、イベントは使用可能な状態になっています。
- 同期ターゲットが存在する場合、イベントをそれらのターゲットに提供します。
- 非同期ターゲットが存在する場合、イベントを後で処理するためにバッファに格納します。
- イベントを含むコードに制御を返し、処理を続行します。
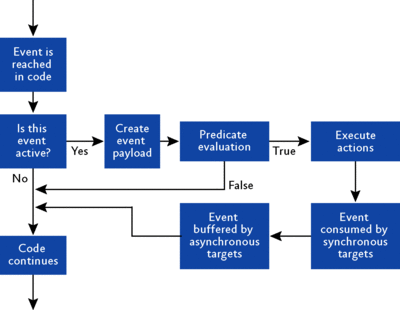
図 4 拡張イベントのライフサイクル (画像をクリックすると拡大表示されます)
先ほど説明したように、イベント セッションを作成するときは、同期アクションや非同期ターゲット用のバッファ処理によって、監視対象のコードのパフォーマンスが低下しないようにする必要があります。
拡張イベントを使用する
SQL Server 2008 オンライン ブックでは、拡張イベントの使用例が 2 つ提供されています。これらは、「ロックを保持しているクエリを特定する方法」と「ロックの大半を取得しているオブジェクトを見つける方法」です。
ここからは、拡張イベント セッションの構成と結果の分析に関する例を紹介します。2007 年の終わりに拡張イベントを使い始めたときにわかったことですが、単純なセッションは非常に簡単に (単純な T-SQL DDL ステートメントを使用して) 作成できます。ただし、その結果を分析する作業は簡単ではありません。
まず、私は結果が XML で提供されることに驚いた後、非常にさまざまなイベントとアクションの組み合わせを 1 つのセッションに含めることができることを知り、これほどまでに拡張性の高いスキーマを格納できる方法は他に存在しないのではないかと強く思いました。
そして私は何年もの間 SQL Server ストレージ エンジン チームの開発者を務め、今では C、C++、およびアセンブリ プログラマとしての技能にも習熟していると思いますが、イベントのペイロードに含まれるフィールドを XML データから抽出するコードを考え出すのには数時間かかりました。拡張イベントを使用しないよう皆さんを説得しているのではなく、XML データの使用に慣れていない場合は、結果を分析する前に少し学習期間が必要であることを伝えたいだけです。
ここで私のシナリオを紹介します。DBA である私は、SQL Server 2008 のリソース ガバナ機能を使用して、社内に設置されている運用サーバーのうちの 1 台で管理しているさまざまなグループをサンドボックス化します。私は Development と Marketing という 2 つのリソース ガバナ リソース プールを作成することによって、このサーバーを使用するチームをそれぞれ表現しました。リソース ガバナを使用すると、プールごとに CPU 使用率とクエリ実行時のメモリ使用量を制限できますが、各プールで使用される I/O リソースの量は制限できません。そこで、新しいストレージ エリア ネットワーク (SAN) にアップグレードするためのコストを償却するときに役立つ入金相殺メカニズムを作成し、サーバー上の I/O リソースの使用状況に応じて各チームに請求を行うことにします。
私は、I/O 情報のキャプチャを最も簡単に開始できるタイミングは、いずれかの T-SQL ステートメントが完了したときであると考えています。また、package0 パッケージに sql_statement_completed というイベントが含まれることも知っています。では、このイベントによってどのようなデータが収集され、ペイロードに含まれるのでしょうか。
次のコードを実行すると、読み取りと書き込みの両方を含むすべてのデータの一覧を確認できます。
SELECT [name] FROM sys.dm_xe_object_columns
WHERE [object_name] = 'sql_statement_completed';
GO
ここで返されるのは、物理的な読み取りと書き込み (メモリ内のバッファ プールではなくディスクに対するデータの読み取りと書き込み) ではないと思いますが、各チームによって使用される I/O リソースの比率はわかります。
ここでは、どのチームが特定の T-SQL ステートメントを実行したかを知る必要があるので、その情報を取得できるアクションが必要です。次のコードを実行すると、イベントが発生したときに実行できるすべてのアクションが返されます。これには、sqlserver パッケージの session_resource_pool_id を収集するアクションも含まれます。
SELECT xp.[name], xo.*
FROM sys.dm_xe_objects xo, sys.dm_xe_packages xp
WHERE xp.[guid] = xo.[package_guid]
AND xo.[object_type] = 'action'
ORDER BY xp.[name];
これで、リソース ガバナ用に定義したリソース プールの一覧を取得し、その一覧を拡張イベント セッションによって収集される ID と関連付ける方法がわかりました。次はセッションを定義します。まず、同じ名前のイベント セッションが存在するかどうかを確認します。存在する場合、そのセッションを破棄します。これを行うためのコードは、次のとおりです。
IF EXISTS (
SELECT * FROM sys.server_event_sessions
WHERE name = 'MonitorIO')
DROP EVENT SESSION MonitorIO ON SERVER;
GO
CREATE EVENT SESSION MonitorIO ON SERVER
ADD EVENT sqlserver.sql_statement_completed
(ACTION (sqlserver.session_resource_pool_id))
ADD TARGET package0.ring_buffer;
GO
次に、sql_statement_completed イベントが発生したときに session_resource_pool_id を収集するアクションを実行する、新しいセッションを作成します。まだプロトタイプの作成中なので、結果はすべてリング バッファに記録します (運用環境では、おそらく非同期のファイル ターゲットを使用するでしょう)。
セッションを開始するには、次のコードを実行する必要があります。
ALTER EVENT SESSION MonitorIO ON SERVER
STATE = START;
GO
これでセッションが開始されます。
マーケティング チームと開発チームがなんらかの操作を行ったら、セッションの結果を分析します。次のコードを実行すると、リング バッファからデータが抽出されます。
SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO';
GO
ただし、抽出されるデータは 1 つの大きな XML 値です。このデータをさらに分解するには、図 5 のようなコードを使用します。
図 5 XML データの分解
SELECT
Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads,
Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes,
Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID
FROM
(SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO') Statements
CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results);
GO
このコードは成功しますが、キャプチャされたイベントごとに 1 行のデータが出力されます。これはあまり便利な形式ではなく、集計された結果を出力した方がよいと考えたので、派生テーブルを使用することにしました (図 6 参照)。
図 6 集計された出力の取得
SELECT DT.ResourcePoolID,
SUM (DT.Reads) as TotalReads,
SUM (DT.Writes) AS TotalWrites
FROM
(SELECT
Data2.Results.value ('(data/.)[6]', 'bigint') AS Reads,
Data2.Results.value ('(data/.)[7]', 'bigint') AS Writes,
Data2.Results.value ('(action/.)[1]', 'int') AS ResourcePoolID
FROM
(SELECT CAST(xest.target_data AS XML) StatementData
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xest.target_name = 'ring_buffer'
AND xes.name = 'MonitorIO') Statements
CROSS APPLY StatementData.nodes ('//RingBufferTarget/event') AS Data2 (Results)) AS DT
WHERE DT.ResourcePoolID > 255 –- only show user-defined resource pools
GROUP BY DT.ResourcePoolID;
GO
ふう。確かに少し複雑なコードも含まれていますが、適切に機能します。これで目的の結果を入手できました。図 7 は、テスト データに対するこのクエリの出力を示しています。
| 図 7 クエリの結果 |
| ResourcePoolID | TotalReads | TotalWrites |
| 256 | 3831 | 244 |
| 257 | 5708155 | 1818 |
リソース プール 256 がマーケティング チームで、257 が開発チームです。上記の数字は、社内チームの予想されるデータベース操作の量として、納得のいく結果でした。このような結果をこれほど簡単に得ることができたのも、拡張イベントを使用したからです。
最後に、次のコードを使用してセッションを停止する必要があります。
ALTER EVENT SESSION MonitorIO ON SERVER
STATE = STOP;
GO
この例の各段階における出力の詳細については、この記事に付属しているスクリーンキャストを参照してください。このスクリーンキャストは、technetmagazine.com/video で公開されています。
system_health 拡張イベント セッション
実は SQL Server 2008 には、既定で実行するように設定された定義済みのセッションが付属しています。そのセッションの名前は system_health です。これは製品サポート チームの発案によって組み込まれたセッションで、デッドロックや重大度の高いエラーが発生した場合などに行うユーザー システムのデバッグによく使用される情報を追跡します。このセッションは、SQL Server 2008 インスタンスのインストール処理の一環として作成および開始され、あまり多くのメモリを使用せずに、リング バッファ内のイベントを追跡します。
次のコードを使用すると、リング バッファの内容を確認できます。
SELECT CAST (xest.target_data AS XML)
FROM sys.dm_xe_session_targets xest
JOIN sys.dm_xe_sessions xes ON
xes.address = xest.event_session_address
WHERE xes.name = 'system_health';
GO
このセッションによって追跡される情報の詳細については、マイクロソフト PSS の SQL サポート部門が公開しているブログを参照してください。
まとめ
聞くところによると、SQL Server チームは今後さらに多くのイベントを sqlserver.exe に追加することを計画しているそうです。実際、その数は 2007 年 2 月版 CTP (Community Technology Preview) リリースの 165 個から、製品版 (RTM) リリースの 254 個へと急増しました。
Change Data Capture (TechNet Magazine 2008 年 11 月号の記事「企業データベースの変更を追跡する」で取り上げました)、データ圧縮、インデックス ページ分割など、調査すると非常に面白そうなイベントもいくつかあります。インデックス ページ分割は、すべてのインデックスに sys.dm_db_index_physical_stats DMV を定期的に実行することなく、パフォーマンス低下の原因となる断片化を作り出すインデックスを特定するための方法として期待できます。
全体的に見て、新しい拡張イベント システムを使用すると、これまで絶対に不可能であった非常に高度な監視を実行できるようになります。データを取得するための XML 解析について少し学習する必要はありますが、この新しいシステムから得られるメリットは、コーディングに使用する新しい構造体について学習する苦労をはるかにしのぎます。
拡張イベントの概要を紹介したこの記事によって、拡張イベントに興味を持ち、このイベントを使用して何が実現できるかを知っていただけたでしょうか。皆さんのトラブルシューティングが成功することを願っています。いつものように、ご意見やご質問は Paul@SQLskills.com (英語のみ) までお寄せください。
Paul S. Randal は SQLskills.com の代表取締役であり、SQL Server MVP でもあります。1999 年から 2007 年までは、マイクロソフトの SQL Server ストレージ エンジン チームに所属していました。また、『DBCC CHECKDB/repair for SQL Server 2005』を執筆し、SQL Server 2008 の開発時にはコア ストレージ エンジンを担当していました。Paul は障害回復、高可用性、およびデータベース メンテナンスの専門家であり、世界中のカンファレンスで定期的に発表を行っています。彼のブログは SQLskills.com/blogs/paul で公開されています。