Azure Data Studio を使用して SQL Server ビッグ データ クラスターに接続する
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
この記事では、Azure Data Studio から SQL Server 2019 ビッグ データ クラスターに接続する方法について説明します。
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
前提条件
- 展開済みの SQL Server 2019 ビッグ データ クラスター。
- SQL Server 2019 ビッグ データ ツール:
- Azure Data Studio
- SQL Server 2019 の拡張機能
- kubectl
- azdata
クラスターに接続する
Azure Data Studio を使用してビッグ データ クラスターに接続するには、クラスター内の SQL Server マスター インスタンスへの新しい接続を作成します。 次にその方法を示します。
SQL Server マスター インスタンス エンドポイントを探します。
azdata bdc endpoint list -e sql-server-masterヒント
エンドポイントを取得する方法の詳細については、「エンドポイントを取得する」を参照してください。
Azure Data Studio で、F1 キー>[新しい接続] から新しい接続を作成します。
[接続の種類] で [Microsoft SQL Server] を選択します。
SQL Server マスター インスタンスに対して見つかったエンドポイント名を [サーバー名] テキスト ボックスに入力します (例: <IP_Address>,31433)。
認証の種類を選択します。 ビッグ データ クラスターで実行されている SQL Server マスター インスタンスの場合は、Windows 認証と SQL ログインのみがサポートされます。
SQL ログインを使用している場合、SQL ログインの [ユーザー名] と [パスワード] を入力します。
ヒント
既定では、ユーザー名 SA は、ビッグ データ クラスターの展開の間に無効になります。 新しい sysadmin ユーザーは、展開前または展開時に設定される、AZDATA_USERNAME 環境変数に対応する名前と AZDATA_PASSWORD 環境変数に対応するパスワードを使用して、展開中にプロビジョニングされます。
ターゲットの [データベース名] を、使用しているリレーショナル データベースのいずれかに変更します。
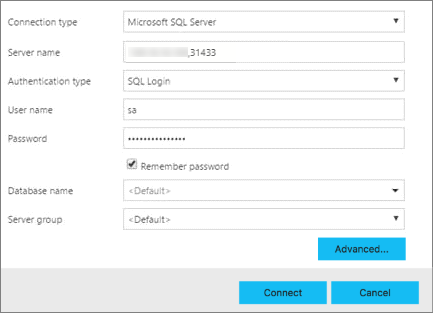
[接続] をクリックすると、サーバー ダッシュボードが表示されます。
Azure Data Studio の 2019 年 2 月リリースでは、SQL Server マスター インスタンスに接続することで、HDFS/Spark ゲートウェイを操作することもできます。 これは、次のセクションで説明する HDFS および Spark 用に別の接続を使用する必要がないことを意味します。
オブジェクト エクスプローラーに、新しいノートブックの作成や Spark ジョブの送信などのビッグ データ クラスター タスクの右クリック サポートを備えた、新しい [Data Services] ノードが追加されました。
[Data Services] ノードには HDFS フォルダーも含まれていて、HDFS のコンテンツを調べ、HDFS に関連する共通タスク (外部テーブルの作成やノートブックを開いて HDFS のコンテンツを分析するなど) を実行できます。
接続のサーバー ダッシュボードには、拡張機能がインストールされている場合、SQL Server ビッグ データ クラスターと SQL Server 2019 のタブも含まれています。
![Azure Data Studio の [Data Services] ノード](media/connect-to-big-data-cluster/connect-data-services-node.png?view=sql-server-ver15)
次のステップ
SQL Server 2019 ビッグ データ クラスターの詳細については、「SQL Server 2019 ビッグ データ クラスターとは」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示