SQL Server ビッグ データ クラスターの展開のために複数のマシン上に Kubernetes を構成する
適用対象: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
この記事では、kubeadm を使用して、SQL Server ビッグ データ クラスター の展開のために複数のコンピューター上に Kubernetes を構成する方法の例を示します。 この例では、複数の Ubuntu 16.04 または 18.04 LTS マシン (物理または仮想) を対象とします。 別の Linux プラットフォームに展開する場合は、お使いのシステムに合わせてコマンドの一部を変更する必要があります。
ヒント
Kubernetes を構成するサンプル スクリプトについては、「Ubuntu 20.04 LTS 上で Kubeadm を使用して Kubernetes クラスターを作成する」を参照してください。
また、VM 上での単一ノードの kubeadm の展開を自動化して、その上にビッグ データ クラスターの既定の構成を展開するサンプル スクリプトについては、単一ノードの kubeadm クラスターの展開に関する記事を参照してください。
前提条件
- 最低 3 台の Linux 物理マシンまたは仮想マシン
- マシンごとに推奨される構成:
- 8 個の CPU
- 64 GB のメモリ
- 100 GB のストレージ
重要
ビッグ データ クラスターの展開を開始する前に、展開の対象となっているすべての Kubernetes ノード間でクロックが同期されていることを確認します。 ビッグ データ クラスターには、時間の影響を受け、時計のずれが原因で不正な状態になる可能性があるさまざまなサービス用に、正常性プロパティが組み込まれています。
マシンを準備する
各マシンには、必須の前提条件がいくつかあります。 bash 端末で、各マシン上で次のコマンドを実行します。
現在のマシンを
/etc/hostsファイルに追加します。echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsすべてのデバイスでのスワップを無効にします。
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aキーをインポートし、Kubernetes 用のリポジトリを登録します。
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listマシン上に docker と Kubernetes の前提条件を構成します。
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashnet.bridge.bridge-nf-call-iptables=1を設定します。 Ubuntu 18.04 の場合は、次のコマンドで最初にbr_netfilterが有効にされます。. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Kubernetes マスターを構成する
各マシン上で上記のコマンドを実行した後、Kubernetes マスターにするマシンを 1 つ選択します。 その後、そのマシン上で次のコマンドを実行します。
まず、次のコマンドを使用して、現在のディレクトリに rbac. yaml ファイルを作成します。
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFこのマシン上で Kubernetes マスターを初期化します。 次のサンプル スクリプトでは、Kubernetes バージョン
1.15.0を指定しています。 使用するバージョンは、Kubernetes クラスターによって異なります。KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONKubernetes マスターが正常に初期化されたことを示す出力が表示されます。
Kubernetes クラスターに参加するために、他のサーバー上で使用する必要がある
kubeadm joinコマンドに注意してください。 後で使用するために、これをコピーします。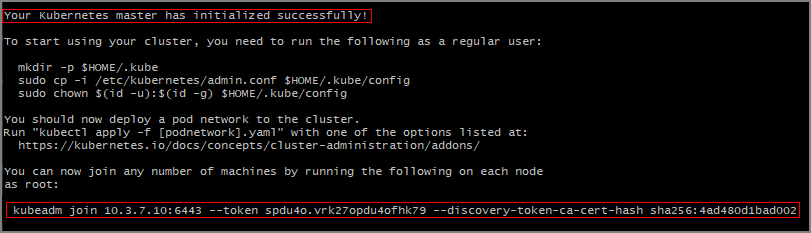
ホーム ディレクトリに Kubernetes 構成ファイルを設定します。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configクラスターと Kubernetes ダッシュボードを構成します。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Kubernetes エージェントを構成する
他のマシンは、クラスターでの Kubernetes エージェントとして機能します。
他の各マシン上で、前のセクションでコピーした kubeadm join コマンドを実行します。

クラスターの状態を表示する
クラスターへの接続を確認するには、クラスター ノードの一覧を返す kubectl get コマンドを使用します。
kubectl get nodes
次のステップ
この記事の手順では、複数の Ubuntu マシン上に Kubernetes クラスターを構成しました。 次のステップとして、SQL Server 2019 ビッグ データ クラスターを展開します。 手順については、次の記事を参照してください。