SQL Server ビッグ データ クラスター で Spark の機械学習モデルを作成、エクスポート、およびスコア付けする
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
次のサンプルでは、Spark の ML でモデルを作成し、そのモデルを MLeap にエクスポートし、SQL Server で Java 言語拡張機能 を使用してそのモデルをスコア付けする方法を示します。 これは、SQL Server ビッグ データ クラスターのコンテキストで行われます。
次の図は、このサンプルで実行される作業を示しています。
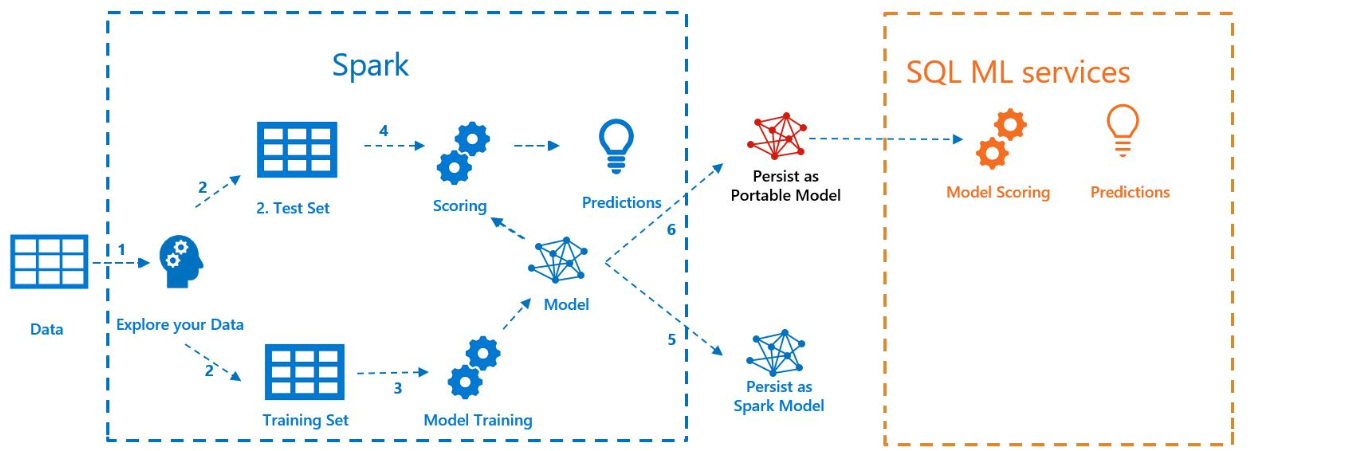
前提条件
このサンプルのすべてのファイルは、https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml にあります。
サンプルを実行するには、以下のコンポーネントが必要になります。
-
- kubectl
- curl
- Azure Data Studio
Spark の ML を使用したモデル トレーニング
このサンプルでは、国勢調査データ (AdultCensusIncome.csv) を使用して Spark の ML パイプライン モデルを作成します。
mleap_sql_test/setup.sh ファイルを使用して、データ セットをインターネットからダウンロードし、SQL Server ビッグ データ クラスターの HDFS に配置します。 これにより、Spark からアクセスできるようになります。
次に、サンプルのノートブック train_score_export_ml_models_with_spark.ipynb をダウンロードします。 PowerShell または Bash コマンド ラインから、次のコマンドを実行してノートブックをダウンロードします。
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"このノートブックには、サンプルのこのセクションに必要なコマンドを含むセルが含まれています。
Azure Data Studio でノートブックを開き、各コード ブロックを実行します。 ノードブックの操作に関する詳細については、SQL Server でノートブックを使用する方法に関するページを参照してください。
データはまず Spark に読み取られ、トレーニング データ セットとテスト データ セットに分割されます。 次に、トレーニング データを使用してパイプライン モデルをトレーニングします。 最後に、モデルを MLeap バンドルにエクスポートします。
ヒント
mleap_sql_test/mleap_pyspark.py ファイルのノートブックの外部で、これらの手順に関連付けられている Python コードを確認または実行することも可能です。
SQL Server を使用したモデルのスコアリング
Spark の ML パイプライン モデルが共通のシリアル化 MLeap バンドル形式になったため、Spark がなくても Java でモデルをスコア付けすることができます。
このサンプルでは、SQL Server の Java 言語拡張機能を使用します。 SQL Server でモデルをスコア付けするために、まず、Java にモデルを読み込んでスコアを付けることができる Java アプリケーションをビルドする必要があります。 この Java アプリケーションのサンプル コードは、mssql-mleap-app フォルダーにあります。
サンプルをビルドした後、Transact-SQL を使用して Java アプリケーションを呼び出し、データベース テーブルを使用してモデルをスコア付けすることができます。 これは、mleap_sql_test/mleap_sql_tests.py ソース ファイルで確認できます。
次のステップ
ビッグ データ クラスターの詳細については、Kubernetes に SQL Server ビッグ データ クラスター を展開する方法に関するページを参照してください
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示