Always On 可用性グループのリース、クラスター、正常性チェック タイムアウトのしくみとガイドライン。
ハードウェア、ソフトウェア、クラスターの構成に応じて、また、稼働時間やパフォーマンスに関するアプリケーション要件に応じて、リース、クラスター、正常性チェック タイムアウトの値を構成する必要があります。 特定のアプリケーションやワークロードでは、ハード エラー後のダウンタイムを制限するためにより積極的な監視が必要になります。 その他のアプリケーションやワークロードでは、リソースの使用量が多いために発生する一時的なネットワークの問題や待機時間に対する許容範囲を広げる必要があり、低速のフェールオーバーでよい場合があります。
各ノードの複数のサービスはエラーを検出するために機能します。 クラスター サービスではクォーラム損失が検出され、リソース DLL では、Always On 正常性検出で確認される問題が検出されることがあります。あるいは、プライマリ インスタンスで直接手動フェールオーバーが開始される可能性があります。 クラスター サービス、リソース ホスト、および SQL Server インスタンスは、RPC、共有メモリ、T-SQL を介して相互に同期します。 ほとんどのシナリオでは、これらのサービスは正常に通信しますが、この通信は、同じマシン上のサービス間であっても完全に信頼することはできません。 さらに、可用性グループ (AG) は、通信や機能を妨げる可能性のある、ネットワーク エラーやディスク エラーなど、システム全体のイベントに対応できる必要があります。 サービス間の通信が完全に信頼できない状態で、多くのエラーが発生した場合、AG はさまざまなフェールオーバー検出メカニズムに依存してエラーを検出し、個別にエラーに対応して、すべてのノードに対してクラスターが常に一貫した状態になるようにします。
クラスター ノードとリソースの検出
クラスター内の各ノードは単一のクラスター サービスを実行し、このサービスはフェールオーバー クラスターを操作して、すべてのクラスター リソースを監視します。 リソース ホストは別のプロセスとして動作し、クラスター サービスとクラスター リソース間のインターフェイスとなります。 リソース ホストは、クラスター サービスによって呼び出されたときにクラスター リソースで操作を実行します。 SQL Server などのクラスター対応アプリケーションは、リソース DLL を介してリソース モニターにカスタム インターフェイスを提供します。 リソース DLL は、オンラインとオフラインの操作およびカスタム リソースの正常性の監視を実装します。 リソース ホストはクラスター サービスの子プロセスであり、クラスター サービスが強制終了されるたびに強制終了されます。
SQL Server の場合、AG リソース DLL は、AG リース メカニズムと Always On 正常性検出に基づいて、AG の正常性を判断します。 AG リソース DLL は、IsAlive 操作を介してリソースの正常性を公開します。 リソース モニターは、CrossSubnetDelay と SameSubnetDelay のクラスター全体の値で設定される、クラスターのハートビート間隔で IsAlive をポーリングします。 プライマリ ノードでは、リソース DLL に対する IsAlive 呼び出しで AG が正常でないことが返されるたびに、クラスター サービスがフェールオーバーを開始します。
クラスター サービスはクラスター内の他のノードにハートビートを送信し、そこから受信したハートビートを確認します。 ノードは、一連の未確認ハートビートから通信エラーを検出すると、到達可能なすべてのノードでクラスター ノードの正常性ビューを調整するようにメッセージをブロードキャストします。 このイベント (再グループ化イベントと呼ばれる) により、ノード間のクラスター状態の一貫性が維持されます。 再グループ化イベントの後、クォーラムが失われた場合、このパーティションの AG を含むすべてのクラスター リソースがオフラインになります。 このパーティションのすべてのノードは、解決中の状態に遷移します。 クォーラムを保持するパーティションが存在する場合、AG はそのパーティションの 1 つのノードに割り当てられ、プライマリ レプリカになり、他のすべてのノードがセカンダリ レプリカになります。
Always On 正常性検出
Always On リソース DLL は、内部の SQL Server コンポーネントの状態を監視します。 sp_server_diagnostics は、HealthCheckTimeout によって制御される間隔でこれらの SQL Server コンポーネントの正常性を に報告します。 sp_server_diagnostics は、システム、リソース、クエリ処理、io サブシステム、イベントという、5 つのインスタンス レベル コンポーネントの正常性状態を報告します。 また、AG ごとの正常性も報告します。 それぞれの更新時に、リソース DLL は、AG のエラー レベルに基づいて、AG リソースの正常性状態を更新します。 データが sp_server_diagnostics によって返されると、各コンポーネントの状態がクリーン、警告、エラー、または不明のいずれかとして表示され、コンポーネントの状態を説明するいくつかの XML データが示されます。 正常性検出の場合、コンポーネントがエラー状態の場合にのみ、リソース DLL がアクションを実行します。
正常性検出時に複数の間隔でリソース DLL の更新を報告できない場合、AG は正常性でないと判断され、IsAlive 呼び出し時にエラーが報告されます。
リースのメカニズム
他のフェールオーバーのメカニズムとは異なり、SQL Server インスタンスはリースのメカニズムで積極的な役割を果たします。 リース メカニズムは、クラスター リソースのホストと SQL Server プロセスの間での Looks-Alive 検証として使用されます。 このメカニズムは、両者 (クラスター サービスと SQL Server サービス) が頻繁に接触していることを確認する目的で使用されます。互いの状態を確認し、最終的にはスプリットブレインを防止します。 AG をプライマリ レプリカとしてオンラインにすると、SQL Server インスタンスは、AG の専用リース ワーカー スレッドを生成します。 リース ワーカーは、リース更新イベントとリース停止イベントを含むリソース ホストと、メモリの小さな領域を共有します。 リース ワーカーとリソース ホストは循環式に動作し、それぞれのリース更新イベントを通知してから、スリープ状態になり、他方が自身のリース更新イベントまたは停止イベントを通知するまで待機します。 リソース ホストと SQL Server リース スレッドの両方で有効期間値が保持されます。この値は、スレッドが他のスレッドによる通知後にウェイクアップされるたびに更新されます。 信号の待機中に有効期間に達した場合、リースは期限切れとなり、レプリカはその特定の AG の解決中の状態に遷移します。 リース停止イベントが通知されると、レプリカは解決中のロールに遷移します。
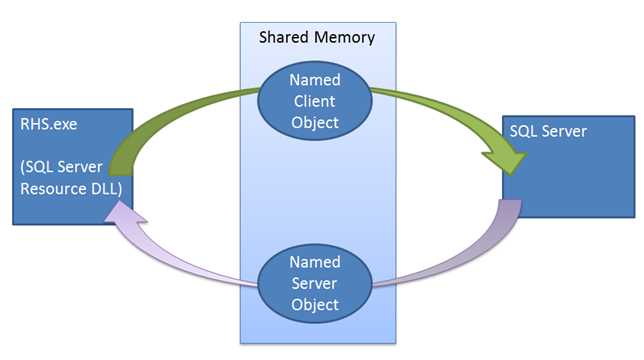
リースのメカニズムでは、SQL Server と Windows Server フェールオーバー クラスター間の同期が適用されます。 フェールオーバー コマンドが実行されたときに、クラスター サービスは現在のプライマリ レプリカのリソース DLL に対して Offline 呼び出しを行います。 リソース DLL は、まず、ストアド プロシージャを使用して AG をオフラインにしようとします。 このストアド プロシージャが失敗した場合、またはタイムアウトになった場合、クラスター サービスにエラーが報告され、終了コマンドが実行されます。 終了の際に再度同じストアド プロシージャの実行が試行されますが、クラスターはこの時点では、新しいレプリカで AG がオンラインになる前にリソース DLL が成功または失敗を報告するまで待機しません。 この 2 番目のプロシージャ呼び出しが失敗した場合、リソース ホストはリース メカニズムに依存して、インスタンスをオフラインにする必要があります。 AG をオフラインにするためにリソース DLL が呼び出されると、リソース DLL はリース停止イベントを通知し、SQL Server のリース ワーカー スレッドをウェイクアップして AG をオフラインにします。 この停止イベントが通知されない場合でも、リースは期限切れとなり、レプリカは解決中の状態に切り替わります。
リースは主にプライマリ インスタンスとクラスター間の同期メカニズムですが、その他の場合はフェールオーバーが不要なエラー状態が発生することもあります。 たとえば、CPU の高い使用率、メモリ不足状態 (少ない仮想メモリ、プロセス ページング)、メモリ ダンプ生成時の SQL プロセスの応答停止、システムの応答停止、クラスター (WSFC) のオフラインへの移行 (たとえば、クォーラム損失のため) により、SQL インスタンスからのリース更新が妨げられ、再起動やフェールオーバーが発生する可能性があります。
クラスターのタイムアウト値に関するガイドライン
トレードオフを慎重に検討し、SQL Server クラスターを積極的に監視しない場合の結果を理解します。 クラスターのタイムアウト値が増えると、一時的なネットワーク問題の許容範囲が広がりますが、ハード エラーの対応が遅くなります。 リソース負荷や広範な地理的な遅延に対処するためにタイムアウトを増やすと、ハード エラー、さらには回復不可能なエラーからの回復時間が増えます。 これは多くのアプリケーションで許容できますが、すべての場合に適しているわけではありません。
既定の設定は、ハード エラーの症状に迅速に対応し、ダウンタイムを制限するために最適化されていますが、これらの設定は特定のワークロードや構成にはアグレッシブすぎる場合もあります。 既定値を超える LeaseTimeout、CrossSubnetDelay、CrossSubnetThreshold、SameSubnetDelay、SameSubnetThreshold、HealthCheckTimeout のいずれかを低くすることはお勧めできません。 展開ごとの正しい設定は異なり、検出のための微調整期間が長くなる可能性があります。 これらの値のいずれかを変更する場合は、値の間の関係と依存関係を考慮して、徐々に行ってください。
クラスター タイムアウトとリース タイムアウトの関係
リース メカニズムの主な機能は、別のノードへのフェールオーバーを実行する間、クラスター サービスがインスタンスと通信できない場合に、SQL Server リソースをオフラインにすることです。 クラスターが AG クラスター リソースでオフライン操作を行う際に、クラスター サービスはリソースをオフラインにするために、rhs.exe に対して RPC 呼び出しを行います。 リソース DLL ではストアド プロシージャを使用して、AG をオフラインにするよう SQL Server に指示しますが、このストアド プロシージャが失敗またはタイムアウトになることがあります。リソース ホストのリース更新スレッドもオフライン呼び出し中に停止します。 最悪の場合、SQL Server により、リースが ½ * LeaseTimeout で期限切れとなり、インスタンスが解決中の状態に切り替わります。 フェールオーバーは複数の異なるパーティによって開始できますが、クラスター状態のビューがクラスターと SQL Server インスタンス間で一貫していることが非常に重要となります。 たとえば、プライマリ インスタンスとクラスターの残りの部分との接続が切断されたとします。 クラスター内の各ノードは、クラスター タイムアウト値のため、同じような時刻にエラーを判断しますが、プライマリ SQL Server インスタンスと対話して、プライマリ ロールを放棄するよう強制できるのはプライマリ ノードのみです。
プライマリ ノードの観点から、クラスター サービスはクォーラムを失い、サービス自体を終了し始めます。 クラスター サービスはリソース ホストに対して RPC 呼び出しを行い、プロセスを終了します。 SQL Server インスタンスで AG をオフラインにする作業は、この終了呼び出しで行う必要があります。 このオフライン呼び出しは T-SQL を使用して行われますが、SQL とリソース DLL の間の接続が正常に確立されることを保証できません。
クラスターの残りの部分の観点から、現在、プライマリ レプリカは存在しないため、クラスター内の残りのノードのために単一の新しいプライマリが選出され、確立されます。 リソース DLL によって呼び出されたストアド プロシージャが失敗したか、タイムアウトになった場合、クラスターはスプリット ブレイン シナリオの影響を受けやすくなることがあります。
通信エラーが発生した場合、リース タイムアウトにより、スプリット ブレイン シナリオを防ぐことができます。 すべての通信が失敗した場合でも、リソース DLL のプロセスは終了し、リースを更新できなくなります。 リースが期限切れになると、AG は自動的にオフラインになります。 SQL Server のインスタンスは、クラスターが新しいものを確立する前にプライマリ レプリカをホストしなくなることに注意する必要があります。 新しいプライマリ レプリカを選択する必要がある、クラスターの残りの部分には現在のプライマリ レプリカと調整する手段がないため、タイムアウト値を指定することで、現在のプライマリが自動でオフラインになる前に、新しいプライマリ レプリカが確立されないようになります。
クラスターがフェールオーバーするときに、以前のプライマリ レプリカをホストする SQL Server のインスタンスは、新しいプライマリ レプリカがオンラインになる前に解決中の状態に遷移する必要があります。 任意の時点の SQL Server リース スレッドには、½ * LeaseTimeout の有効期間が残っています。これは、リースが更新されるたびに、新しい有効期間が LeaseInterval または ½ * LeaseTimeout に更新されるためです。 クラスター サービスまたはリソース ホストが、リース停止イベントを通知することなく停止または終了した場合、クラスターは SameSubnetThreshold\ SameSubnetDelay ミリ秒後にプライマリ ノードの停止を宣言します。 プライマリがオフラインであることが保証されるように、リースはこの時間内に期限切れになる必要があります。 リース タイムアウトの最大有効期間は ½ * LeaseTimeout であるため、½ * LeaseTimeout は SameSubnetThreshold * SameSubnetDelay より小さい必要があります。
SameSubnetThreshold \<= CrossSubnetThreshold および SameSubnetDelay \<= CrossSubnetDelay は、すべての SQL Server クラスターに適用する必要があります。
正常性チェック タイムアウトの操作
正常性チェック タイムアウトは、他のフェールオーバー メカニズムが直接依存しないため、より柔軟です。 30 秒の既定値では、sp_server_diagnostics の間隔が 10 秒、タイムアウトの最小値が 15 秒、間隔が 5 秒に設定されます。 一般的に、sp_server_diagnostics の更新間隔は常に 1/3 * HealthCheckTimeout です。 リソース DLL は、ある間隔で正常性データの新しいセットを受信しない場合、前の間隔の正常性データを引き続き使用して、現在の AG とインスタンスの正常性を判断します。 正常性チェック タイムアウトの値を増やすと、プライマリの CPU 負荷の許容範囲が広がり、sp_server_diagnostics が各間隔で新しいデータを提供しないようにできますが、長時間、古いデータの正常性チェックに依存することになります。 タイムアウト値に関係なく、レプリカが正常でないことを示すデータが受信されると、次の IsAlive 呼び出しでインスタンスが正常でないことが返され、クラスター サービスがフェールオーバーを開始します。
AG のエラー状態レベルによって、正常性チェックのエラー状態が変わります。 あらゆるエラー レベルで、AG 要素が sp_server_diagnostics によって正常でないと報告された場合、正常性チェックは失敗します。 各レベルは、その下のレベルからエラー状態をすべて継承します。
| Level | インスタンスが停止と見なされる状態 |
|---|---|
| 1:OnServerDown | AG 以外のすべてのリソースが失敗した場合、正常性チェックでアクションは行われません。 AG データが 5 間隔内、または 5/3 * HealthCheckTimeout 内で受信されない場合 |
| 2:OnServerUnresponsive | HealthCheckTimeout の sp_server_diagnostics からデータが受信されない場合 |
| 3:OnCriticalServerError | (既定値) システム コンポーネントがエラーを報告する場合 |
| 4:OnModerateServerError | リソース コンポーネントがエラーを報告する場合 |
| 5: OnAnyQualifiedFailureConitions | クエリ処理コンポーネントがエラーを報告する場合 |
クラスターと Always On のタイムアウト値の更新
クラスター値
WSFC 構成には、クラスター タイムアウト値を判断する必要がある 4 つの値があります。
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
遅延値では、クラスター サービスからのハートビート間の待機時間を判断します。スレッド値では、ターゲット ノードまたはリソースから受信確認を受け取ることができない、ハートビートの数が設定されます。この値を超えるとオブジェクトがクラスターによって停止と宣言されます。 SameSubnetDelay \* SameSubnetThreshold ミリ秒より長い時間、同じサブネット内のノード間の正常なハートビートが存在しない場合、ノードは停止と判断されます。 クロス サブネット値を使用するクロス サブネット通信でも同様です。
現在のクラスター値をすべて一覧表示するには、ターゲット クラスターの任意のノードで、管理者特権の PowerShell 端末を開きます。 次のコマンドを実行します。
Get-Cluster | fl *
これらの値のいずれかを更新するには、管理者特権の PowerShell 端末で以下のコマンドを実行します。
(Get-Cluster).<ValueName> = <NewValue>
遅延値 * しきい値の積を増やして、クラスター タイムアウトの許容範囲を広げる場合、しきい値を増やす前にまず遅延値を増やす方が効率的です。 遅延値を増やすことで、各ハートビート間の時間が増えます。 ハートビート間の時間が増えれば、一時的なネットワークの問題が自然に解決し、同じ期間により多くのハートビートを送信する場合と比べ、ネットワーク輻輳を減らすための時間が増えます。
リースのタイムアウト
リースのメカニズムは、WSFC クラスター内の各 AG に固有の単一の値によって制御されます。 リース タイムアウトになると、次のエラーが発生する場合があります。
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
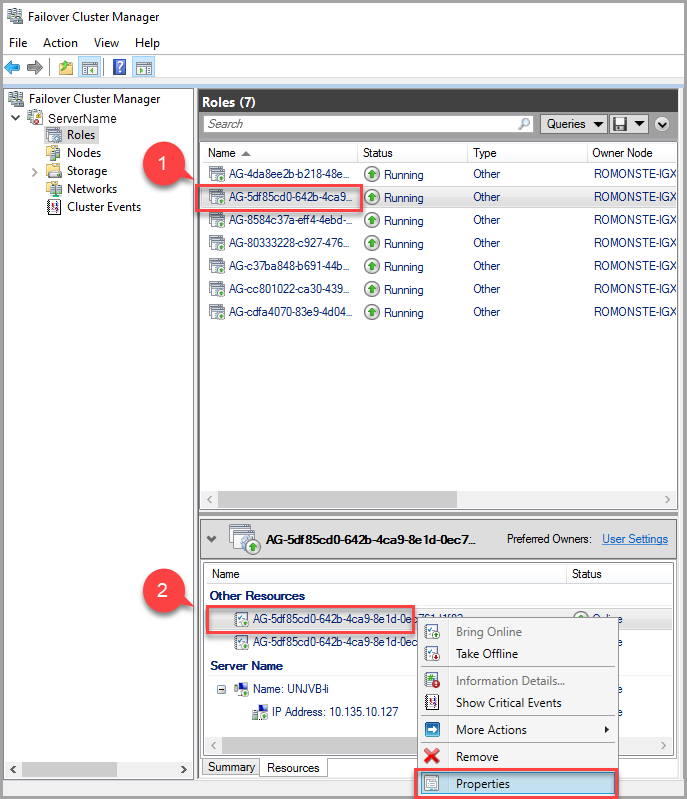
リースのタイムアウト値を変更するには、フェールオーバー クラスター マネージャーを使用し、次の手順に従います。
ロール タブで、ターゲットの AG ロールを見つけます。 ターゲットの AG ロールを選びます。
ウィンドウの下部にある AG リソースを右クリックして、 [プロパティ] を選択します。
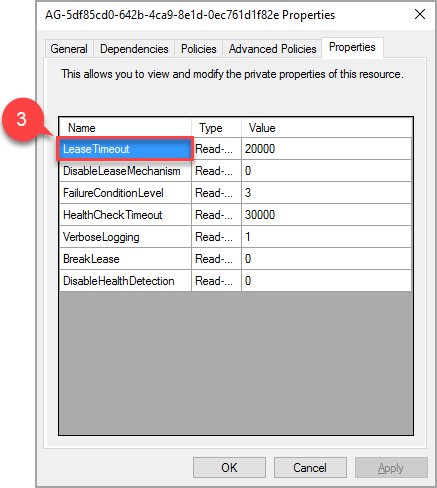
ポップアップ ウィンドウで、プロパティ タブに移動しすると、この AG に固有の値の一覧が表示されます。 LeaseTimeout 値を選択して、これを変更します。
AG の構成に応じて、リスナー、共有ディスク、ファイル共有などのリソースが追加される可能性があります。これらのリソースに追加の構成は必要ありません。
Note
プロパティ 'LeaseTimeout' の新しい値は、リソースがオフラインになり、再びオンラインになった後に有効になります。
正常性チェックの値
Always On の正常性チェックは、FailureConditionLevel および HealthCheckTimeout という 2 つの値で制御されます。 FailureConditionLevel は、sp_server_diagnostics で報告される特定のエラー状態に対する許容レベルを示し、HealthCheckTimeout は、リソース DLL が sp_server_diagnostics から更新プログラムを受信しなくてもよい時間を構成します。 sp_server_diagnostics の更新間隔は常に HealthCheckTimeout / 3 となります。
フェールオーバー状態レベルを構成するには、CREATE または ALTER AVAILABILITY GROUP ステートメントの FAILURE_CONDITION_LEVEL = <n> オプションを使用します。ここで、<n> は 1 から 5 までの整数となります。 次のコマンドでは、AG 'AG1' のエラー状態レベルを 1 に設定します。
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
正常性チェック タイムアウトを構成するには、CREATE または ALTERAVAILABILITY GROUP ステートメントの HEALTH_CHECK_TIMEOUT オプションを使用します。 次のコマンドでは、AG AG1 の正常性チェック タイムアウトを 60,000 ミリ秒に設定します。
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
タイムアウト ガイドラインの概要
既定値を下回るタイムアウト値を低くすることはお勧めできません。
リース間隔 (½ * LeaseTimeout) は、SameSubnetThreshold * SameSubnetDelay より短い必要があります。
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| タイムアウトの設定 | 目的 | 。 | 使用 | IsAlive と LooksAlive | 原因 | 結果 |
|---|---|---|---|---|---|---|
| リースのタイムアウト 既定値: 20000 |
スプリット ブレインを防止する | プライマリからクラスター (HADR) |
Windows イベント オブジェクト | 両方で使用される | OS の応答停止、仮想メモリの不足、ワーキング セット ページング、ダンプの生成、固定された CPU、WSFC ダウン (クォーラムの損失) | AG リソースのオフライン - オンライン、フェールオーバー |
| セッションのタイムアウト 既定値: 10000 |
プライマリとセカンダリの間の通信の問題を通知する | セカンダリからプライマリ (HADR) |
TCP ソケット (DBM エンドポイント経由で送信されるメッセージ) | 両方で使用されない | ネットワーク通信、 セカンダリでの問題 - ダウン、OS の応答停止、リソースの競合 |
セカンダリ - 切断 |
| 正常性チェック タイムアウト 既定値: 30000 |
プライマリ レプリカの正常性を判断しようとしている間のタイムアウトを示す | クラスターからプライマリ (FCI、HADR) |
T-SQL sp_server_diagnostics | 両方で使用される | エラー条件が満たされる、OS の応答停止、仮想メモリの不足、ワーキング セットのトリミング、ダンプの生成、WSFC (クォーラムの損失)、スケジューラの問題 (デッド ロックしたスケジューラ) | AG リソース オフライン - オンラインまたはフェールオーバー、FCI 再起動またはフェールオーバー |