適用対象:![]() SQL Server
SQL Server
分散型可用性グループを作成するには、それぞれに独自のリスナーを持つ可用性グループをそれぞれ 2 つ作成する必要があります。 次に、これらの可用性グループを分散型可用性グループに結合します。 次の手順は、Transact-SQL の基本的な例です。 この例では、可用性グループとリスナーを作成するすべての手順を取り上げていません。主な要件を強調することに重点を置いています。
分散型可用性グループの技術の概要については、「Distributed availability groups」 (分散可用性グループ) を参照してください。
前提条件
分散型可用性グループを構成するには、次の前提条件を満たしている必要があります。
- サポートされているバージョンの SQL Server。
注
分散ネットワーク名 (DNN) を使用して Azure VM 上の SQL Server 上の可用性グループのリスナーを構成した場合、可用性グループの上に分散可用性グループを構成することはできません。 詳しくは、Azure VM 上の SQL Server での AG と DNN リスナーとの機能の相互運用性に関する記事をご覧ください。
権限
分散型可用性グループをフェールオーバーするには、 が必要です。可用性グループを作成するには、サーバーに対する sysadmin アクセス許可が必要です。
すべての IP アドレスをリッスンするようにデータベース ミラーリング エンドポイントを設定する
データベース ミラーリング エンドポイントが、分散可用性グループ内の異なる可用性グループ間で通信できることを確認します。 1 つの可用性グループがデータベース ミラーリング エンドポイント上の特定のネットワークに設定されている場合、分散型可用性グループは正しく機能しません。 分散型可用性グループ内のレプリカをホストする各サーバーで、すべての IP アドレス (LISTENER_IP = ALL) をリッスンするようにデータベース ミラーリング エンドポイントを設定します。
すべての IP アドレスをリッスンするデータベース ミラーリング エンドポイントを作成する
たとえば、次のスクリプトでは、すべての IP アドレスをリッスンする新しいデータベース ミラーリング エンドポイントが TCP ポート 5022 に作成されます。
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
既存のデータベース ミラーリング エンドポイントを変更して、すべての IP アドレスをリッスンする
たとえば、次のスクリプトは、既存のデータベース ミラーリング エンドポイントを変更して、すべての IP アドレスをリッスンします。
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
最初の可用性グループを作成する
最初のクラスターにプライマリ可用性グループを作成する
最初の Windows Server フェールオーバー クラスター (WSFC) に可用性グループを作成します。 この例では、データベース ag1 の db1という可用性グループです。 プライマリ可用性グループのプライマリ レプリカは、分散型可用性グループではグローバル プライマリと呼ばれます。 この例の server1 はグローバル プライマリです。
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注
上記の例では、自動シード処理を使用しています。レプリカと分散型可用性グループの両方について、SEEDING_MODE は AUTOMATIC に設定されます。 この構成では、確立後に、セカンダリ レプリカとセカンダリ可用性グループは自動的に設定されます。プライマリ データベースの手動バックアップと復元を実行する必要はありません。
セカンダリ レプリカをプライマリ可用性グループに追加する
ALTER AVAILABILITY GROUP に JOIN オプションを指定して、すべてのセカンダリ レプリカを可用性グループに追加する必要があります。 この例では自動シード処理を使用しているため、ALTER AVAILABILITY GROUP に GRANT CREATE ANY DATABASE オプションを指定して呼び出す必要もあります。 この設定では、可用性グループでデータベースを作成し、プライマリ レプリカから自動的にシード処理を開始できるようになります。
この例では、セカンダリ レプリカ server2で次のコマンドが実行され、 ag1 可用性グループに追加されます。 この可用性グループは、セカンダリ上にデータベースを作成できるようになります。
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
注
可用性グループがセカンダリ レプリカにデータベースを作成すると、ALTER AVAILABILITY GROUP ステートメントを実行したアカウントとしてデータベース所有者が設定され、任意のデータベースを作成するアクセス許可が付与されます。 詳細については、「セカンダリ レプリカの CREATE DATABASE アクセス許可を可用性グループに付与する」を参照してください。
プライマリ可用性グループのリスナーを作成する
次に、プライマリ可用性グループのリスナーを最初の WSFC に追加します。 この例では、 ag1-listenerというリスナーです。 リスナーの詳細な作成手順については、「可用性グループ リスナーの作成または構成 (SQL Server)」を参照してください。
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
2 つ目の可用性グループを作成する
2 つ目の WSFC に 2 つ目の可用性グループ ag2を作成します。 この場合、データベースはプライマリ可用性グループから自動的にシード処理されるため、指定されません。 セカンダリ可用性グループのプライマリ レプリカは、分散型可用性グループではフォワーダーと呼ばれます。 この例の server3 はフォワーダーです。
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注
- セカンダリ可用性グループは、同じデータベース ミラーリング エンドポイント (この例ではポート 5022) を使用する必要があります。 そうしないと、ローカルのフェールオーバー後にレプリケーションは停止します。
- 基になる可用性グループは同じ可用性モードである必要があります。両方の可用性グループを同期コミット モードにするか、両方を非同期コミット モードにする必要があります。 どちらを使用するかがわからない場合は、フェールオーバーの準備ができるまで両方を非同期コミット モードに設定します。
セカンダリ レプリカをセカンダリ可用性グループに追加する
この例では、セカンダリ レプリカ server4で次のコマンドが実行され、 ag2 可用性グループに追加されます。 この可用性グループは、自動シード処理をサポートするデータベースをセカンダリ上に作成できるようになります。
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
セカンダリ可用性グループのリスナーを作成する
次に、セカンダリ可用性グループのリスナーを 2 つ目の WSFC に追加します。 この例では、 ag2-listenerというリスナーです。 リスナーの詳細な作成手順については、「可用性グループ リスナーの作成または構成 (SQL Server)」を参照してください。
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
最初のクラスターに分散型可用性グループを作成する
最初の WSFC に分散型可用性グループ (この例では distributedAG ) を作成します。
CREATE AVAILABILITY GROUP コマンドに DISTRIBUTED オプションを指定して実行します。
AVAILABILITY GROUP ON パラメーターに、メンバー可用性グループの ag1 と ag2 を指定します。
自動シード処理を使用して分散型可用性グループを作成するには、次の Transact-SQL コードを使用します。
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
注
LISTENER_URL で、各可用性グループのリスナーと、可用性グループのデータベース ミラーリング エンドポイントを指定します。 この例では、ポート 5022 です (リスナーの作成に使用したポート 60173 ではありません)。 たとえば Azure でロード バランサーを使用している場合は、分散可用性グループ ポートの負荷分散規則を追加
フォワーダーへの自動シード処理を取り消す
何らかの理由で、2 つの可用性グループを同期する前にフォワーダーの初期化を取り消すことが必要になる場合、フォワーダーの SEEDING_MODE パラメーターを MANUAL に設定することで分散型可用性グループを変更し、すぐにシード処理を取り消します。 グローバル プライマリでコマンドを実行します。
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
2 つ目のクラスターの分散型可用性グループに参加する
次に、2 つ目の WSFC の分散型可用性グループに参加します。
自動シード処理を使用して分散型可用性グループに参加するには、次の Transact-SQL コードを使用します。
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
2 つ目の可用性グループのセカンダリ上のデータベースを結合する
2 つ目の可用性グループが自動シーディングを使うように設定されている場合は、手順 2 に進みます。
2 つ目の可用性グループが手動シーディングを使っている場合は、グローバル プライマリで作成したバックアップを 2 つ目の可用性グループのセカンダリに復元します。
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;2 つ目の可用性グループのセカンダリ レプリカ上のデータベースが復元状態になったら、それを可用性グループに手動で結合する必要があります。
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
分散型可用性グループのフェールオーバー操作
SQL Server 2022 (16.x) では REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定に対する分散型可用性グループのサポートが導入されているため、SQL Server 2022 以降のバージョンでは、分散型可用性をフェールオーバーする手順は SQL Server 2019 以前のバージョンとは異なります。
分散型可用性グループの場合、サポートされているフェールオーバーの種類はユーザーが手動で開始する FORCE_FAILOVER_ALLOW_DATA_LOSS のみです。 したがって、データの損失を防ぐには、フェールオーバーを開始する前に、2 つのレプリカ間でデータが確実に同期されるように、追加の手順 (このセクションで詳しく説明されている) を実行する必要があります。
データ損失が許容される緊急事態が発生した場合、次の内容を実行してデータ同期を確保せずにフェールオーバーを開始できます。
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
同じコマンドを使用してフォワーダーにフェールオーバーするだけではなく、グローバル プライマリにフェールバックすることもできます。
SQL Server 2022 (16.x) 以降では、分散型可用性グループの REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定を構成できます。分散型可用性グループのフェールオーバー時にデータ損失が保証されるように設計されています。 この設定が構成されている場合、このセクションの手順に従って分散型可用性グループをフェールオーバーします。
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定を使用しない場合、手順に従って SQL Server 2019 以前の分散型可用性グループをフェールオーバーします。
注
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT を 1 に設定すると、プライマリ レプリカは、プライマリ レプリカでコミットされる前にセカンダリ レプリカでトランザクションがコミットされるのを待機するため、パフォーマンスが低下する可能性があります。 分散可用性グループが SQL Server 2022 (16.x) で同期するためには、グローバル プライマリのトランザクションを制限または停止する必要はありませんが、これを行うと、REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT が 1 に設定されたユーザー トランザクションと分散型可用性グループの同期の両方のパフォーマンスが向上する可能性があります。
データ損失がないことを確認する手順
データ損失が発生しないようにするには、まず、次の手順に従って、データ損失をサポートしないように分散型可用性グループを構成する必要があります。
- フェールオーバーを準備するには、グローバル プライマリ と フォワーダーが
SYNCHRONOUS_COMMITモードであることを確認します。 そうでない場合は、SYNCHRONOUS_COMMITを使用して、それらを に設定します。 - グローバル プライマリとフォワーダーの "両方" で、分散型可用性グループを同期コミットに設定します。
- 分散型可用性グループが同期されるまで待ちます。
- グローバル プライマリで、
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITを使用して、分散型可用性グループの 設定を 1 に設定します。 - ローカル AG と分散型可用性グループ内のすべてのレプリカが正常であり、分散型可用性グループが SYNCHRONIZEDされていることを確認します。
- グローバル プライマリ レプリカで分散型可用性グループのロールを
SECONDARYに設定すると、分散型可用性グループが利用できなくなります。 - フォワーダー (目的の新しいプライマリ) で、ALTER AVAILABILITY GROUP と
FORCE_FAILOVER_ALLOW_DATA_LOSSを使用して、分散型可用性グループをフェールオーバーします。 - 新しいセカンダリ (以前のグローバル プライマリ レプリカ) で、分散型可用性グループの
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITを 0 に設定します。 - 省略可能: 可用性グループが待機時間の原因となる地理的な距離を越える場合は、可用性モードを
ASYNCHRONOUS_COMMITに変更します。 これにより、必要に応じて最初の手順からの変更が元に戻されます。
T-SQL の例
このセクションでは、Transact-SQL を使用して distributedAG という名前の分散型可用性グループをフェールオーバーする詳細な例の手順について説明します。 この例の環境では、分散可用性グループに対して合計 4 つのノードがあります。 グローバル プライマリ N1 および N2 ホスト可用性グループ ag1 、フォワーダー N3 および N4 ホスト可用性グループ ag2。 分散型可用性グループ distributedAG は、変更を ag1 から ag2にプッシュします。
分散可用性グループを形成するローカル可用性グループのプライマリで
SYNCHRONOUS_COMMITを確認するクエリ。 フォワーダー と グローバル プライマリで次の T-SQL を直接実行します。SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);グローバル プライマリとフォワーダーの両方
で次のコードを実行して、分散型可用性グループを同期コミットに設定します。 -- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);注
分散型可用性グループでは、2 つの可用性グループが同期された状態であるかどうかは、両方のレプリカの可用性モードに依存します。 同期コミット モードでは、現在のプライマリ可用性グループと現在のセカンダリ可用性グループの両方が
SYNCHRONOUS_COMMIT可用性モードを持つ必要があります。 このため、グローバル プライマリ レプリカとフォワーダーの両方でこのスクリプトを実行する必要があります。分散型可用性グループの状態が
SYNCHRONIZEDに変わるまで待ちます。 グローバル プライマリで次のクエリを実行します。-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];可用性グループ synchronization_state_desc が
SYNCHRONIZEDになったら先に進みます。SQL Server 2022 (16.x) 以降のグローバル プライマリでは、次の T-SQL を使用して
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITを 1 に設定します。ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);グローバルプライマリ とフォワーダー にクエリを実行することで、すべてのレプリカで可用性グループが正常であることを確認します。
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');グローバル プライマリで、分散型可用性グループのロールを
SECONDARYに設定します。 この時点で、分散型可用性グループは使用できません。 この手順が完了したら、残りの手順が実行されるまでフェールバックすることはできません。ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);フォワーダーで次のクエリを実行してグローバル プライマリからフェールオーバーし、可用性グループを移行し、分散型可用性グループをオンラインに戻します。
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;この手順の後:
- グローバルプライマリは、
N1からN3に遷移します。 - フォワーダーは、
N3からN1に移行します。 - 分散型可用性グループを使用できます。
- グローバルプライマリは、
新しいフォワーダー (以前のグローバル プライマリ、
N1) で、REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT分散型可用性グループのプロパティを 0 に設定してクリアします。ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);"省略可能": 可用性グループ間の地理的な距離が原因で待機時間が発生する場合は、グローバル プライマリとフォワーダーの "両方" で、可用性モードを に戻すことを検討します。
ASYNCHRONOUS_COMMITこれにより、必要に応じて、最初の手順で行われた変更が元に戻されます。-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
分散型可用性グループを削除する
次の Transact-SQL ステートメントは、 distributedAGという分散型可用性グループを削除します。
DROP AVAILABILITY GROUP distributedAG;
フェールオーバー クラスター インスタンスに分散可用性グループを作成する
フェールオーバー クラスター インスタンス (FCI) で可用性グループを使用して、分散可用性グループを作成することができます。 この場合、可用性グループ リスナーは必要ありません。 FCI インスタンスのプライマリ レプリカに対して仮想ネットワーク名 (VNN) を使用します。 次の例は、SQLFCIDAG と呼ばれる分散型可用性グループを示しています。 1 つの可用性グループは SQLFCIAG です。 SQLFCIAG には、2 つの FCI レプリカがあります。 プライマリ FCI レプリカの VNN は SQLFCIAG-1 であり、セカンダリ FCI レプリカの VNN は SQLFCIAG 2 です。 分散型可用性グループには、ディザスター リカバリーのための SQLAG DR も含まれています。
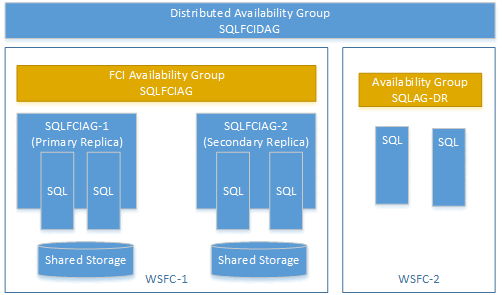
次の DDL では、この分散型可用性グループが作成されます。
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
リスナーの URL は、プライマリ FCI インスタンスの VNN です。
分散型可用性グループで FCI を手動でフェールオーバーする
FCI 可用性グループを手動でフェールオーバーするには、分散型可用性グループを更新してリスナー URL の変更を反映します。 たとえば、分散型 AG のグローバル プライマリと、SQLFCIDAG の分散型 AG のフォワーダーの両方で、次の DDL を実行します。
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)