SQL Server の RHEL フェールオーバー クラスター インスタンス (FCI) クラスターを構成する
適用対象: ![]() SQL Server - Linux
SQL Server - Linux
このガイドでは、Red Hat Enterprise Linux 上の SQL Server 用に 2 ノードの共有ディスク フェールオーバー クラスターを作成する手順について説明します。 クラスタリング レイヤーは、Pacemaker の上に構築された Red Hat Enterprise Linux (RHEL) HA アドオンに基づいています。 SQL Server インスタンスは、一方のノードでのみアクティブになります。
Note
Red Hat HA アドオンとドキュメントにアクセスするには、サブスクリプションが必要です。
次の図に示すように、2 台のサーバーに対してストレージが提示されます。 クラスタリング コンポーネント (Corosync と Pacemaker) によって、通信とリソース管理が調整されます。 1 台のサーバーで、ストレージ リソースと SQL Server へのアクティブ接続が行われます。 Pacemaker で障害が検出されると、クラスタリング コンポーネントによって他のノードにリソースが移動します。
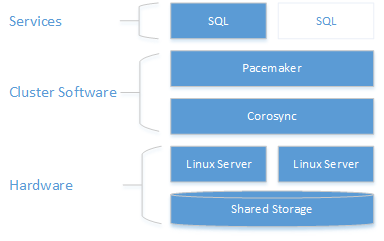
クラスター構成、リソース エージェント オプション、および管理の詳細については、RHEL リファレンス ドキュメントを参照してください。
Note
現時点では、Pacemaker との SQL Server の統合は、Windows 上の WSFC との統合ほどには連携していません。 SQL Server 内からは、クラスターの存在を認識することがなく、すべてのオーケストレーションはアウトサイドインで実行され、サービスは Pacemaker によりスタンドアロン インスタンスとして制御されます。 また、たとえば、dmvs sys.dm_os_cluster_nodes をクラスター化すると、sys.dm_os_cluster_properties はレコードを記録しません。
IP ではなく、文字列サーバー名をポイントする接続文字列を使用するには、仮想 IP リソースを作成するために使用する IP (以下のセクションで説明します) を、選択したサーバー名と共に DNS サーバーに登録する必要があります。
次のセクションでは、フェールオーバー クラスター ソリューションを設定する手順について説明します。
前提条件
次のエンドツーエンドのシナリオを完了するには、2 つのノード クラスターともう 1 つのサーバーをデプロイして NFS サーバーを構成するために、2 台のマシンが必要です。 次の手順では、これらのサーバーを構成する方法を示します。
各クラスター ノードでオペレーティング システムをセットアップして構成する
最初の手順は、クラスター ノード上のオペレーティング システムを構成することです。 このチュートリアルでは、HA アドオンの有効なサブスクリプションで RHEL を使用します。
各クラスター ノードに SQL Server をインストールして構成する
両方のノードに SQL Server をインストールしてセットアップします。 詳細については、SQL Server on Linux のインストールに関するページを参照してください。
構成目的の場合は、1 つのノードをプライマリ、もう 1 つをセカンダリとして指定します。 このガイドでは、以降でこれらの用語を使用します。
セカンダリ ノードで SQL Server を停止して無効にします。
次の例では、SQL Server を停止して無効にしています。
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Note
セットアップ時に、SQL Server インスタンスのサーバー マスター キーが生成され、/var/opt/mssql/secrets/machine-key に配置されます。 Linux では、SQL Server は常に mssql というローカル アカウントとして実行されます。 ローカル アカウントであるため、その ID はノード間で共有されません。 したがって、プライマリ ノードから各セカンダリ ノードに暗号化キーをコピーして、サーバー マスター キーの暗号化を解除するために各ローカル mssql アカウントがそれにアクセスできるようにする必要があります。
プライマリ ノードで、Pacemaker の SQL Server ログインを作成し、
sp_server_diagnosticsを実行するログイン権限を付与します。 Pacemaker は、このアカウントを使用して、SQL Server が実行されているノードを確認します。sudo systemctl start mssql-serversa アカウントを使用して SQL Server
masterデータベースに接続し、次のように実行します。USE [master] GO CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>]または、より細かなレベルでアクセス許可を設定することもできます。 Pacemaker ログインでは、
sp_server_diagnosticsで正常性状態のクエリを実行するためのVIEW SERVER STATEと、setupadminと、ALTER ANY LINKED SERVERおよびsp_dropserverを実行することで FCI インスタンス名をリソース名で更新するためのsp_addserverが必要です。プライマリ ノードで SQL Server を停止して無効にします。
クラスター ノードごとにホスト ファイルを構成します。 ホスト ファイルには、すべてのクラスター ノードの IP アドレスと名前が含まれている必要があります。
各ノードの IP アドレスを確認します。 次のスクリプトを実行すると、現在のノードの IP アドレスが表示されます。
sudo ip addr show各ノードのコンピューター名を設定します。 各ノードに 15 文字以下の一意の名前を指定します。 コンピューター名は
/etc/hostsに追加することで設定します。 次のスクリプトを使うと、viで/etc/hostsを編集できます。sudo vi /etc/hosts次の例では、
sqlfcivm1およびsqlfcivm2という名前の 2 つのノードが追加された/etc/hostsを示します。127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
次のセクションでは、共有ストレージを構成し、データベース ファイルをそのストレージに移動します。
共有ストレージを構成し、データベース ファイルを移動する
共有ストレージを提供するためのさまざまなソリューションがあります。 このチュートリアルでは、NFS を使用した共有ストレージの構成について説明します。 ベスト プラクティスに従い、Kerberos を使用して NFS をセキュリティで保護することをお勧めします (例は https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/ にあります)。
警告
NFS をセキュリティで保護しない場合、ネットワークにアクセスして SQL ノードの IP アドレスになりすますことができるユーザーが、データ ファイルにアクセスできてしまいます。 常に、運用環境で使用する前にシステムの脅威をモデル化するようにしてください。 もう 1 つのストレージ オプションは、SMB ファイル共有を使用することです。
NFS を使用して共有ストレージを構成する
重要
4より前のバージョンの NFS サーバーでデータベース ファイルをホストすることは、このリリースではサポートされていません。 これには、クラスター化されていないインスタンス上のデータベースだけでなく、共有ディスクのフェールオーバー クラスタリングに NFS を使用することも含まれます。 Microsoft では、今後のリリースでその他の NFS サーバー バージョンを有効化することに取り組んでいます。
NFS サーバーで、次の手順を実行します。
nfs-utilsのインストールsudo yum -y install nfs-utilsrpcbindを有効にして起動しますsudo systemctl enable rpcbind && sudo systemctl start rpcbindnfs-serverを有効にして起動しますsudo systemctl enable nfs-server && sudo systemctl start nfs-server/etc/exportsを編集して、共有するディレクトリをエクスポートします。 必要な共有ごとに 1 行が必要です。 次に例を示します。/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)共有をエクスポートします
sudo exportfs -ravパスが共有またはエクスポートされていること、NFS サーバーから実行されていることを確認します
sudo showmount -eSELinux で例外を追加します
sudo setsebool -P nfs_export_all_rw 1サーバーのファイアウォールを開きます。
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
NFS 共有ストレージに接続するようにすべてのクラスター ノードを構成する
すべてのクラスター ノードで次の手順を実行します。
nfs-utilsのインストールsudo yum -y install nfs-utilsクライアントと NFS サーバーのファイアウォールを開きます
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadクライアント マシンで NFS 共有が表示されていることを確認します
sudo showmount -e <IP OF NFS SERVER>すべてのクラスター ノードでこれらの手順を繰り返します。
NFS の使用の詳細については、次のリソースを参照してください。
- NFS サーバーと firewalld | Stack Exchange
- NFS ボリュームのマウント | Linux ネットワーク管理者ガイド
- NFS サーバーの構成 | Red Hat カスタマー ポータル
共有ストレージを指すようにデータベース ファイルのディレクトリをマウントする
プライマリ ノードの場合のみ、データベース ファイルを一時的な場所に保存します。次のスクリプトでは、新しい一時ディレクトリを作成し、データベース ファイルを新しいディレクトリにコピーして、古いデータベース ファイルを削除します。 SQL Server はローカル ユーザー
mssqlとして実行されるため、マウントされた共有へのデータ転送後に、ローカル ユーザーが共有に読み取り/書き込みアクセスできるようにする必要があります。sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitすべてのクラスター ノードで、
/etc/fstabファイルを編集して mount コマンドを入れます。<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intr次のスクリプトは、この編集の例を示しています。
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Note
ここで推奨されているようにファイル システム (FS) のリソースを使用する場合は、マウント コマンドを /etc/fstab に保持する必要はありません。 Pacemaker は、FS クラスター化されたリソースを開始するときに、フォルダーのマウントを処理します。 フェンスを使用すると、FS が 2 回マウントされることがなくなります。
システムの
mount -aコマンドを実行して、マウントされたパスを更新します。/var/opt/mssql/tmpに保存したデータベースとログ ファイルを新しくマウントされた共有/var/opt/mssql/dataにコピーします。 この手順は、プライマリ ノード上でのみ実行する必要があります。mssqlローカル ユーザーに必ず読み取り/書き込み権限を付与してください。sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitSQL Server が新しいファイル パスで正常に起動されることを確認します。 これを各ノードで行います。 この時点では、一度に 1 つのノードだけで SQL Server を実行する必要があります。 両方が同時にデータ ファイルにアクセスしようとするため、両方とも同時に実行することはできません (両方のノードで誤って SQL Server が開始されるのを防ぐために、ファイル システムのクラスター リソースを使用して、共有が異なるノードによって 2 回マウントされないようにしてください)。 次のコマンドでは、SQL Server が起動され、状態が確認されてから、SQL Server が停止されます。
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
この時点で、SQL Server の両方のインスタンスが、共有ストレージ上のデータベース ファイルを使用して実行されるように構成されています。 次のステップでは、Pacemaker 用に SQL Server を構成します。
各クラスター ノードに Pacemaker をインストールして構成する
両方のクラスター ノードで、Pacemaker にログインするための SQL Server のユーザー名とパスワードを格納するファイルを作成します。 次のコマンドは、このファイルを作成および設定します。
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<loginPassword>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwd両方のクラスター ノードで、Pacemaker ファイアウォールのポートを開きます。
firewalldを使用してこれらのポートを開くには、次のコマンドを実行します。sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadビルトインの高可用性構成が備わっていない別のファイアウォールを使用する場合は、Pacemaker がクラスター内の他のノードと通信できるように、次のポートを開く必要があります。
- TCP: ポート 2224、3121、21064
- UDP: ポート 5405
各ノードに Pacemaker パッケージをインストールします。
sudo yum install pacemaker pcs fence-agents-all resource-agentsPacemaker と Corosync のパッケージをインストールしたときに作成された既定のユーザー用のパスワードを設定します。 両方のノードで同じパスワードを使用します。
sudo passwd haclusterpcsdサービスと Pacemaker を有効にし、起動します。 これにより、再起動後にノードはクラスターに再度参加できます。 両方のノードで、次のコマンドを実行します。sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerSQL Server の FCI リソース エージェントをインストールします。 両方のノードで、次のコマンドを実行します。
sudo yum install mssql-server-ha
フェンス エージェントを構成する
STONITH デバイスでは、フェンス エージェントが提供されます。 「Azure の Red Hat Enterprise Linux に Pacemaker をセットアップする」では、Azure でこのクラスター用の STONITH デバイスを作成する方法の例が示されています。 環境の手順を変更します。
クラスターを作成する
ノードのいずれかで、クラスターを作成します。
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allSQL Server、ファイル システム、および仮想 IP リソースのクラスター リソースを構成し、クラスターに構成をプッシュします。 次の情報が必要です。
- SQL Server リソース名: クラスター化された SQL Server のリソースの名前。
- フローティングの IP リソース名: 仮想 IP アドレスのリソースの名前。
- IP アドレス: SQL Server のクラスター化されたインスタンスに接続するのにクライアントが使用する IP アドレス。
- ファイル システム リソース名: ファイル システム リソースの名前。
- デバイス: NFS 共有パス
- デバイス: 共有へのマウント先を示すローカル パス
- fstype: ファイル共有のタイプ (つまり
nfs)
実際の環境に合わせて、次のスクリプトの値を更新します。 1 つのノードで実行し、クラスター化されたサービスを構成して開始します。
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgたとえば、次のスクリプトは、
mssqlhaという SQL Server のクラスター化されたリソースと、IP アドレスが10.0.0.99のフローティング IP のリソースを作成します。 また、ファイル システムのリソースを作成し、制約を追加して、すべてのリソースが SQL リソースと同じノードに併置されるようにします。sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfg構成がプッシュされると、1 つのノードで SQL Server が起動します。
SQL Server が起動されていることを確認します。
sudo pcs status次の例は、Pacemaker が SQL Server のクラスター化されたインスタンスを正常に開始した場合の結果を示しています。
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled