列ストア インデックス - データ読み込みガイダンス
適用対象: ![]() SQL Server
SQL Server ![]() Azure SQL データベース
Azure SQL データベース ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
標準的な SQL 一括読み込みとトリクル挿入メソッドを使用して、列ストア インデックスにデータを読み込むためのオプションと推奨事項です。 列ストア インデックスへのデータの読み込みは、分析に備えてデータをインデックスに移動するため、すべてのデータ ウェアハウスのプロセスにおいて不可欠な要素です。
列ストア インデックスを初めて使用する場合は、 「列ストア インデックス - 概要」と「列ストア インデックスのアーキテクチャ」を参照してください。
一括読み込みとは
一括読み込みは、大量の行がデータ ストアに追加される方法を表します。 これは、行のバッチを対象とするため、データを列ストア インデックスに移動する最もパフォーマンスに優れた方法です。 一括読み込みでは、行グループを最大容量まで入れ、直接列ストアに圧縮します。 行グループごとに最小値の 102,400 行に一致しない読み込みの最後の行のみが、デルタストアに移動されます。
一括読み込みを実行するには、bcp ユーティリティ、Integration Services を使用したり、ステージング テーブルから行を選択したりすることができます。
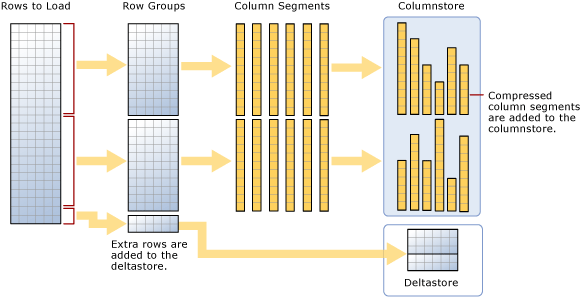
上記の図に示すように、一括読み込みでは、
- データを事前に並べ替えません。 データは受信順に行グループに挿入されます。
- バッチ サイズが 102,400 以上の場合、行は圧縮された行グループに直接読み込まれます。 効率的に一括でインポートするためには 102,400 以上のバッチ サイズを選択する必要があります。こうすると、バックグラウンド スレッドのタプル ムーバー (TM) により圧縮された行グループに最終的に行が移動される前に、データ行がデルタ行グループに移動されるのを回避できます。
- バッチ サイズが 102,400 未満の場合、または残りの行が 102,400 未満の場合、行はデルタ行グループに読み込まれます。
Note
非クラスター化列ストア インデックス データを含む行ストア テーブルでは、SQL Server は常にベース テーブルにデータを挿入します。 データが列ストア インデックスに直接挿入されることはありません。
一括読み込みには、次の組み込みのパフォーマンスの最適化があります。
並列読み込み: それぞれ別のデータ ファイルを読み込む、複数の同時一括読み込み (bcp または一括挿入) を行うことができます。 SQL Server への行ストア一括読み込みとは異なり、各一括インポート スレッドでは排他的ロックを使用して排他的にデータを別の行グループ (圧縮された行グループやデルタ行グループ) に読み込むため、
TABLOCKを指定する必要はありません。ログ記録の削減: 圧縮された行グループにデータを直接読み込むと、ログのサイズが大幅に削減されます。 たとえば、データが 10 倍に圧縮された場合、対応するトランザクション ログのサイズは約 10 倍小さくなり、TABLOCK や一括ログ/単純復旧モデルを必要としません。 デルタ行グループに移動するデータは、完全に記録されます。 これには、102,400 行未満のバッチ サイズがすべて含まれます。 ベスト プラクティスは、102,400 以上のバッチ サイズを使用することです。 TABLOCK は必要ないため、データを並行して読み込むことができます。
最小ログ記録: 最小ログ記録の前提条件に従うと、ログ記録をさらに削減できます。 ただし、行ストアへのデータの読み込みとは異なり、TABLOCK では BU (一括更新) ロックではなく、テーブルに対する X ロックが発生するため、並列データの読み込みは実行できません。 ロックについて詳しくは、「ロックおよび行のバージョン管理」をご覧ください。
ロック処理の最適化: 行グループの X ロックは、圧縮された行グループにデータを読み込むときに自動的に取得されます。 ただし、デルタ行グループへの一括読み込みの場合、X ロックは行グループで取得されますが、X 行グループ ロックはロック階層の一部ではないため、SQL Server は引き続き PAGE/EXTENT をロックします。
列ストア インデックスに非クラスター化 B ツリー インデックスがある場合、インデックス自体のロックやログの最適化は行われませんが、前述のとおり、クラスター化列ストア インデックスの最適化は適用できます。
データ変更 (挿入、削除、更新) は並列ではないため、バッチ モード操作ではありません。
デルタ行グループを最小限にする一括読み込みサイズを計画する
ほとんどの行が列ストアに圧縮され、デルタ行グループに配置されていないときに、列ストア インデックスは最高のパフォーマンスを発揮します。 行が列ストアに直接移動し、できる限りデルタストアを使用しない読み込みのサイズにすることが最適です。
次のシナリオでは、読み込まれた行が列ストアに直接移動する場合やデルタストアに移動する場合について説明します。 この例では、行グループはそれぞれ 102,400 ~ 1,048,576 個の行を持つことができます。 実際には、行グループの最大サイズは、メモリが不足している場合、1,048,576 行より小さくなることがあります。
| 一括読み込みを行う行 | 圧縮された行グループに追加される行 | デルタ行グループに追加される行 |
|---|---|---|
| 102,000 | 0 | 102,000 |
| 145,000 | 145,000 行グループのサイズ: 145,000 |
0 |
| 1,048,577 | 1,048,576 行グループのサイズ: 1,048,576 |
1 |
| 2,252,152 | 2,252,152 行グループのサイズ: 1,048,576、1,048,576、155,000 |
0 |
次の例は、1,048,577 個の行をテーブルに読み込んだ結果を示しています。 この結果では、列ストアに 1 つの圧縮された行グループ (圧縮された列セグメントとして)、およびデルタストアに 1 行があります。
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

ステージング テーブルを使用してパフォーマンスを向上させる
さまざまな変換を実行する前にデータをステージングするためにのみ読み込む場合は、ヒープ テーブルにテーブルを読み込むと、データをクラスター化列ストア テーブルに読み込む場合よりもはるかに高速に読み込まれます。 さらに、[一時テーブル][Temporary] へのデータの読み込みも、永続記憶域にテーブルを読み込むよりも高速になります。
データの読み込みの一般的なパターンでは、ステージング テーブルにデータを読み込み、変換を行ってから、以下のコマンドを使用してターゲット テーブルに読み込みます。
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
このコマンドは、bcp や一括挿入と同じように列ストア インデックスにデータを読み込みますが、データは単一のバッチにまとめられます。 ステージング テーブルの行数が 102400 未満の場合、行はデルタ行グループに読み込まれ、それ以外の場合、行は圧縮された列グループに直接読み込まれます。 この INSERT 操作はシングル スレッドの場合に限られていました。 データの並列読み込みを行う場合、複数のステージング テーブルを作成するか、ステージング テーブルの重複していない行の範囲を指定して INSERT/SELECT を実行することができます。 このような制限は SQL Server 2016 (13.x) にはありません。 次のコマンドはステージング テーブルからデータを並列で読み込みますが、TABLOCK を指定する必要があります。 これは、一括読み込みについて説明した内容と矛盾していることがありますが、主な違いは、ステージング テーブルからの並列データの読み込みが同じトランザクションで実行されることです。
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
ステージング テーブルからクラスター化列ストア インデックスへの一括読み込みで使用可能な最適化を以下に示します。
- ログの最適化: データが圧縮された行グループに読み込まれる場合は、ログ記録が縮小します。
- ロックの最適化: 圧縮された行グループにデータを読み込む場合は、行グループに対する X ロックが取得されます。 ただし、デルタ行グループでは、X ロックは行グループで取得されますが、X 行グループ ロックはロック階層の一部ではないため、SQL Server は引き続き PAGE/EXTENT をロックします。
非クラスター化インデックスが 1 つまたは複数ある場合、インデックス自体のロックやログの最適化は行われませんが、前述のとおり、クラスター化列ストア インデックスの最適化は引き続き行われます。
トリクル挿入とは
トリクル挿入は、個々の行が列ストア インデックスに移動する方法を表します。 トリクル挿入では、INSERT INTO ステートメントを使用します。 トリクル挿入を使用すると、すべての行はデルタストアに移動されます。 これは行が少数のときに便利ですが、大量の読み込みは実用的ではありません。
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Note
クラスター化列ストア インデックスに値を挿入するために INSERT INTO を使用する並行スレッドでは、同じデルタストア行グループに行が挿入される場合があります。
列グループに 1,048,576 個の行が含まれると、デルタ行グループは閉じられた見なされますが、クエリや更新/削除操作では引き続き使用できます。ただし、新しく挿入される行は既存のデルタストア列グループまたは新しく作成されたデルタストア列グループに移動します。 閉じられたデルタ行グループを 5 分程度ごとに定期的に圧縮するタプル ムーバー (TM) というバックグラウンド スレッドがあります。 次のコマンドを明示的に呼び出すことで、閉じられたデルタ行グループを圧縮できます。
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
デルタ行グループを強制的に閉じ、圧縮する場合は、以下のコマンドを実行します。 行の読み込みが終了し、新しい行は必要ない場合、このコマンドを実行できます。 デルタ行グループを明示的に閉じ、圧縮することで、より多くのストレージを確保し、分析クエリのパフォーマンスを向上させることができます。 新しい行を挿入する必要がない場合は、このコマンドを呼び出すことをお勧めします。
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
パーティション テーブルへの読み込みのしくみ
パーティション分割されたデータの場合、SQL Server はまずパーティションに各行を割り当て、次にパーティション内のデータに columnstore 処理を実行します。 各パーティションには、独自の行グループと少なくとも 1 つのデルタ行グループがあります。