対象者:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() アナリティクスプラットフォームシステム(PDW)
アナリティクスプラットフォームシステム(PDW)![]() Microsoft FabricにおけるSQLデータベース
Microsoft FabricにおけるSQLデータベース
すべての SQL Server データベースにはトランザクション ログがあり、データベース内のすべてのトランザクションとそれらのトランザクションによって加えられた変更が記録されます。 トランザクション ログはデータベースの重要なコンポーネントの 1 つであり、システム障害が発生すると、データベースを一貫性のある状態にするために求められる場合があります。 このガイドでは、トランザクション ログの物理アーキテクチャおよび論理アーキテクチャについて説明します。 アーキテクチャを理解することで、トランザクション ログを効率的に管理できるようになります。
トランザクション ログの論理アーキテクチャ
SQL Server のトランザクション ログは、論理的にはトランザクション ログが一続きのログ レコードから構成されているものとして機能します。 それぞれのログ レコードは、LSN (ログ シーケンス番号) によって識別されます。 新しい各ログ レコードは、ログの論理上の末尾に前レコードの LSN より大きな LSN を付けて書き込まれます。 ログ レコードは、作成された順で連続して保管されます。LSN2 が LSN1 より大きい場合、LSN2 によって参照されるログ レコードで示される変更は、ログ レコード LSN1 で示される変更の後に行われます。 各ログ レコードにはトランザクション ID が含まれ、どのトランザクションについてのレコードかを示します。 各トランザクションに関連付けられているログ レコードはすべて、逆方向のポインターを使用して連鎖的にリンクされており、これによってトランザクションのロールバックをスピードアップできます。
LSN の基本的な構造は [VLF ID:Log Block ID:Log Record ID] です。 詳細については、VLF およびログ ブロックのセクションを参照してください。
LSN 00000031:00000da0:0001の例を次に示します。0x31 は VLF の ID です。0xda0 はログ ブロック ID で、0x1 はそのログ ブロックの最初のログ レコードです。 LSN の例については、sys.dm_db_log_info DMV の 出力を 調べて、列を vlf_create_lsn 調べます。
データ変更のログ レコードには、実行した論理操作の記録または変更したデータの前後のイメージの記録が行われます。 前イメージは、操作が実行される前のデータのコピーです。後イメージは、操作を実行した後のデータのコピーです。
操作を復旧する手順は、ログ レコードの種類によって異なります。
論理操作が記録されている場合
- 論理操作をロールフォワードするには、その操作を再実行します。
- 論理操作をロールバックするには、逆の論理操作を実行します。
前後イメージが記録されている場合
- 操作をロールフォワードするには、後イメージを適用します。
- 操作をロールバックするには、前イメージを適用します。
トランザクション ログには各種の操作が記録されます。 記録される操作には次のようなものがあります。
各トランザクションの開始および終了。
あらゆるデータ変更 (挿入、更新、または削除)。 修正には、システム ストアド プロシージャまたは DDL (データ定義言語) ステートメントによって、システム テーブルなどのテーブルに加えられた変更が含まれます。
エクステントおよびページのすべての割り当てと割り当て解除。
テーブルまたはインデックスの作成と削除。
ロールバック操作も記録されます。 トランザクションごとにトランザクション ログの領域が予約されるので、明示的にロールバック ステートメントを実行したときやエラーが発生したときのロールバックに備え、十分なログ領域が確保されます。 予約領域のサイズは、トランザクションで実行される操作によって変わりますが、一般には各操作を記録するために使用される領域のサイズと同じです。 この予約領域は、トランザクションが完了したときに解放されます。
データベース全体で最後に書き込まれたログ レコードに正常にロールバックするために存在する必要がある最初のログ レコードのログ ファイルのセクションは、ログのアクティブ部分、 アクティブ ログ、または 末尾と呼ばれます。 これは、データベースの完全復旧を実行するために必要なログの部分です。 アクティブなログはどの部分も切り捨てることができません。 この先頭ログ レコードのログ シーケンス番号 (LSN) は、最小復旧 LSN (MinLSN) と呼ばれます。 トランザクション ログでサポートされている操作について詳しくは、「トランザクション ログ」を参照してください。
差分バックアップとログ バックアップの場合、復元されるデータベースは LSN が大きい方、つまり、より後の時点に向かって進められます。
トランザクション ログの物理アーキテクチャ
データベースのトランザクション ログは、1 つ以上の物理ファイルにマップされます。 概念的には、ログ ファイルは一続きのログ レコードです。 物理的には、一連のログ レコードは、トランザクション ログを実装する一連の物理ファイルに効率的に格納されます。 1 つのデータベースにトランザクション ログ ファイルが少なくとも 1 つ必要です。
仮想ログ ファイル (VLF)
SQL Server データベース エンジンにより、各物理ログ ファイルは内部的に多くの仮想ログ ファイル (VLF) に分割されています。 仮想ログ ファイルのサイズは固定されておらず、1 つの物理ログ ファイルに対する仮想ログ ファイルの数も決まっていません。 仮想ログ ファイルのサイズは、ログ ファイルの作成時や拡張時にデータベース エンジンにより動的に選択されます。 データベース エンジンは、いくつかの仮想ファイルを維持しようとします。 ログ ファイルを拡張した後の仮想ファイルのサイズは、既存のログのサイズと増加した新しいファイルのサイズの合計になります。 管理者が仮想ログ ファイルのサイズや数を構成または設定することはできません。
仮想ログ ファイルの作成
次の方法に従って仮想ログ ファイル (VLF) を作成します。
- SQL Server 2014 (12.x) 以降のバージョンでは、次の増加量が現在のログの物理サイズの 1/8 未満の場合、増加分のサイズに対応する 1 個の VLF を作成します。
- 次の増加分が現在のログ サイズの 1/8 を超える場合は、2014 以前の方法を使用します。
- 増加分が 64 MB 未満の場合、増加分のサイズに対応する 4 個の VLF を作成します (たとえば、1 MB 増加の場合は 4 個の 256 KB VLF を作成します)
- Azure SQL Database では、SQL Server 2022 (16.x) (すべてのエディション) 以降では、ロジックが若干異なります。 拡張が 64 MB 以下の場合、データベース エンジンは拡張サイズをカバーする VLF を 1 つだけ作成します。
- 増加分が 64 MB ~ 1 GB の場合、増加分のサイズに対応する 8 個の VLF を作成します (たとえば、512 MB 増加の場合は 8 個の 64 MB VLF を作成します)。
- 増加分が 1 GB を超える場合、増加分のサイズに対応する 16 個の VLF を作成します (たとえば、8 GB 増加の場合は 16 個の 512 MB VLF を作成します)
- 増加分が 64 MB 未満の場合、増加分のサイズに対応する 4 個の VLF を作成します (たとえば、1 MB 増加の場合は 4 個の 256 KB VLF を作成します)
小さな増加が繰り返され、ログ ファイルが大きくなった場合、多くの仮想ログ ファイルが生成されます。 これにより、データベースの起動やログのバックアップおよび復元操作の遅延、トランザクション レプリケーション/CDC および Always On のやり直しでの待機時間が発生する可能性があります。 逆に、増加の回数が少なく、あるいはたった 1 回でログ ファイルが大きなサイズになった場合、非常に大きな仮想ログ ファイルが少しだけ生成されます。 トランザクション ログの必須サイズを正しく見積もる方法や自動拡張設定については、「トランザクション ログ ファイルのサイズの管理」の推奨事項セクションを参照してください。
必要な増分を利用し、必要なサイズに近いサイズ値をログ ファイルを作成し、最適な VLF 配布を達成することと、比較的大きな growth_increment 値を設定することをお勧めします。
次のヒントを参照し、現在のトランザクション ログ サイズに最適な VLF 配布を決定してください。
-
サイズ値は
SIZEのALTER DATABASE引数で設定されますが、これはログ ファイルの初期サイズとなります。 -
growth_increment 値 (自動拡張値とも呼ばれています) は
FILEGROWTHのALTER DATABASE引数で設定されますが、これは新しい領域が必要になるたびにファイルに追加される領域の量です。
FILEGROWTH の SIZE 引数と ALTER DATABASE 引数の詳細については、「ALTER DATABASE (Transact-SQL) の File および Filegroup オプション」を参照してください。
Tip
指定されたインスタンスにおいて、すべてのデータベースの現在のトランザクション ログ サイズに最適な VLF 配布と必要なサイズを得るために必要な増分を決定するには、GitHub のこの Fixing-VLFs スクリプトをご覧ください。
VLF が多すぎるとどうなりますか?
データベース復旧プロセスの初期段階では、SQL Server はすべてのトランザクション ログ ファイル内のすべての VLF を検出し、これらの VLF の一覧を作成します。 このプロセスは、特定のデータベースに存在する VLF の数によっては、長い時間がかかる場合があります。 VLF が多いほど、プロセスは長くなります。 頻繁なトランザクション ログの自動拡張または手動拡張が少しずつ発生すると、データベースの VLF が大量に発生する可能性があります。 VLF の数が数十万の範囲に達すると、次の症状の一部または大部分が発生する可能性があります。
- 1 つ以上のデータベースは、SQL Server の起動時に復旧を完了するのに非常に長い時間がかかります。
- データベースの復元が完了するまでに非常に長い時間がかかります。
- データベースのアタッチを試みると、完了するまでに非常に長い時間がかかります。
- データベース ミラーリングを設定しようとすると、タイムアウトを示すエラー メッセージ 1413、1443、1479 が表示されます。
- データベースを復元しようとすると、メモリ関連のエラー (701 など) が発生します。
- トランザクション レプリケーションまたは変更データ キャプチャで膨大な待機時間が発生する可能性があります。
SQL Server エラー ログを調べると、データベース復旧プロセスの分析フェーズまでにかなりの時間が費やされていることがわかります。 例えば次が挙げられます。
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
さらに、多数の VLF を含むデータベースを復元すると、SQL Server で MSSQLSERVER_9017 エラーが記録される可能性があります。
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
詳細については、「MSSQLSERVER_9017」を参照してください。
多数の VLF を使用してデータベースを修正する
最大数千個など、適切な量の VLF の合計数を保持するには、次の手順を実行して、トランザクション ログ ファイルをリセットして、少数の VLF を含めることができます。
トランザクション ログ ファイルを手動で圧縮します。
次の T-SQL スクリプトを使用して、1 つの手順で必要なサイズにファイルを手動で拡張します。
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Note
この手順は、SQL Server Management Studio でもデータベースのプロパティ ページを使用して実行できます。
少ない VLF でトランザクション ログ ファイルの新しいレイアウトを設定したら、トランザクション ログの自動拡張設定を確認して必要な変更を行います。 この設定の検証により、ログ ファイルで今後同じ問題が発生することを回避できます。
これらの操作を実行する前に、後で問題が発生した場合に備えて、有効な復元可能なバックアップがあることを確認してください。
指定されたインスタンスにおいて、すべてのデータベースの現在のトランザクション ログ サイズに最適な VLF 配布と必要なサイズを得るために必要な増分を決定するには、このスクリプトをご覧ください。
ログ ブロック
各 VLF には、1 つ以上 のログ ブロックが含まれています。 各ログ ブロックは、(4 バイト境界に調整された) ログ レコードで構成されます。 ログ ブロックはサイズが可変であり、常に 512 バイト (SQL Server がサポートする最小セクター サイズ) の整数倍数であり、最大サイズは 60 KB です。 ログ ブロックは、トランザクション ログの I/O の基本単位です。
要約すると、ログ ブロックは、ログ レコードをディスクに書き込むときにトランザクション ログの基本単位として使用されるログ レコードのコンテナーです。
VLF 内の各ログ ブロックは、その ブロック オフセットによって一意にアドレス指定されます。 最初のブロックには常に、VLF の最初の 8 KB を超えるブロック オフセットがあります。
一般に、VLF は常にログ ブロックでいっぱいになります。 VLF の最後のログ ブロックが空である可能性があります (たとえば、ログ レコードが含まれていない)。 これは、書き込まれるログ レコードが現在のログ ブロックに収まらない場合や、VLF 上の残りの領域がこのログ レコードを保持するのに不十分な場合に発生します。 この場合、VLF を満たす空のログ ブロックが作成されます。 ログ レコードは、次の VLF の最初のブロックに挿入されます。
トランザクション ログの循環的な性質
トランザクション ログは、循環して使用されるファイルです。 たとえば、4 つの VLF に分割された 1 つの物理ログ ファイルが格納されたデータベースがあるとします。 このデータベースの作成時、論理ログ ファイルは物理ログ ファイルの先頭から始まります。 新しいログ レコードは論理ログの末尾に追加され、物理ログの末尾に向かって拡張されます。 ログの切り捨てにより、最小復旧ログ シーケンス番号 (MinLSN) より前にあるすべての仮想ログ レコードが解放されます。 MinLSN は、データベース全体を正常にロールバックするために必要な最も古いログ レコードのログ シーケンス番号です。 例として挙げたデータベースのトランザクション ログは、次の図のようになります。
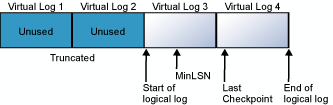
論理ログの末尾が物理ログ ファイルの末尾に達すると、新しいログ レコードはまた物理ログ ファイルの先頭から記録されていきます。
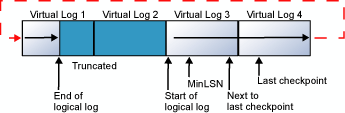
このサイクルは、論理ログの末尾が論理ログの先頭に達しない限り、無限に繰り返されます。 古いログ レコードが頻繁に切り捨てられ、次のチェックポイントで作成されるすべての新規ログ レコードを格納するのに必要な領域が常に確保されている場合、論理ログがいっぱいになることはありません。 ただし、論理ログの末尾が論理ログの先頭に達した場合には、次のいずれかの処理が発生します。
ログで
FILEGROWTHの設定が有効になっていて、ディスクの領域が使用できる場合、ファイルは growth_increment パラメーターで指定した量だけ拡張され、新規ログ レコードがその拡張部分に追加されます。FILEGROWTH設定 の 詳細については、「ALTER DATABASE (Transact-SQL) ファイル および ファイル グループ オプション」を参照してください。FILEGROWTHの設定が有効になっていない場合、またはログ ファイルを保持しているディスクの空き領域が growth_increment で指定した量よりも少ない場合は、エラー 9002 が生成されます。 詳細については、「満杯になったトランザクション ログのトラブルシューティング (SQL Server エラー 9002)」を参照してください。
ログに複数の物理ログ ファイルが含まれている場合、論理ログは、すべての物理ログ ファイルの領域を使用し終えてから、最初の物理ログ ファイルの先頭に戻ります。
Important
トランザクション ログ サイズ管理の詳細については、「トランザクション ログ ファイルのサイズの管理」を参照してください。
ログの切り捨て
ログの切り捨ては、ログがいっぱいにならないようにするために不可欠です。 ログの切り捨てでは、SQL Server データベースの論理トランザクション ログから非アクティブな仮想ログ ファイルが削除されます。これにより、論理ログの領域が解放され、物理トランザクション ログで再利用できるようになります。 トランザクション ログが切り捨てられなければ、物理ログ ファイルに割り当てられているディスク上の領域がいっぱいになってしまいます。 ただし、ログの切り捨て前に、チェックポイント操作が必要です。 チェックポイントでは、現在メモリにある修正ページ (ダーティ ページ) とトランザクション ログ情報がメモリからディスクに書き込まれます。 チェックポイントが実行されると、トランザクション ログの非アクティブな部分は再利用できるようにマークが付けられます。 その後、ログの切り捨てにより、非アクティブな部分を解放できます。 チェックポイントの詳細については、「データベース チェックポイント (SQL Server)」を参照してください。
次の図は、切り捨てを行う前と後のトランザクション ログを示しています。 最初の図は、切り捨てが行われていないトランザクション ログを示しています。 現在、4 つの仮想ログ ファイルが論理ログで使用されています。 この論理ログは最初の仮想ログ ファイルの先頭から始まり、仮想ログ 4 で終了します。 MinLSN レコードは仮想ログ 3 にあります。 仮想ログ 1 および仮想ログ 2 には、非アクティブなログ レコードのみが含まれています。 これらのレコードは切り捨てることができます。 仮想ログ 5 はまだ使用されていないので、現在の論理ログには含まれていません。
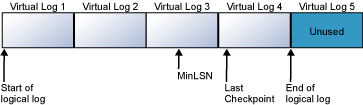
2 番目の図は、切り捨て後のログの状態を示しています。 仮想ログ 1 および仮想ログ 2 は再利用のために解放されています。 この時点で、論理ログは仮想ログ 3 の先頭から始まっています。 仮想ログ 5 はまだ使用されていないので、現在の論理ログには含まれていません。
何かの理由で遅延が発生している場合を除いて、ログの切り捨ては、次のイベントの後に自動的に発生します。
- 単純復旧モデルでは、チェックポイント以降。
- 完全復旧モデルまたは一括ログ復旧モデルで、前回のバックアップ後にチェックポイントが発生している場合は、ログ バックアップの後。
ログの切り捨ては、さまざまな要因で遅延が発生する場合があります。 ログの切り捨てで長時間の遅延が発生すると、トランザクション ログがいっぱいになる可能性があります。 詳細については、「ログの切り捨てが遅れる原因となる要因」と「満杯になったトランザクション ログのトラブルシューティング (SQL Server エラー 9002)」を参照してください。
先行書き込みトランザクション ログ
このセクションでは、データの変更をディスクに記録するときの先行書き込みトランザクション ログの役割について説明します。 SQL Server では、先行書き込みログ (WAL) アルゴリズムを使用します。これにより、関連付けられているログ レコードより前にデータ変更がディスクに書き込まれることがなくなります。 これにより、トランザクションの ACID プロパティが維持されます。
WAL の詳細については、「SQL Server I/O の基礎」を参照してください。
先書きログがトランザクション ログと関連してどのように機能するのかを理解するには、変更されたデータがディスクに書き込まれるしくみを把握しておくことが重要です。 SQL Server はバッファー キャッシュ (バッファープール) を保持し、データを取得する必要がある場合は、そのキャッシュの中へデータ ページを読み取ります。 ページがバッファー キャッシュ内で変更されたとき、その変更が直ちにディスクに書き戻されるわけではありません。代わりに、そのページは ダーティとマークされます。 データ ページが物理的にディスクに書き込まれる前には、複数回の論理書き込みが行われる可能性があります。 論理書き込みを行うたびに、トランザクション ログ レコードが、変更を記録するログ キャッシュに挿入されます。 ログ レコードは、関連付けられているダーティ ページがバッファー キャッシュから削除されディスクに書き込まれる前に、ディスクに書き込まれる必要があります。 チェックポイント プロセスでは、指定されたデータベースからのページを含むバッファーのバッファー キャッシュを定期的にスキャンし、ダーティ ページをすべてディスクに書き込みます。 チェックポイントは、すべてのダーティ ページがディスクに書き込まれたことを確認するために作成されるポイントで、その後の復旧の時間を短縮します。
変更されたデータ ページをバッファー キャッシュからディスクに書き込むことを "ページのフラッシュ" といいます。 SQL Server には、関連付けられているログ レコードの書き込み前にダーティ ページをフラッシュしないためのロジックが用意されています。 ログ レコードは、ログ バッファーがフラッシュされるときにディスクに書き込まれます。 これは、トランザクションがコミットされたとき、またはログ バッファーがいっぱいになったときに必ず発生します。
トランザクション ログのバックアップ
このセクションでは、トランザクション ログのバックアップと復元 (適用) の方法について説明します。 完全復旧モデルと一括ログ復旧モデルでは、データを復旧するためにトランザクション ログを定期的にバックアップすること (ログのバックアップ) が必要不可欠です。 ログのバックアップは、完全バックアップの実行中でも行うことができます。 復旧モデルの詳細については、「 SQL Server データベースのバックアップと復元」を参照してください。
最初のログ バックアップを作成する前に、データベース バックアップや一連のファイル バックアップの最初のバックアップを行って、完全バックアップを作成する必要があります。 ファイル バックアップだけを使ったデータベースの復元は複雑になる可能性があります。 したがって、可能な時点でデータベースの完全バックアップを行うことから始めることをお勧めします。 その後、トランザクション ログを定期的にバックアップする必要があります。 その結果、作業損失の可能性が最小限に抑えられるだけでなく、トランザクション ログの切り捨ても可能になります。 一般に、トランザクション ログは、通常のログ バックアップ後に毎回切り捨てられます。
復元する必要があるログ バックアップの数を制限するには、定期的なデータのバックアップが不可欠です。 たとえば、データベースの完全バックアップを毎週実行し、差分バックアップを毎日実行するようにスケジュールできます。
復旧計画を導入するときは必要な RTO と RPO について、特に、データベースの完全バックアップと差分バックアップの頻度について検討してください。
トランザクション ログ バックアップの詳細については、「トランザクション ログ バックアップ (SQL Server)」を参照してください。
バックアップの頻度とビジネス要件
ビジネス要件をサポートするために十分なログ バックアップを頻繁に実行する必要があります。具体的には、ログ ストレージの破損が原因である可能性があるなどの作業損失に対する許容度が必要です。
ログ バックアップを行う適切な頻度は、作業損失に対する許容範囲と、ログ バックアップを保存、管理、復元できる量とのバランスによります。 復旧計画を導入するときは必要な回復時間目標 (RTO) と回復ポイントの目標 (RPO) について、特にログ バックアップの頻度について検討してください。
15 分から 30 分間隔でログ バックアップを行えば十分でしょう。 業務上、作業損失の可能性を最小限に抑えることが求められる場合は、ログ バックアップの頻度を増やすことを検討します。 ログ バックアップの頻度を増やせば、ログ切り捨ての頻度も高くなり、ログ ファイルが小さくなる利点もあります。
ログ チェーン
ログ バックアップの連続的なシーケンスは、 ログ チェーンと呼ばれます。 ログ チェーンは、データベースの完全バックアップから始まります。 通常、新しいログ チェーンが開始されるのは、データベースが最初にバックアップされたとき、または復旧モデルを単純復旧から完全復旧または一括ログ復旧に変更したときだけです。 データベースの完全バックアップの作成時に既存のバックアップ セットを上書きしない限り、既存のログ チェーンはそのまま残ります。 ログ チェーンがそのまま残っている場合は、メディア セット内にあるデータベースの完全バックアップからデータベースを復元し、その後で復旧ポイントに達するまで後続のログ バックアップをすべて復元できます。 復旧ポイントは、最後のログ バックアップの末尾、または任意のログ バックアップの特定の復旧ポイントである場合があります。 詳細については、「トランザクション ログ バックアップ (SQL Server)」を参照してください。
データベースを障害の発生時点まで復元するには、ログ チェーンが途切れていないことが条件になります。 つまり、トランザクション ログ バックアップのシーケンスは、障害の発生時点まで途切れずに続いている必要があります。 ログのシーケンスの始まりは、復元するデータ バックアップの種類 (データベース バックアップ、部分バックアップ、ファイル バックアップ) によって異なります。 データベース バックアップまたは部分バックアップの場合、ログ バックアップのシーケンスはデータベース バックアップまたは部分バックアップの最後から始まっている必要があります。 一連のファイル バックアップの場合、ログ バックアップのシーケンスはファイル バックアップの完全なセットから始まっている必要があります。 詳細については、「トランザクション ログ バックアップの適用 (SQL Server)」を参照してください。
ログ バックアップの復元
ログ バックアップを復元すると、トランザクション ログに記録された変更がロールフォワードされ、ログ バックアップ操作が開始された時点のデータベースの正確な状態が再現されます。 データベースを復元するときは、復元するデータベースの完全バックアップ後に作成されたログ バックアップを復元するか、復元する最初のファイル バックアップの先頭からログ バックアップを復元する必要があります。 通常、最新のデータまたは差分バックアップを復元した後、復旧ポイントに到達するまで一連のログ バックアップを復元する必要があります。 その後、データベースを復旧します。 その結果、復旧を開始したときに不完全だったトランザクションがすべてロールバックされ、データベースがオンラインになります。 データベースが復旧された後は、それ以上バックアップを復元できません。 詳細については、「トランザクション ログ バックアップの適用 (SQL Server)」を参照してください。
チェックポイントとログのアクティブな部分
チェックポイントにより、現在のデータベースのバッファー キャッシュのダーティ データ ページは、ディスクにフラッシュされます。 チェックポイントを使用すると、データベースの完全復旧時に処理する必要があるログのアクティブな部分を最小限に抑えることができます。 完全復旧時には、次の種類の操作が行われます。
- システムが停止する前にディスクにフラッシュされていなかった変更のログ レコードがロールフォワードされます。
-
COMMITのないトランザクションやROLLBACKログ レコードがないトランザクションなど、不完全なトランザクションに関連付けられているすべての変更がロールバックされます。
チェックポイント操作
チェックポイントにより、データベースで次の処理が実行されます。
チェックポイントの開始位置を示すレコードをログ ファイルに書き込みます。
チェックポイント用に記録された情報をチェックポイント ログ レコードのチェーンに格納します。
チェックポイントで記録される情報の 1 つは、データベース全体を正常にロールバックするために必要な最初のログ レコードのログ シーケンス番号 (LSN) です。 この LSN は、最小復旧 LSN (MinLSN) といいます。 MinLSN は、次の LSN の最小値です。
- チェックポイントの開始の LSN
- 最も古いアクティブなトランザクションの開始の LSN
- まだディストリビューション データベースに配信されていない、最も古いレプリケーション トランザクションの開始の LSN
チェックポイント レコードには、データベースに変更を加えたすべてのアクティブなトランザクションの一覧も含まれます。
データベースで単純復旧モデルが使用されている場合、MinLSN より前にある領域を再利用するようにマークを付けます。
すべてのダーティ ログとダーティ データ ページをディスクに書き込みます。
チェックポイントの終了位置を示すレコードをログ ファイルに書き込みます。
このチェーンの開始の LSN をデータベース ブート ページに書き込みます。
チェックポイントが作成される動作
チェックポイントは次の状況で作成されます。
CHECKPOINTステートメントが明示的に実行されます。 接続を確立するために、現在のデータベースでチェックポイントが作成されます。データベースで最小ログ記録操作が実行された場合。たとえば、一括ログ復旧モデルを使用しているデータベースで一括コピー操作が実行された場合です。
データベース ファイルは、
ALTER DATABASEを使用して追加または削除されました。SQL Server のインスタンスは、
SHUTDOWNステートメントによって、または SQL Server (MSSQLSERVER) サービスを停止することによって停止されます。 どちらの場合でも、SQL Server のインスタンスの各データベースにチェックポイントが作成されます。データベースの復旧にかかる時間を短縮するために、SQL Server のインスタンスにより、各データベースで定期的に自動チェックポイントが作成されている場合。
データベースのバックアップが作成された場合。
データベースのシャットダウンが必要な動作が実行された場合。 これは、
AUTO_CLOSEオプションがONされ、データベースへの最後のユーザー接続が閉じられたときに発生する可能性があります。 もう 1 つの例は、データベースの再起動を必要とするデータベース オプションの変更が行われた場合です。
自動チェックポイント
SQL Server データベース エンジンでは自動チェックポイントが生成されます。 自動チェックポイントが作成される間隔は、使用されているログ領域の量と最後のチェックポイントが作成されてからの経過時間に基づいています。 データベースにほとんど変更が加えられない場合、自動チェックポイントが作成される間隔は変化して長くなります。 また、多くのデータが変更される場合、自動チェックポイントは頻繁に作成されます。
[復旧間隔] サーバー構成オプションを使用して、サーバー インスタンス上のすべてのデータベースの自動チェックポイントの間隔を計算します。 このオプションでは、システムの再起動時にデータベース エンジンでデータベースの復旧に使用できる最長時間を指定します。 データベース エンジンでは、復旧操作時に [復旧間隔] オプションで指定された時間内に処理できる推定ログ レコード数が算出されます。
自動チェックポイントの作成間隔は、復旧モデルによっても異なります。
データベースで完全復旧モデルまたは一括ログ復旧モデルを使用している場合、[復旧間隔] オプションで指定された時間内に処理できるとデータベース エンジンが算出したログ レコード数に達するたびに、自動チェックポイントが作成されます。
データベースで単純復旧モデルを使用している場合、ログ レコード数が次の 2 つの値のうち、小さい方の値に達するたびに自動チェックポイントが作成されます。
- ログが全体の 70% に達したとき。
- [復旧間隔] オプションで指定された時間内に処理できるとデータベース エンジンが推定したログ レコード数に達したとき。
回復間隔の設定については、「 サーバー構成: 復旧間隔 (分)」を参照してください。
Tip
一部の種類のチェックポイントでは、データベース管理者が -k SQL Server の詳細設定オプションを使用して、I/O サブシステムのスループットに基づいてチェックポイントの I/O 動作を調整できます。
-k 設定オプションは、自動チェックポイントと、-k を使用しなければ調整されないチェックポイントに適用されます。
データベースで単純復旧モデルを使用している場合、自動チェックポイントにより、トランザクション ログの未使用のセクションが切り捨てられます。 ただし、データベースで完全復旧モデルまたは一括ログ復旧モデルを使用している場合は、自動チェックポイントにより、ログが切り捨てられることはありません。 詳細については、「トランザクション ログ」を参照してください。
CHECKPOINT ステートメントには、チェックポイントを完了するための要求された期間 (秒単位) を指定する省略可能なcheckpoint_duration引数が提供されるようになりました。 詳細については、「 CHECKPOINT」を参照してください。
アクティブ ログ
ログ ファイルの MinLSN から最後に書き込まれたログ レコードまでのセクションを、ログのアクティブな部分 (アクティブなログ) と呼びます。 これは、データベースの完全復旧を実行するのに必要なログのセクションです。 アクティブなログはどの部分も切り捨てることができません。 すべてのログ レコードは、MinLSN より前にあるログの部分から切り離す必要があります。
下図に、2 つのアクティブなトランザクションがあるトランザクション ログの終了を単純化したものを示します。 チェックポイント レコードは単一のレコードに圧縮されています。

LSN 148 はトランザクション ログの最後のレコードです。 LSN 147 に記録されたチェックポイントが処理された時点では、Tran 1 は既にコミットされており、Tran 2 だけがアクティブなトランザクションでした。 このため、Tran 2 の最初のログ レコードが、前回のチェックポイントの時点でアクティブなトランザクションの最も古いログ レコードになります。 したがって LSN 142、つまり Tran 2 の Begin トランザクション レコードが MinLSN になります。
長時間トランザクション
アクティブなログには、コミットされていないすべてのトランザクションのあらゆる部分が含まれている必要があります。 トランザクションを開始したアプリケーションによりトランザクションがコミットまたはロールバックされないと、データベース エンジンでは MinLSN を進めることができません。 このことが原因で、次の 2 つの問題が発生します。
- トランザクションにより多くの変更が加えられ、これをコミットせずにシステムをシャットダウンした場合、次にシステムを再起動したときの復旧フェーズは [復旧間隔] オプションで指定した時間よりもかなり長くかかることがあります。
- ログは MinLSN を超えた位置で切り捨てることができないので、ログのサイズが非常に大きくなることがあります。 この現象は、自動チェックポイントのたびにトランザクション ログが切り捨てられる単純復旧モデルをデータベースで使用している場合でも発生します。
実行時間の長いトランザクションの復旧とこの記事で説明する問題は、高速データベース復旧を使用して回避できます。高速データベース復旧は、SQL Server 2019 (15.x) 以降および Azure SQL Database で使用できます。
レプリケーション トランザクション
ログ リーダー エージェントは、トランザクション レプリケーション用に構成した各データベースのトランザクション ログを監視し、レプリケーションのマークが付けられたトランザクションをトランザクション ログからディストリビューション データベースにコピーします。 アクティブなログには、レプリケーション用にマークされていて、まだディストリビューション データベースに配信されていないすべてのトランザクションが含まれている必要があります。 これらのトランザクションが時間どおりにレプリケートされない場合、そのことが原因でログを切り捨てられなくなる場合もあります。 詳細については、「 Transactional Replication」 (トランザクション レプリケーション) を参照してください。