CREATE TABLE AS SELECT
適用対象: ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) は、使用可能な最も重要な T-SQL 機能の 1 つです。 これは SELECT ステートメントの出力に基づいて新しいテーブルを作成する完全に並列化された操作です。 CTAS は、テーブルのコピーを作成する最も簡単で速い方法です。
たとえば、次のような場合に CTAS を使用します。
- 異なるハッシュ ディストリビューション列を持つテーブルを再作成する。
- レプリケート済みとしてテーブルを再作成する。
- テーブル内の一部の列でのみ、列ストア インデックスを作成する。
- 外部データをクエリまたはインポートする。
Note
CTAS はテーブルの作成機能に加えられたものであるため、このトピックでは CREATE TABLE トピックの内容は繰り返しません。 代わりに、CTAS と CREATE TABLE のステートメントの違いについて説明します。 CREATE TABLE の詳細については、CREATE TABLE (Azure Synapse Analytics) ステートメントを参照してください。
- この構文は、Azure Synapse Analytics のサーバーレス SQL プールでサポートされていません。
- CTAS は、Microsoft Fabric のウェアハウスでサポートされています。
構文
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
引数
詳細については、CREATE TABLE の「引数」セクションを参照してください。
列のオプション
column_name [ ,...n ]
列名では、CREATE TABLE に示されている列のオプションは使用できません。 代わりに、新しいテーブルには 1 つ以上の列名のオプション リストを指定できます。 新しいテーブルの列では、指定した名前が使用されます。 列名を指定する場合、列リスト内の列の数は、SELECT の結果内の列の数と一致する必要があります。 列名を指定しない場合、新しいターゲット テーブルでは、SELECT ステートメントの結果の列名が使用されます。
データ型、照合順序、NULL 値の許容など、他の列オプションを指定することはできません。 これらの各属性は、SELECT ステートメントの結果から派生されます。 ただし、SELECT ステートメントを使用して、属性を変更することができます。 例については、「CTAS を使用して列属性を変更する」を参照してください。
テーブル分散オプション
最適な分散オプションの選択方法などの詳細については、CREATE TABLE の「Table distribution options」 (テーブル分散オプション) セクションを参照してください。 実際の使用状況やサンプル クエリに基づきテーブルに対してどの分散が選択されるかに関する推奨事項については、「Azure Synapse SQL の分散アドバイザー」を参照してください。
DISTRIBUTION = HASH (distribution_column_name) | ROUND_ROBIN | REPLICATE CTAS ステートメントには分散オプションが必要であり、既定値はありません。 これは、既定値を持つ CREATE TABLE とは異なります。
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] ) 最大 8 列のハッシュ値に基づいて行を分散し、ベース テーブル データのより均等な分散を可能にし、時間の経過と共にデータ スキューを減らし、クエリのパフォーマンスを向上させます。
Note
- 機能を有効にするには、このコマンドを使ってデータベースの互換レベルを 50 に変更します。 データベース互換レベルの設定について詳しくは、「ALTER DATABASE SCOPED CONFIGURATION」をご覧ください。 例:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - 複数列分散 (MCD) 機能を無効にするには、このコマンドを実行してデータベースの互換レベルを AUTO に変更します。 例:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;既存の MCD テーブルは維持されますが、読み取り不可になります。 MCD テーブルに対するクエリでは、次のエラーが返されます:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- MCD テーブルに再びアクセスできるようにするには、もう一度機能を有効にします。
- MCD テーブルにデータを読み込むには、CTAS ステートメントを使用します。データ ソースは Synapse SQL テーブルである必要があります。
- MCD HEAP ターゲット テーブルの CTAS はサポートされていません。 代わりに、回避策として INSERT SELECT を使用し、データを MCD HEAP テーブルに読み込みます。
- スクリプトの生成に SSMS を使用した MCD テーブルの作成は、現在、SSMS バージョン 19 以降でサポートされています。
最適な分散オプションの選択方法などの詳細については、CREATE TABLE の「Table distribution options」 (テーブル分散オプション) セクションを参照してください。
使用するべき最適なディストリビューションについての実際のワークロードに基づく推奨事項については、「Synapse SQL ディストリビューション アドバイザー (プレビュー)」を参照してください。
テーブル パーティションのオプション
CTAS ステートメントは、ソース テーブルがパーティション分割されている場合でも、既定では、非パーティション テーブルを作成します。 CTAS ステートメントを使用して、パーティション テーブルを作成するには、パーティション オプションを指定する必要があります。
詳細については、CREATE TABLE の「Table partition options」 (テーブル パーティションのオプション) セクションを参照してください。
SELECT ステートメント
SELECT ステートメントは、CTAS と CREATE TABLE の基本的な違いです。
WITH common_table_expression
共通テーブル式 (CTE) と呼ばれる一時的な名前付き結果セットを指定します。 詳細については、「WITH common_table_expression (Transact-SQL)」を参照してください。
SELECT select_criteria
SELECT ステートメントの結果を新しいテーブルに追加します。 select_criteria は、新しいテーブルにコピーするデータを決定する SELECT ステートメントの本文です。 SELECT ステートメントについては、「SELECT (Transact-SQL)」を参照してください。
クエリ ヒント
ユーザーは MAXDOP を整数値に設定し、並列処理の最大値を制御できます。 MAXDOP が 1 に設定されていると、クエリは 1 つのスレッドによって実行されます。
アクセス許可
CTAS には、select_criteria で参照されるすべてのオブジェクトに対する SELECT 権限が必要です。
テーブルを作成する権限については、CREATE TABLE の「権限」を参照してください。
解説
詳細については、CREATE TABLE の「全般的な解説」を参照してください。
制限事項と制約事項
制限事項と制限の詳細については、CREATE TABLE の「 Limitations and Restrictions 」を参照してください。
順序付けされたクラスター化列ストア インデックスは、文字列型の列を除く Azure Synapse Analytics でサポートされている任意のデータ型の列に作成できます。
CTAS では SET ROWCOUNT (Transact-SQL) の効果はありません。 同様の動作を実現するには、TOP (Transact-SQL) を使用します。
CTAS は、
SELECTステートメントの一部としてOPENJSON関数をサポートしていません。 代わりに、INSERT INTO ... SELECTを使用します。 次に例を示します。DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
ロック動作
詳細については、CREATE TABLE の「ロック動作」を参照してください。
パフォーマンス
ハッシュ分散テーブルの場合、CTAS を使用して、結合と集計のパフォーマンスを高めるために異なる分散列を選択できます。 異なる分散列を選択することが目的ではない場合、同じ分散列を指定すると、行の再分散が避けられるため、CTAS の最高のパフォーマンスが得られます。
CTAS を使用してテーブルを作成するときに、パフォーマンスが重要でない場合は、分散列を決定しなくてすむように ROUND_ROBIN を指定できます。
後続のクエリでのデータ移動を避けるため、REPLICATE を指定できますが、各計算ノードにテーブルの完全なコピーを読み込むための記憶域は増加します。
テーブルのコピー例
A. CTAS を使用したテーブルのコピー
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
CTAS の最も一般的な使用方法の 1 つとして、DDL を変更できるようにテーブルのコピーを作成することが考えられます。 たとえば、最初に ROUND_ROBIN としてテーブルを作成し、それを列で分散されるテーブルに変更する必要がある場合、CTAS を使用して分散列を変更します。 また、CTAS を使用して、パーティション、インデックス、列の型を変更することができます。
たとえば、HEAP を指定し、既定の分散の種類である ROUND_ROBIN を使用して、このテーブルを作成したとします。
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
ここで、クラスター化列ストア テーブルのパフォーマンスを利用できるように、クラスター化列ストア インデックスを持つこのテーブルの新しいコピーを作成する必要があります。 また、このテーブルを ProductKey で分散させたいとします。この列での結合が予想され、ProductKey での結合中にデータを移動したくないためです。 さらに、OrderDateKey にパーティションを追加して、古いパーティションをドロップすることによって古いデータをすぐに削除できるようにしたいとします。 次に示すのが、古いテーブルを新しいテーブルにコピーする CTAS ステートメントです。
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
最終的に、新しいテーブルの名前を変更して、新しいテーブルを置き換えてから古いテーブルを削除できます。
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
列のオプション例
B. CTAS を使用して列属性を変更する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
この例では CTAS を使用して、DimCustomer2 テーブルのデータ型、NULL 値の許容、いくつかの列の照合順序を変更します。
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
最後の手順として、RENAME (Transact-SQL) を使用して、テーブル名を切り替えることができます。 これにより、DimCustomer2 が新しいテーブルになります。
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
テーブルの分散例
C. CTAS を使用してテーブルの分散方法を変更する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
この簡単な例では、テーブルの分散方法を変更する方法を示します。 これを行う方法のしくみを表示するには、ハッシュ分散テーブルをラウンドロビンに変更してから、ラウンドロビン テーブルをハッシュ分散に戻します。 最終的なテーブルは元のテーブルと一致します。
ほとんどの場合、ハッシュ分散テーブルをラウンドロビン テーブルに変更する必要はありません。 多くの場合、ラウンドロビン テーブルをハッシュ分散テーブルに変更する必要がある場合があります。 たとえば、最初にラウンド ロビンとして新しいテーブルを読み込み、後で、結合パフォーマンスを向上させるためにハッシュ分散テーブルに移行する場合があります。
この例では AdventureWorksDW サンプル データベースを使用します。 Azure Synapse Analytics バージョンをロードするには、「クイックスタート: Azure portal から Azure Synapse Analytics の専用 SQL プール (以前の SQL DW) を作成し、クエリを実行する」を参照してください。
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
次に、ハッシュ分散テーブルに戻します。
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. CTAS を使用してテーブルをレプリケートされたテーブルに変換する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
この例は、ラウンドロビン テーブルまたはハッシュ分散テーブルをレプリケートされたテーブルに変換する場合に適用されます。 この特定の例では、分散の種類を変更する前の方法を 1 歩進めた方法を使用します。 DimSalesTerritory はディメンションであり、より小さいテーブルである可能性があるため、他のテーブルとの結合時にデータが移動されないようにテーブルをレプリケート済みとして再作成することを選択できます。
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. CTAS を使用して列が少ないテーブルを作成する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
次の例では、myTable (c, ln) という名前のラウンドロビン分散テーブル テーブルを作成します。 新しいテーブルには 2 つの列のみがあります。 列名には、SELECT ステートメントの列の別名を使用します。
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
クエリ ヒントの例
F. CREATE TABLE AS SELECT (CTAS) でクエリ ヒントを使用する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
このクエリは、CTAS ステートメントでクエリの結合ヒントを使用するための基本構文を示しています。 クエリが送信されると、Azure Synapse Analytics では、分散ごとにクエリ プランを生成する際にハッシュ結合方法が適用されます。 ハッシュ結合のクエリ ヒントの詳細については、「OPTION 句 (Transact-SQL)」を参照してください。
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
外部テーブルの例
G. CTAS を使用して Azure BLOB ストレージからデータをインポートする
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
外部テーブルからデータをインポートするには、CREATE TABLE AS SELECT を使用して外部テーブルから選択します。 外部テーブルからデータを選択して Azure Synapse Analytics に格納する構文は、通常のテーブルからデータを選択する構文と同じです。
次の例では、Azure Blob Storage アカウントのデータに対して外部テーブルを定義します。 次に CREATE TABLE AS SELECT を使用して、外部テーブルから選択します。 これにより、Azure Blob Storage のテキスト区切りファイルからデータがインポートされて、新しい Azure Synapse Analytics テーブルにデータが格納されます。
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. CTAS を使用して外部テーブルから Hadoop データをインポートする
適用対象: Analytics Platform System (PDW)
外部テーブルからデータをインポートするには、CREATE TABLE AS SELECT を使用して外部テーブルから選択するだけです。 外部テーブルからデータを選択して Analytics Platform System (PDW) に格納する構文は、通常のテーブルからデータを選択する構文と同じです。
次の例では、Hadoop クラスターに外部テーブルを定義します。 次に CREATE TABLE AS SELECT を使用して、外部テーブルから選択します。 これで、Hadoop のテキスト区切りファイルからデータがインポートされ、新しい Analytics Platform System (PDW) テーブルにデータが格納されます。
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
CTAS を使用して SQL Server コードを置き換える例
CTAS を使用して、サポートされていない一部の機能に対処します。 データ ウェアハウスでコードを実行できるだけでなく、既存のコードを書き直して CTAS を使用することで、通常はパフォーマンスが向上します。 これは、完全に並列化された設計の結果です。
Note
"CTAS を第一" に考えてみてください。 CTAS を使用して問題を解決できると思われる場合、結果としてより多くのデータを書き込むことになる場合でも、一般的にはこれが最良の方法です。
I. SELECT..INTO の代わりに CTAS を使用する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
SQL Server コードでは通常、SELECT..INTO を使用して、テーブルに SELECT ステートメントの結果を設定します。 これは、SQL Server の SELECT..INTO ステートメントの例です。
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
この構文は、Azure Synapse Analytics および Parallel Data Warehouse ではサポートされていません。 この例では、以前の SELECT..INTO ステートメントを CTAS ステートメントとして書き直す方法を示します。 CTAS 構文に記述されている DISTRIBUTION オプションのいずれかを選択できます。 この例では、ROUND_ROBIN 分散方法を使用します。
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. CTAS を使用して MERGE ステートメントを簡略化する
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
MERGE ステートメントの少なくとも一部は、CTAS を使用して置き換えることができます。 INSERT と UPDATE を単一のステートメントにまとめることができます。 削除されたレコードは、2 番目のステートメントで閉じる必要があります。
UPSERT の例を次に示します。
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. 明示的にデータ型および出力の null 値の許容を示す
適用対象: Azure Synapse Analytics および Analytics Platform System (PDW)
SQL Server コードを Azure Synapse Analytics に移行したときに、次のようなコーディング パターンが発生する場合があります。
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
直感的に、このコードを CTAS に移行する必要があり、それが正しいと思うかもしれません。 しかし、これには問題が潜んでいます。
次のコードでは同じ結果が生成されません。
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
"結果" 列に、式のデータ型と NULL 値の許容値が引き継がれることに注目してください。 注意しないと、これで値が微妙に変化する可能性があります。
例として、以下を試してみてください。
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
結果の格納される値が異なります。 結果列に永続化された値が他の式で使用されているため、エラーがさらに重大になります。
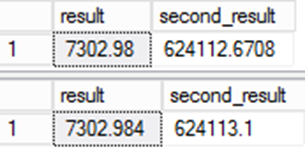
これは、データを移行する場合に重要になります。 2 番目のクエリのほうが正確ではありますが、問題があります。 ソース システムと比較して、データが異なり、このことが移行での整合性の問題につながります。 これは、"間違った" 答えが実際は正しいものである場合のまれなケースの 1 つです。
2 つの結果の間でこのような違いが見られる理由は、暗黙的な型キャストへの依存です。 1 つ目の例の場合、テーブルで列が定義されています。 行が挿入されたときに、暗黙的な型変換が発生します。 2 つ目の例では、列のデータ型が式で定義されているため、暗黙の型変換は実行されません。 2 つ目の例の列が null 許容の列として定義されている一方で、1 つ目の例ではそのように定義されていないことにも注意してください。 最初の例でテーブルが作成されたときに、列の NULL 値の許容は明示的に定義されました。 2 番目の例では、式に応じて決まるため、既定で NULL 定義となります。
これらの問題を解決するには、CTAS ステートメントの SELECT 部分で型変換と NULL 値の許容を明示的に設定する必要があります。 これらのプロパティは、CREATE TABLE 部分で設定することはできません。
コードの修正方法の例を次に示します。
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
この例では、次の点に注意してください。
- CAST または CONVERT を使用できたかもしれません。
- ISNULL は、COALESCE ではなく NULL 値の許容を強制するために使われています。
- ISNULL は最も外側の関数です。
- ISNULL の 2 つ目の部分は定数
0です。
Note
NULL 値の許容を正しく設定するには、COALESCE ではなく、ISNULL を使用することが重要です。 COALESCE は決定的関数ではないため、式の結果は常に NULL 許容になります。 ISNULL は異なります。 これは決定的です。 そのため、ISNULL 関数の 2 番目の部分が定数またはリテラルである場合、結果の値は NOT NULL になります。
このヒントは、計算の整合性を確保するために役立つだけではありません。 テーブルのパーティション切り替えにも重要になります。 以下のテーブルがファクトとして定義されているとします。
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
ただし、値フィールドは、ソース データの一部ではない、計算された式です。
パーティション分割されたデータセットを作成するには、次の例を検討してください。
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
クエリは適切に実行されます。 パーティション切り替えを実行しようとすると問題が発生します。 テーブルの定義が一致ません。 テーブルの定義を一致させるには、CTAS の変更が必要です。
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
したがって、型の一貫性と、CTAS で NULL 値の許容プロパティを維持することが適切なエンジニアリングのベスト プラクティスであることがわかります。 計算の整合性を維持するのに役立ち、また、確実にパーティションを切り替えることができます。
L. MAXDOP 1 で順序指定クラスター化列ストア インデックスを作成する
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
次の手順
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
適用対象:Microsoft Fabric の ![]() ウェアハウス
ウェアハウス
CREATE TABLE AS SELECT (CTAS) は、使用可能な最も重要な T-SQL 機能の 1 つです。 これは SELECT ステートメントの出力に基づいて新しいテーブルを作成する完全に並列化された操作です。 CTAS は、テーブルのコピーを作成する最も簡単で速い方法です。
たとえば、Microsoft Fabric のウェアハウスで次のように CTAS を使用します。
- ソース テーブルの列の一部を含むテーブルのコピーを作成します。
- 他のテーブルを結合するクエリの結果であるテーブルを作成します。
Microsoft Fabric のウェアハウスで CTAS を使用する方法の詳細については、「Transact-SQL を使用してウェアハウスにデータを取り込む」を参照してください。
Note
CTAS はテーブルの作成機能に加えられたものであるため、このトピックでは CREATE TABLE トピックの内容は繰り返しません。 代わりに、CTAS と CREATE TABLE のステートメントの違いについて説明します。 CREATE TABLE の詳細については、CREATE TABLE ステートメントを参照してください。
構文
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
引数
詳細については、「 Microsoft Fabric の CREATE TABLE の引数」を参照してください。
列のオプション
column_name [ ,...n ]
列名では、CREATE TABLE に示されている列のオプションは使用できません。 代わりに、新しいテーブルには 1 つ以上の列名のオプション リストを指定できます。 新しいテーブルの列では、指定した名前が使用されます。 列名を指定する場合、列リスト内の列の数は、SELECT の結果内の列の数と一致する必要があります。 列名を指定しない場合、新しいターゲット テーブルでは、SELECT ステートメントの結果の列名が使用されます。
データ型、照合順序、NULL 値の許容など、他の列オプションを指定することはできません。 これらの各属性は、SELECT ステートメントの結果から派生されます。 ただし、SELECT ステートメントを使用して、属性を変更することができます。
SELECT ステートメント
SELECT ステートメントは、CTAS と CREATE TABLE の基本的な違いです。
SELECT select_criteria
SELECT ステートメントの結果を新しいテーブルに追加します。 select_criteria は、新しいテーブルにコピーするデータを決定する SELECT ステートメントの本文です。 SELECT ステートメントについては、「SELECT (Transact-SQL)」を参照してください。
Note
Microsoft Fabric では、CTAS での変数の使用は許可されていません。
アクセス許可
CTAS には、select_criteria で参照されるすべてのオブジェクトに対する SELECT 権限が必要です。
テーブルを作成する権限については、CREATE TABLE の「権限」を参照してください。
解説
詳細については、CREATE TABLE の「全般的な解説」を参照してください。
制限事項と制約事項
CTAS では SET ROWCOUNT (Transact-SQL) の効果はありません。 同様の動作を実現するには、TOP (Transact-SQL) を使用します。
詳細については、CREATE TABLE の「制限事項と制約」を参照してください。
ロック動作
詳細については、CREATE TABLE の「ロック動作」を参照してください。
テーブルのコピー例
Microsoft Fabric のウェアハウスで CTAS を使用する方法の詳細については、「Transact-SQL を使用してウェアハウスにデータを取り込む」を参照してください。
A. CTAS を使用して列属性を変更する
この例では CTAS を使用して、DimCustomer2 テーブルのいくつかの列のデータ型と NULL 値の許容を変更します。
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. CTAS を使用して列が少ないテーブルを作成する
次の例では、myTable (c, ln) という名前のテーブルを作成します。 新しいテーブルには 2 つの列のみがあります。 列名には、SELECT ステートメントの列の別名を使用します。
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. SELECT..INTO の代わりに CTAS を使用する
SQL Server コードでは通常、SELECT..INTO を使用して、テーブルに SELECT ステートメントの結果を設定します。 これは、SQL Server の SELECT..INTO ステートメントの例です。
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
この例では、以前の SELECT..INTO ステートメントを CTAS ステートメントとして書き直す方法を示します。
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. CTAS を使用して MERGE ステートメントを簡略化する
MERGE ステートメントの少なくとも一部は、CTAS を使用して置き換えることができます。 INSERT と UPDATE を単一のステートメントにまとめることができます。 削除されたレコードは、2 番目のステートメントで閉じる必要があります。
UPSERT の例を次に示します。
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示