コンピューター ビジョンのための機械学習
フィルターを使用して画像に効果を適用する機能は、画像編集ソフトウェアで実行するような画像処理タスクに役立ちます。 しかし多くの場合、コンピュータ ビジョンの目的は、画像から意味や、少なくとも実用的な洞察を抽出することです。これには、大量の既存の画像に基づいて特徴を認識するようにトレーニングされた機械学習モデルの作成が必要です。
ヒント
このユニットでは、機械学習の基本的な原則に精通していること、およびニューラル ネットワークを使用したディープ ラーニングの概念的な知識があることを前提としています。 機械学習に初めて触れる場合は、Microsoft Learn の「機械学習の基礎」モジュールを完了することを検討してください。
畳み込みニューラル ネットワーク (CNN)
コンピューター ビジョンの最も一般的な機械学習モデル アーキテクチャの 1 つは、"畳み込みニューラル ネットワーク" (CNN) です。 CNN はフィルターを使用して画像から数値特徴マップを抽出し、特徴値をディープ ラーニング モデルに供給してラベル予測を生成します。 たとえば、"画像分類" シナリオで、ラベルが画像の主題 (つまり、これが何の画像であるか) を表します。 予測されるラベルが提示された画像の果物の種類になるように、さまざまな種類の果物 (リンゴ、バナナ、オレンジなど) の画像を使用して CNN モデルをトレーニングするとします。
CNN の "トレーニング" プロセス中、最初はランダムに生成された重み値を使用してフィルター カーネルが定義されます。 次に、トレーニング プロセスが進むにつれて、モデルの予測が既知のラベル値と照合して評価され、フィルターの重みが調整されて精度が向上します。 最終的に、トレーニングされた果物画像分類モデルは、さまざまな種類の果物を特定するのに役立つ特徴を最もよく抽出するフィルターの重みを使用します。
画像分類モデルの CNN のしくみを次の図に示します。
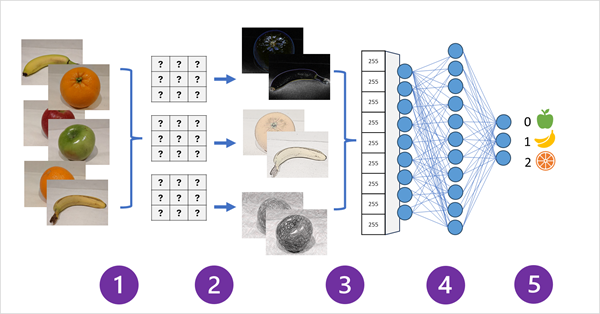
- モデルをトレーニングするために、既知のラベル (例: 0: リンゴ、1: バナナ、2: オレンジ) を持つ画像がネットワークに供給されます。
- 1 つ以上のフィルター レイヤーを使用して、ネットワーク経由で供給される各画像から特徴を抽出します。 フィルター カーネルは、ランダムに割り当てられた重みから開始し、"特徴マップ" と呼ばれる数値の配列を生成します。
- 特徴マップが、特徴値の 1 次元配列にフラット化されます。
- 特徴値が、完全に接続されたニューラル ネットワークに供給されます。
- ニューラル ネットワークの出力レイヤーが、softmax または同様の関数を使用して、可能性がある各クラスの確率値を含む結果 (例: [0.2, 0.5, 0.3]) を生成します。
トレーニング中に、出力の確率が実際のクラス ラベルと比較されます。たとえば、バナナ (クラス 1) の画像の値は [0.0, 1.0, 0.0] である必要があります。 予測と実際のクラス スコアの差を使用してモデルの "失敗" が計算され、失敗を減らすように、完全に接続されたニューラル ネットワークと特徴抽出レイヤーのフィルター カーネルの重みが変更されます。
トレーニング プロセスは、最適な重みのセットが学習されるまで、複数の "エポック" を繰り返します。 これで、重みが保存され、モデルを使用して、ラベルが不明な新しい画像のラベルを予測できます。
Note
CNN アーキテクチャには通常、特徴マップのサイズを小さくしたり、抽出された値を制限したり、特徴値を操作したりするために、複数の畳み込みフィルター レイヤーと追加レイヤーが含まれています。 これらのレイヤーは、この簡略化された例では省略されています。画像から数値特徴量を抽出するためにフィルターが使用され、次に画像ラベルを予測するためにニューラル ネットワークで使用されるという主要な概念に焦点を当てるためです。
トランスフォーマーとマルチモーダル モデル
CNN は、長年にわたってコンピューター ビジョン ソリューションの中核にありました。 これらは、前に説明したように画像分類の問題を解決するために一般的に使用されますが、より複雑なコンピューター ビジョン モデルの基礎でもあります。 たとえば、"物体検出" モデルは、CNN の特徴抽出レイヤーと画像内の "関心領域" の特定結果を組み合わせて、同じ画像内に複数のクラスのオブジェクトを見つけます。
トランスフォーマー
数十年にわたるコンピューター ビジョンのほとんどの進歩は、CNN ベースのモデルの改善によって推進されてきました。 しかし、別の AI 規範である "自然言語処理" (NLP) では、"トランスフォーマー" と呼ばれる別の種類のニューラル ネットワーク アーキテクチャが、言語の高度なモデルの開発を可能にしました。 トランスフォーマーは、膨大な量のデータを処理し、言語 "トークン" (個々の単語またはフレーズを表す) をベクトルに基づく "埋め込み" (数値の配列) にエンコードすることで機能します。 埋め込みとは、それぞれがトークンの何らかのセマンティック属性を表す一連のディメンションを表すものと考えることができます。 埋め込みは、同じコンテキストでよく使用されるトークンをまとめて、関連のない単語よりもディメンションが近くなるように作成されます。
簡単な例として、3 次元ベクトルとしてエンコードされ、3D 空間にプロットされたいくつかの単語を次の図に示します。
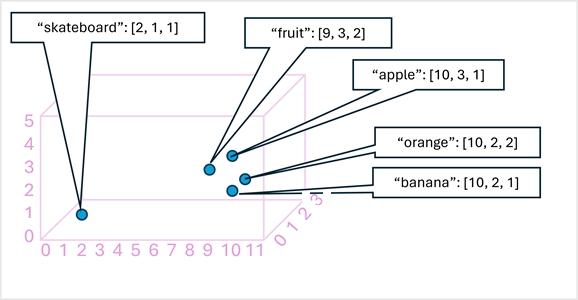
セマンティックが類似したトークンは、類似の位置にエンコードされ、テキスト分析、翻訳、言語生成などのタスク用の高度な NLP ソリューションを構築できるセマンティック言語モデルを作成します。
Note
視覚化が簡単なため、ディメンションを 3 つのみ使用しました。 実際には、トランスフォーマー ネットワークのエンコーダーは、より多くのディメンションを持つベクトルを作成し、線形代数計算に基づいてトークン間の複雑なセマンティック関係を定義します。 関係する計算は、トランスフォーマー モデルのアーキテクチャと同様に複雑です。 ここでの目標は、エンコードがエンティティ間のリレーションシップをカプセル化するモデルを作成するしくみを単に "概念的に" 理解していただくことです。
マルチモーダル モデル
言語モデルを構築する方法としてのトランスフォーマーの成功により、AI 研究者は、画像データに対して同じアプローチが有効かどうかを検討してきました。 その結果が、"マルチモーダル" モデルの開発です。ここでは、モデルは、固定 "ラベル" のない大量のキャプション付き画像を使用してトレーニングされます。 イメージ エンコーダーは、ピクセル値に基づいて画像から特徴を抽出し、それらを言語エンコーダーによって作成されたテキスト埋め込みと組み合わせます。 モデル全体が、次に示すように、自然言語トークンの埋め込みと画像の特徴の間の関係をカプセル化します。
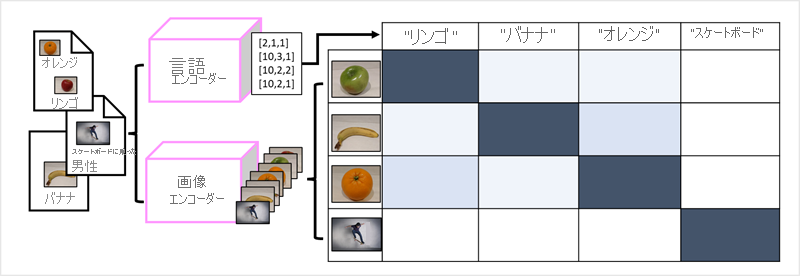
Microsoft の Florence モデルは、まさにそのようなモデルです。 これは、インターネットの大量のキャプション付き画像でトレーニングされるもので、言語エンコーダーとイメージ エンコーダーの両方が含まれます。 Florence は "基盤" モデルの一例です。 つまり、事前トレーニング済みの一般的なモデルであり、それに基づいて専門家のタスク用に複数の "アダプティブ" モデルを構築できます。 たとえば、次を実行するアダプティブ モデルの基盤モデルとして、Florence を使用できます。
- "画像分類":画像が属するカテゴリの特定。
- "物体検出":画像の個々のオブジェクトの検索。
- "キャプション付け":画像の適切な説明の生成。
- "タグ付け":画像に関連するテキスト タグの一覧の編集。
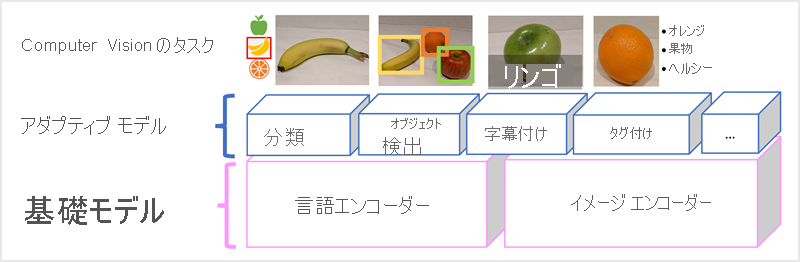
Florence などのマルチモーダル モデルは、コンピュータ ビジョンと AI 全般の最先端にあり、AI が可能にするソリューションの種類の前進を促進することが期待されています。