Text Analytics について理解する
Azure AI Language サービスのテキスト分析機能を調べる前に、テキスト分析やその他の自然言語処理 (NLP) タスクを実行するために使用される一般的な原則と一般的な手法をいくつか調べてみましょう。
コンピューターでテキストを分析するために使用されるいくつかの初期段階の手法の中に、何らかの種類のセマンティック上の意味を推測するテキスト本文 ("コーパス") の統計分析があります。 簡単に言えば、与えられたドキュメントの中で最も一般的に使用されている単語を特定できれば、多くの場合、ドキュメントが何に関するものかを把握できます。
トークン化
コーパスを分析する最初の手順は、それを "トークン" に分割することです。 単純化のためには、トレーニング テキスト内の個々の単語それぞれがトークンだと考えて構いませんが、トークンは実際には、単語の一部、または単語と句読点の組み合わせとして生成できます。
たとえば、次の有名な米国大統領のスピーチからのフレーズを考えてみましょう: "we choose to go to the moon"。 このフレーズは、以下の数字識別子付きトークンに分解できます。
- we
- choose
- to
- GO
- the
- moon
"to" (トークン番号 3) がコーパス内で 2 回使用されていることに注意してください。 "we choose to go to the moon" というフレーズは、トークン [1,2,3,4,3,5,6] で表すことができます。
Note
ここでは、トークンがテキスト内の個別の単語として決定される単純な例を使用しました。 しかし、解決しようとしている NLP 問題の具体的な種類によっては、以下の概念がトークン化に適用できるかもしれないのでこれを検討してください。
- テキスト正規化:トークンを生成する前に、句読点を削除しすべての単語を小文字に変更することで、テキストを "正規化" することを選択できます。 純粋に単語の頻度に依存する分析の場合、このアプローチによって全体的なパフォーマンスが向上します。 しかし、何らかのセマンティック上の意味が失われる場合があります。たとえば、"Mr Banks has worked in many banks." という文を考えてみましょう。 分析では、人物である Mr Banks と彼が働いていた banks を区別したい場合があります。 また、ピリオドを含めることでその単語が文の末尾にあるという情報が提供されるので、"banks." を "banks" とは別のトークンと見なしたい場合もあります
- ストップ ワードの削除。 ストップ ワード は、分析から除外する必要がある単語です。 たとえば、"the"、"a"、または "it" は、テキストを人が読みやすいものにしますが、セマンティック上の意味はほとんど持ちません。 これらの単語を除外することで、テキスト分析ソリューションは重要な単語をより上手く識別できる場合があります。
- n-gram は、"I have" や "he walked" などの複数用語のフレーズです。 1 つの単語フレーズは unigram、2 単語の語句は bi-gram、3 単語の語句は tri-gram などです。 単語をグループとして考慮すると、機械学習モデルはテキストをより適切に理解できます。
- ステミングは、"power"、"powered"、"powerful" などの同じ語幹を持つ単語を同じトークンであると解釈するために、単語をカウントする前に、統合のためのアルゴリズムを適用する手法です。
頻度分析
単語をトークン化した後、何らかの分析を実行して、各トークンの出現回数をカウントできます。 ("a"、"the" などの "ストップ ワード" 以外で) 最も一般的に使用されている単語は、多くの場合、テキスト コーパスの主題に関する手掛かりを与えます。 たとえば、先ほど検討した "go to the moon" スピーチの全体テキストの中で最も一般的な単語には、"new"、"go"、"space"、"moon" が含まれます。 テキストをバイグラム (単語ペア) としてトークン化したとすると、スピーチの中で最も一般的なバイグラムは "the moon" です。 この情報から、テキストが主に宇宙旅行と月へ行くことに関するものであるとを容易に推測できます。
ヒント
各トークンの出現回数を単にカウントする単純な頻度分析は、1 つのドキュメントを分析するには効果的な方法である可能性がありますが、同じコーパス内の複数のドキュメントを区別する必要がある場合は、各ドキュメントで最も関連性の高いトークンを決定する方法が必要です。 "単語頻度 - 逆文書頻度" (TF-IDF) は、1 つのドキュメントに単語または用語が出現する頻度が、複数ドキュメントのコレクション全体でのより一般的な頻度と比較してどの程度であるかに基づいてスコアを計算する一般的な手法です。 この手法を使用すると、特定のドキュメント内での出現頻度が高く、他のドキュメントの広い範囲での出現頻度が比較的低い単語は関連度が高いと見なされます。
テキスト分類のための機械学習
別の有用なテキスト分析手法は、"ロジスティック回帰" などの分類アルゴリズムを使用して、既知の分類セットに基づいてテキストを分類する機械学習モデルをトレーニングすることです。 この手法の一般的な用途は、"感情分析" または "オピニオン マイニング" を実行するために、テキストを "肯定的" または "否定的" として分類するモデルのトレーニングです。
たとえば、既に 0 ("否定的") または 1 ("肯定的") のラベルが付いている以下のレストラン レビューを考えてみましょう。
- The food and service were both great:1
- A really terrible experience:0
- Mmm! tasty food and a fun vibe: 1
- Slow service and substandard food:0
十分なラベルが付いたレビューを使用すると、トークン化されたテキストを "特徴量"、センチメント (0 または 1) を "ラベル" として使用して分類モデルをトレーニングできます。 モデルは、トークンとセンチメントの間の関係をカプセル化します。たとえば、"great"、"tasty"、"fun" などの単語のトークンを含むレビューは、1 ("肯定的") というセンチメントを返す可能性が高くなりますが、"terrible"、"slow"、"substandard" などの単語を含むレビューは、0 ("否定的") というセンチメントを返す可能性が高くなります。
セマンティック言語モデル
NLP の最先端技術が進歩するにつれ、トークン間のセマンティック関係をカプセル化するモデルをトレーニングする能力が高まり、強力な言語モデル出現するようになりました。 これらのモデルの中心にあるのは、ベクトル (複数の値を持つ数値配列) としての言語トークンのエンコードであり、これは "埋め込み" として知られています。
トークン埋め込みベクトルの要素を多次元空間の "座標" と考えて、各トークンが特定の "場所" を占めるようにすると便利です。トークンが特定の次元に沿って相互に近いほど、意味上の関係性が高くなります。 つまり、関連する単語はより近くにグループ化されます。 簡単な例として、トークンの埋め込みが、次のような 3 つの要素を持つベクトルで構成されているとします。
- 4 ("dog"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
これらのベクトルに基づいてトークンの場所を 3 次元空間に次のようにプロットできます。
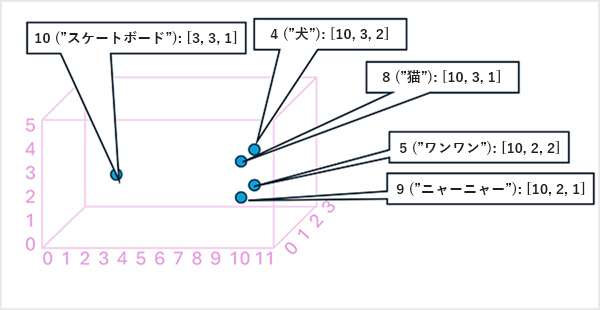
埋め込みスペース内のトークンの場所には、トークンが相互にどれだけ密接に関連しているかに関する情報が含まれます。 たとえば、"dog" のトークンは "cat" に近く、"bark" にも近い場所にあります。"cat" と "bark" のトークンは"meow" に近い場所にあります。"skateboard" のトークンは、他のトークンから離れています。
業界で使用する言語モデルは、これらの原則に基づいていますが、より複雑です。 たとえば、使用されるベクトルは一般的にもっと高い次元を持っています。 また、特定のトークン セットに対して適切な埋め込みを計算する方法も複数あります。 メソッドが異なると、自然言語処理モデルとは異なる予測が生成されます。
最も現代的な自然言語処理ソリューションの一般化された全体像を次の図に示します。 生テキストの大規模なコーパスはトークン化され、言語モデルをトレーニングするために使用され、このモデルはさまざまな種類の自然言語処理タスクをサポートできます。
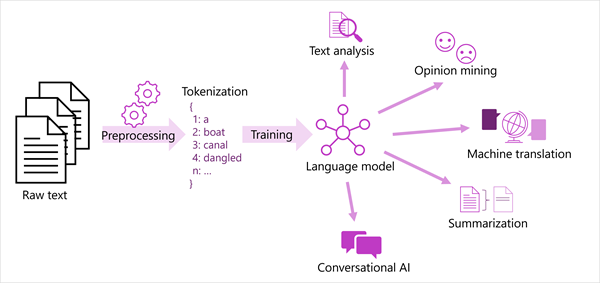
言語モデルによってサポートされる一般的な NLP タスクには以下が含まれます。
- 鍵となる用語の抽出やテキスト内の名前付きエンティティの識別などのテキスト分析。
- テキストを "肯定的" または "否定的" に分類する感情分析とオピニオン マイニング。
- 機械翻訳では、テキストがある言語から別の言語に自動的に翻訳されます。
- 要約では、大きなテキスト本文の主要点が要約されます。
- "ボット" や "デジタル アシスタント" などの対話型 AI ソリューションでは、言語モデルが自然言語入力を解釈し、適切な応答を返すことができます。
これらとその他の機能が Azure AI Language サービスのモデルによってサポートされていて、これについては次で確認していきます。