ケース スタディ:Hadoop 分散ファイル システム (HDFS)
MapReduce プログラミング モデルを使用すると、map および reduce という 2 つの関数で計算ジョブを構成できます。 入力はキーと値のペアとして MapReduce に供給され、そこで map 関数を通じて処理され、reduce 関数に供給されます。 その後、リデュース演算によって結果が生成されます。これもキーと値のペアの形式です。 MapReduce は、大規模な計算クラスター上で、マップおよびリデュース演算の多くのインスタンスを並列で実行するように設計されています。 MapReduce プログラミング モデルの詳細については、後のモジュールで説明します。
MapReduce プログラミング モデルでは、1 つの名前空間 (分散ファイル システム (DFS) が入る場所) を使用して、クラスターのすべてのノードで使用可能な分散ストレージ システムを利用できることを前提としています。 DFS は、MapReduce クラスターのノードと併置されています。 DFS は MapReduce と連携して動作し、MapReduce クラスター全体に 1 つの名前空間を保持するように設計されています。
Apache Hadoop2 と呼ばれる MapReduce のオープンソース バージョンは、ビッグデータのサークルでとても人気があります。 HDFS はオープンソースの DFS です。 HDFS は、主に MapReduce プログラミング モデルのニーズに対応する、スケーラブルでフォールト トレラントな分散ファイル システムとして設計されています。 ビデオ 4.12 では HDFS が紹介されています。
HDFS は POSIX に準拠しておらず、それ自体がマウント可能なファイル システムではないことに注意してください。 HDFS には通常、HDFS クライアントを介して、または Hadoop ライブラリにあるアプリケーション プログラミング インターフェイス (API) 呼び出しを使用してアクセスします。 ただし、(HDFS) 用の File system in User SpacE (FUSE) ドライバーを開発することで、UNIX 系オペレーティング システムに仮想デバイスとしてマウントすることができます。
HDFS のアーキテクチャ
前述のように、HDFS は、ノードのクラスター上で実行するように設計された DFS であり、次のような目的で設計されています。
- 単一で共通のクラスター全体の名前空間
- 大きなファイル (テラバイトやペタバイトなど) を格納する機能
- MapReduce プログラミング モデルのサポート
- Write-Once, Read-Many データ アクセス パターンのストリーミング データ アクセス
- 汎用ハードウェアを使用した高可用性
HDFS クラスターを次の図に示します。

図 1:HDFS のアーキテクチャ
HDFS は、マスター/従属設計に従います。 マスター ノードは NameNode と呼ばれます。 NameNode では、クラスター全体のメタデータ管理が処理され、HDFS に格納されているすべてのファイルに対して 1 つの名前空間が保持されます。 従属ノードは、DataNode として知られています。 DataNode では、各ノード内のローカル ファイル システムに実際のデータ ブロックが格納されます。
HDFS 内のファイルはブロック (チャンクとも呼ばれます) に分割され、既定のサイズはそれぞれ 128 MB です。 これに対し、ローカル ファイル システムでは通常、ブロック サイズが約 4 KB です。 HDFS は、MapReduce ジョブで効率的に処理できる方法で非常に大きなファイルを格納するように設計されているため、大きなブロック サイズが使用されます。
MapReduce の単一のマップ タスクは、既定で 1 つの HDFS ブロック上で独立して動作するように構成されているため、複数のマップ タスクで複数の HDFS ブロックを並列処理できます。 ブロック サイズが小さすぎる場合、多数のマップ タスクをクラスターのノード全体に分散する必要があり、そのためのオーバーヘッドがパフォーマンスに悪影響を与える可能性があります。 一方、ブロックが大きすぎる場合は、ファイルを並列処理できるマップ タスクの数が削減されるため、並列処理に影響します。 HDFS を使用すると、ブロック サイズをファイル単位で指定できるため、ユーザーはブロック サイズを調整して、必要な並列処理のレベルを実現できます。 MapReduce と HDFS の相互作用については、後のモジュールで詳しく説明します。
また、HDFS は個々のノードの障害を許容するように設計されているため、データ ブロックは複数のノードにレプリケートされ、データの冗長性が提供されます。 このプロセスの詳細については、以降のセクションで説明します。
HDFS でのクラスター トポロジ
Hadoop クラスターは、前のモジュールで説明したように、通常はファットツリー トポロジを使用して接続された複数のサーバー ラックで構成されるデータ センターにデプロイされます。 このため、HDFS はクラスター トポロジを認識するように設計されており、パフォーマンスとフォールト トレランスに影響を与えるブロック配置の決定を支援します。 一般的な Hadoop クラスターには、ラックあたり約 30 から 40 のサーバーがあり、ラック専用のギガビット スイッチとコア スイッチまたはルーターへのアップリンクがあります。これには、次の図に示すように、データ センター内の多くのラック間で共有される帯域幅があります。
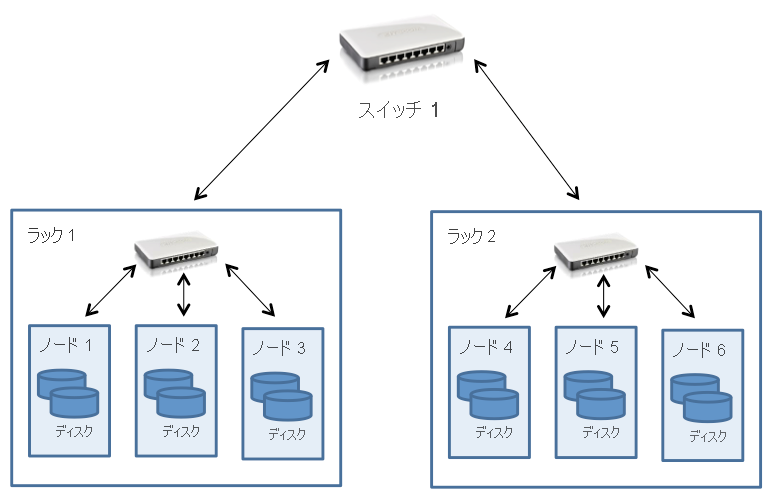
図 2:HDFS クラスター トポロジ
注目すべきポイントとして、Hadoop では、ラックのノード内の総帯域幅が、異なるラック上のノード全体の総帯域幅を上回っていることが想定されます。 この想定は、データ アクセスとレプリカの配置に関して Hadoop の設計に組み込むことを前提としています (以下のセクションで説明します)。
HDFS がクラスターにデプロイされている場合、システム管理者は、各ノードをクラスター内の特定のラックにマップするトポロジ記述を使用して構成できます。 ネットワーク距離はホップ単位で測定されます。1 つのホップがトポロジ内の 1 つのリンクに対応します。 Hadoop はツリー形式のトポロジを前提としており、2 つのノード間の距離は、最も近い共通の先祖までの距離の合計です。
図 2 の例では、ノード 1 とそれ自体の間の距離はゼロ ホップです (2 つのプロセスが同じノード上で通信している場合)。 ノード 1 とノード 2 の間の距離は 2 ホップですが、ノード 3 とノード 4 の間の距離は 4 ホップです。
次のビデオでは、HDFS でのファイルの読み取り操作と書き込み操作について説明します。

図 3:HDFS でのファイルの読み取り
図 3 は、HDFS でのファイル読み取りのプロセスを示しています。 HDFS クライアント (ファイルにアクセスする必要があるエンティティ) は、読み取り用にファイルが開かれたときに、最初に NameNode に接続します。 次に、NameNode によってファイルのブロックの場所の一覧がクライアントに提供されます。 また、Hadoop では、ブロックがノード間でレプリケートされることを前提としているため、特定のブロックの場所を指定するときに、NameNode では実際にクライアントに最も近いブロックが検索されます。 ローカリティは、クライアントと同じノード内のブロック、クライアントと同じラック内のブロック、クライアントのラック外のブロックの順 (降順のローカリティ) で決定されます。
ブロックの場所が決定されると、クライアントによって、各 DataNode への直接接続が開かれ、DataNode からクライアント プロセスにデータがストリーミングされます。これは HDFS クライアントによってデータ ブロックに対する読み取り操作が呼び出されたときに行われます。 そのため、クライアントが計算を開始する前にブロック全体を転送する必要がなく、それにより計算と通信のインターリーブが行われます。 クライアントは最初のブロックの読み取りを完了すると、すべてのブロックの読み取りが完了するまで残りのブロックでこのプロセスを繰り返し、その後ファイルが閉じられます。
データを取得するためにクライアントが DataNode に直接アクセスすることに注意してください。 この接続により、HDFS はデータを同時に並列して読み取るために、多数の同時実行クライアントにスケーリングできます。
ファイルの書き込みは、HDFS でのファイルの読み取りとは異なります (図 4)。 HDFS にデータを書き込む必要があるクライアントでは、まず NameNode に接続してから、ファイルの作成が通知されます。 NameNode により、ファイルが既に存在するかどうかがチェックされ、クライアントにファイルを作成するアクセス許可があるかどうかが確認されます。 チェックに合格すると、NameNode によって新しいファイルのレコードが作成されます。

図 4: HDFS でのファイル書き込み
クライアントは、内部データ キューへのファイルの書き込みに進み、クラスターの DataNode 上のブロックの場所を NameNode に要求します。 その後、内部キュー上のブロックは、パイプライン形式で個々の DataNode に転送されます。 ブロックは最初の DataNode に書き込まれます。その後、ブロックのレプリカを書き込むために、ブロックを他の DataNode に転送します。 そのため、ブロックはファイルの書き込み時にレプリケートされます。 HDFS は、そのファイルのすべてのレプリカが DataNode によって書き込まれるまで、クライアントへの書き込みの確認 (図 4.28 の手順 5) を行わないことに注意する必要があります。
Hadoop では、レプリカの配置時にラックのローカリティの概念も使用されます。 既定では、データ ブロックは HDFS 内で 3 回レプリケートされます。 HDFS では、ブロックを書き込むクライアントと同じノードに最初のレプリカの配置が試行されます。 クライアント プロセスが HDFS クラスターで実行されていない場合、ノードはランダムに選択されます。 2 つ目のレプリカは、1 つ目 (ラック外) とは別のラックにあるノードに書き込まれます。 次に、ブロックの 3 つ目のレプリカが、2 つ目と同じラック上の別のランダムなノードに書き込まれます。 さらにレプリカはクラスター内のランダムなノードに書き込まれますが、システムでは同じラックに配置するレプリカが多くなりすぎないようにされます。 図 5 は、HDFS 内の 3 回レプリケートされるブロックのレプリカ配置を示しています。 HDFS のレプリカ配置の背後にある考え方は、ノードとラックの障害に耐えられるようにすることです。 たとえば、電源やネットワークの問題によってラック全体がオフラインになった場合でも、要求されたブロックを別のラックに配置できます。
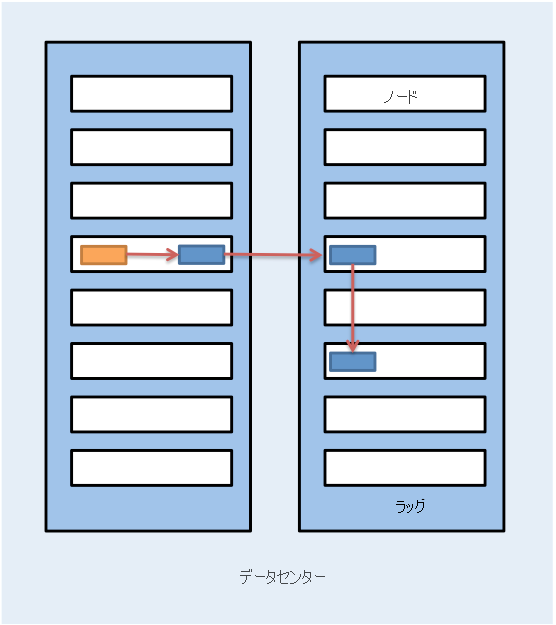
図 5: HDFS 内の 3 回レプリケートされるブロックのレプリカ配置
同期:セマンティクス
HDFS のセマンティクスが少し変更されました。 以前のバージョンの HDFS は、厳格な変更不可のセマンティクスに従っていました。 以前のバージョンの HDFS で作成されたファイルを書き込み用に再び開くことはできません。 ファイルを削除することはできます。 ただし、現在のバージョンの HDFS では、制限された方法での追加がサポートされます。 HDFS に書き込まれた既存のバイナリ データはインプレースで変更できないという点で、これは依然としてかなり制限されています。
HDFS でのこの設計の選択は、最も一般的な MapReduce ワークロードの一部が Write Once, Read Many データアクセス パターンに従うために行われました。 MapReduce は、事前に定義されたステージを持つ制限付き計算モデルであり、MapReduce 内のレジューサーの出力では、独立したファイルが HDFS に出力として書き込まれます。 HDFS は、一度に複数のクライアントの同時高速読み取りアクセスに焦点を当てます。
整合性モデル
HDFS は、厳密に一貫性のあるファイル システムです。 各データ ブロックは複数のノードにレプリケートされますが、書き込みが成功と宣言されるのは、すべてのレプリカが正常に作成された後になります。 そのため、ファイルが書き込まれるとすぐにすべてのクライアントにファイルが参照され、すべてのクライアントでファイルの表示が同じになります。 HDFS の変更不可のセマンティクスにより、ファイルの有効期間中に 1 回だけ書き込むためにファイルを開くことができるため、これは比較的簡単に実装できます。
HDFS でのフォールト トレランス
HDFS のプライマリ フォールトトレランス メカニズムはレプリケーションです。 前に指摘したように、既定では、HDFS に書き込まれるすべてのブロックは 3 回レプリケートされますが、必要に応じてユーザーがこれをファイルごとに変更することもできます。
NameNode では、ハートビート メカニズムを通じて DataNode が追跡されます。 各 DataNode によって、定期的なハートビート メッセージが (数秒ごとに) NameNode に送信されます。 DataNode が停止している場合は、NameNode へのハートビートが停止します。 NameNode は、欠落したハートビート メッセージの数が特定のしきい値に達すると、DataNode が停止したことを検出します。 次に、NameNode によって DataNode が停止状態としてマークされ、その DataNode に I/O 要求が転送されなくなります。 その DataNode に格納されているブロックには、他の DataNode 上の追加のレプリカが必要です。 さらに、NameNode によって、レプリケート不足のブロックを検出するためにファイル システムに対して状態チェックが実行され、クラスターの再調整プロセスが実行されて、レプリカ数が必要な数より少ないブロックのレプリケーションが開始されます。
NameNode の障害によりファイル システム全体がダウンするため、NameNode は HDFS における単一障害点 (SPOF) になります。 内部的には、NameNode により、ファイル システムの状態を格納するディスク上の 2 つのデータ構造 (イメージ ファイルと編集ログ) が保持されます。 イメージ ファイルは、ある時点でのファイル システム メタデータのチェックポイントであり、編集ログは、イメージ ファイルが最後に作成されてからのファイル システム メタデータのすべてのトランザクションのログです。 ファイル システム メタデータに対するすべての受信した変更が編集ログに書き込まれます。 定期的に、編集ログとイメージ ファイルをマージして新しいイメージ ファイル スナップショットが作成され、編集ログが消去されます。ただし、NameNode 障害が発生した場合、メタデータは使用できなくなります。また、ファイルのメタデータが失われるため、NameNode 上のディスク障害は致命的です。
HDFS では、NameNode 上のメタデータをバックアップするために、セカンダリ NameNode を作成できます。これにより、NameNode からイメージ ファイルが定期的にコピーされます。 これらのコピーは、NameNode 上のデータ損失が発生した場合にファイル システムを復旧するのに役立ちますが、NameNode の編集ログに加えられた最後のいくつかの変更は失われます。 最新バージョンの Hadoop での継続的な作業では、NameNode に障害が発生したときに自動的に引き継ぐ、真に十分すぎるセカンダリ NameNode 作成することを目的としています。
実際の HDFS
HDFS は主にマップおよびリデュース演算に DFS を提供することによって Hadoop MapReduce ジョブをサポートするように設計されていましたが、HDFS ではビッグデータ ツールを使用した無数の用途が見つかりました。
HDFS は、Pig、Hive、HBase、Giraph など、Hadoop フレームワークの上に構築されるいくつかの Apache プロジェクト内で使用されます。 HDFS のサポートは、GraphLab などの他のプロジェクトにも含まれています。
HDFS の主な利点は次のとおりです。
- MapReduce ワークロードの高帯域幅: 大規模な Hadoop クラスター (数千台のマシン) が HDFS を使用して最大 1 テラバイト/秒を継続的に書き込むことが知られています。
- 高い信頼性:フォールト トレランスは、HDFS の主要な設計目標です。 HDFS レプリケーションでは、特にディスクとサーバーの障害の可能性が大幅に増加する大規模なクラスターで、高い信頼性と可用性が提供されます。
- バイトあたりのコストが低い:SAN などの専用の共有ディスク ソリューションと比較した場合、HDFS ではストレージがコンピューティング サーバーと併置されるので、ギガバイトあたりのコストが低くなります。 SAN では、ハードウェアの障害を管理するために、ディスク アレイ エンクロージャや高品質のエンタープライズ ディスクなどのマネージド インフラストラクチャに対して追加のコストを支払う必要があります。 HDFS は、汎用的なハードウェアで実行するように設計されており、障害を許容するために冗長性がソフトウェアで管理されます。
- スケーラビリティ:HDFS では、実行中のクラスターに DataNode を追加でき、クラスター ノードの追加時にデータ ブロックを手動で再調整するツールが提供されます。これは、ファイル システムをシャットダウンすることなく実行できます。
HDFS の主な短所は次のとおりです。
- 小さいファイルの非効率性:HDFS は、大きなブロック サイズ (64 MB 以上) で使用するように設計されています。 これは、大きなファイル (数百メガバイト、ギガバイト、またはテラバイト) を取得してチャンクに分割し、それを MapReduce ジョブに供給して並列処理できるようにすることを目的としています。 HDFS は、実際のファイル サイズが小さい場合 (キロバイトの範囲) には非効率的です。 多数の小さなファイルがあると、ファイル システム内のすべてのファイルのメタデータを保持する必要がある NameNode に追加の負荷がかかります。 通常、HDFS ユーザーは、シーケンス ファイルなどの手法を使用して、多数の小さなファイルを大きなファイルに結合します。
- POSIX のコンプライアンス違反:HDFS は、POSIX 準拠のマウント可能なファイル システムとしては設計されていません。アプリケーションは、ゼロから作成するか、HDFS クライアントを使用するように変更する必要があります。 FUSE ドライバーを使用して HDFS をマウントできるようにする回避策は存在しますが、ファイル システムのセマンティクスにより、ファイルが閉じられるとファイルへの書き込みは許可されません。
- Write-Once モデル:Write-Once モデルは、同じファイルへの同時書き込みアクセスを必要とするアプリケーションにとって潜在的な欠点です。 ただし、最新バージョンの HDFS では、ファイルの追加がサポートされるようになりました。
つまり、HDFS は、MapReduce モデルに準拠しているか、HDFS を使用するように特別に作成された、分散型アプリケーションのストレージ バックエンドとして適切な選択肢です。 HDFS は、多数の小さなファイルよりも、少数の大きなファイルで効率的に使用できます。
関連項目
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003 年)。 Google ファイル システム (第 19 回) オペレーティング システムの原則に関する ACM シンポジウム
- White, Tom (2012 年)。 「Hadoop: 決定版ガイド」 O'Reilly Media, Yahoo Press