ケース スタディ:CEPH ファイル システム
Ceph は、ディスクが接続されている大規模クラスターにデプロイできるストレージ システムです。 次のビデオは、Ceph の背景にある基本的な概念について説明しています。
Ceph2 の設計目標には、以下が含まれます。
- 幅広いアプリケーションをサポートするための柔軟性を備えた汎用記憶域クラスター。
- 数十万ものノードと数ペタバイトのストレージにシームレスにスケーリングできるアーキテクチャ。
- 自己管理と堅牢性を備えた、単一障害点がない信頼性の高いシステム。
- システムは、すぐに利用できる汎用的なハードウェア上で実行される必要があります。 Ceph は、次の図に示すように、3 つの異なる抽象化を通じてアクセスできるように設計されています。
Ceph 記憶域クラスターは分散オブジェクト ストアです。 記憶域クラスターの上に階層化されているのは、別のクライアント向けストレージ サービスです。 Ceph オブジェクト ゲートウェイ サービスを使用すると、Amazon の S3 および Openstack の Swift プロトコルと現在互換性がある REST ベースの HTTP インターフェイスを使用して、クライアントが Ceph 記憶域クラスターにアクセスできます。 Ceph ブロック デバイス サービスを使用すると、クライアントはブロック デバイスとして記憶域クラスターにアクセスできます。ブロック デバイスは、ローカル ファイル システムでフォーマットし、オペレーティング システムにマウントするか、Xen、KVM、VMWare、または QEMU 内の仮想マシンを操作するために仮想ディスクとして使用できます。 最後に、Ceph ファイル システム (Ceph FS) では、記憶域クラスター全体でのファイルとディレクトリの抽象化が POSIX 準拠のファイル システムとして提供されます。

図 6: Ceph エコシステム
さらに詳しく見て、Ceph のアーキテクチャを次に示します。

図 7: Ceph アーキテクチャ
Ceph の中核となるのは、RADOS と呼ばれる分散オブジェクト ストレージ システムです。 クライアントは、librados と呼ばれる低レベルの API を使用して RADOS を直接操作できます。この API はソケットベースであり、複数のプログラミング言語をサポートしています。 また、クライアントは、3 つの独立した抽象化を RADOS に提供する 3 つの上位レベルの API を操作できます。
RADOS Gateway または radosgw を使用すると、クライアントは REST ベースのゲートウェイを介して HTTP 経由で RADOS にアクセスできます。 これは Amazon S3 オブジェクト サービスをエミュレートし、Amazon S3 API または Openstack SWIFT API を使用するアプリケーションと互換性があります。
RADOS Block Device または RBD では、SAN と同様に、汎用分散ブロック デバイスとして RADOS オブジェクト ストアが公開されます。 RBD を使用すると、ブロック デバイスを RADOS から分割し、カーネル ドライバーを使用して Linux システムにマウントすることができます。 また、RBD は、Xen、VMWare、KVM、QEMU などの普及している仮想化システムの仮想ディスク イメージとして使用することもできます。
Ceph FS は、POSIX 準拠の分散ファイル システムであり、Linux クライアントのファイル システム内に直接マウントできる RADOS 上に階層化されています。 Ceph FS については、このページで後ほど詳しく説明します。
Ceph 記憶域クラスター アーキテクチャ (RADOS)
Ceph の中核となるのは、信頼性が高く自律的な分散オブジェクト ストア (RADOS) です。 RADOS では、データはコンピューターのクラスターに分散されたオブジェクトとして格納されます。 クライアントは、オブジェクトを格納および取得することによって、RADOS クラスターと対話します。 オブジェクトは、オブジェクト名 (オブジェクトを識別するために使用されるキー) と、オブジェクトのバイナリ コンテンツ (特定のオブジェクト キーに関連付けられた値) で構成されます。 RADOS の役割は、スケーラブルで信頼性の高いフォールト トレラントな方法で、オブジェクトを分散方式でクラスター全体に格納することです。
オブジェクト ストレージ デーモン (OSD) およびモニター ノードという 2 種類のノードがあります (図 8)。 OSD ではオブジェクトが格納され、オブジェクトに対する要求に応答します。 OSD では、各ノード上のローカル ファイル システムを使用してこれらのオブジェクトがノードに格納され、パフォーマンスを向上させるためにバッファー キャッシュが保持されます。 モニター ノードでは、クラスターの状態が監視されて、クラスターに出入りする OSD が追跡されます。
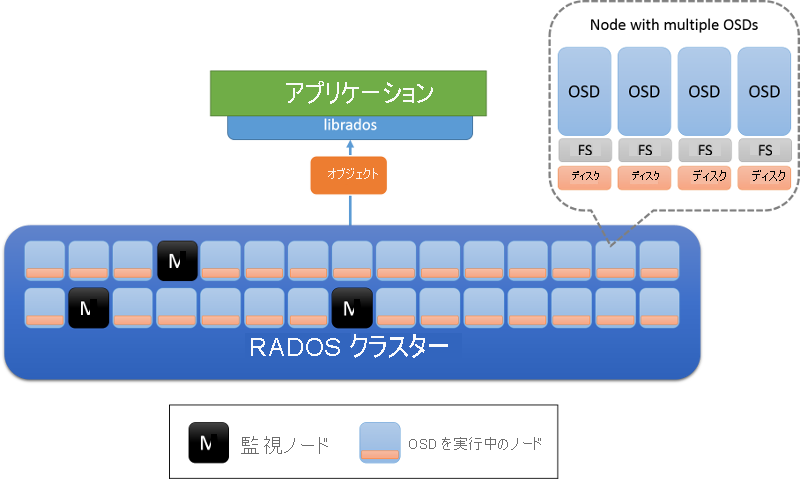
図 8: RADOS アーキテクチャ。 OSD はノード上のデータを担当します (通常は、物理ディスクごとに 1 つの OSD がデプロイされます)。 M でマークされたノードがモニター ノードです。
RADOS 内のクラスターの状態とモニター
RADOS クラスターの状態は、クラスター内のすべてのノードによって共有されるクラスター マップと呼ばれるオブジェクトにカプセル化されます。 クラスター マップには、任意の時点でのクラスターの状態に関する情報が含まれています。これには、現在存在している OSD の数、データが OSD 間で分散される方法の簡易表現 (次のセクションで詳しく説明します)、およびこのクラスター マップが構築された時刻を示す論理タイムスタンプが含まれます。 クラスター マップの更新は、モニター ノードによって、ピアツーピアの増分方式で実行されます。 つまり、クラスター マップ内の 1 つのタイムスタンプから別のタイムスタンプまでの変更だけがクラスター内のノード間でやり取りされるため、ノード間で転送されるデータ量は小さく維持されます。
RADOS 内のモニターでは、クラスター マップのマスター コピーを格納し、OSD の状態が変化した場合に備えて定期的な更新を送信することによって、記憶域システムの管理がまとめて行われます。 モニターは、paxos アルゴリズムに基づいて編成されており、モニターの大部分がクラスター マップの読み取りや更新を行う必要があります。 モニターによって、マップの更新がシリアル化され、一貫していることが確認されます。 RADOS クラスターは少数のモニター (> 3) を持つように設計されています。これは通常、個々のモニターが合意する必要があるときに同点となることがないように奇数になります。
RADOS でのデータの配置
分散オブジェクト ストレージを正常に動作させるには、クライアントがオブジェクトと対話するために、適切な OSD に接続できる必要があります。 まず、クライアントがモニターに接続して、指定された記憶域クラスターのクラスター マップを取得します。 クラスター マップに含まれている情報を使用して、クラスター内の特定のオブジェクトを担当する正確な OSD を特定できます。
最初の手順では、特定のオブジェクトの配置グループを決定します (図 9)。 配置グループは、オブジェクトが存在するバケットと考えることができます。 これを行うには、ハッシュ関数を使用します (使用する最新のハッシュ関数は、常にクラスター マップから取得されます)。 特定のオブジェクトの配置グループを決定したら、クライアントではその配置グループを担当する OSD を検索する必要があります。

図 9: CRUSH アルゴリズムを使用してオブジェクトを配置グループに配置し、最終的に OSD に配置します。
配置グループを OSD に割り当てるために使用されるアルゴリズムは、Controlled Replication Under Scalable Hashing (CRUSH)1 アルゴリズムと呼ばれています (図 9)。 CRUSH では、擬似ランダムだが決定的な方法で、クラスター全体に配置グループが割り当てられます。 CRUSH では、OSD がクラスターを出入りするときに、ほとんどの配置グループが現在の場所に残り、バランスのとれた分散を維持するために少量のデータだけがシフトされるという点で、CRUSH はハッシュ関数よりも安定しています。 一方、単純なハッシュ関数では、バケットが追加または削除されるときに、ほとんどのキーを再配布する必要があります。 CRUSH アルゴリズムの全体的な説明は、ここでの説明の範囲を超えています。 関心のある読者は、「CRUSH: レプリケートされたデータの管理されたスケーラブルな分散配置」を参照してください。
オブジェクト名が配置グループにハッシュされると、CRUSH によって、配置グループを担当する厳密に r 個の OSD の一覧が生成されます。 ここで、r は特定のオブジェクトのレプリカの数です。 クラスター マップ内の情報に基づいて、このマッピングに含まれるアクティブな OSD が識別され、その OSD に接続して、指定されたオブジェクトの操作 (作成、読み取り、更新、削除などの操作) を行うことができます。
RADOS でのレプリケーション
RADOS では、オブジェクトは、そのオブジェクトの配置グループに関連付けられている複数の OSD 間でレプリケートされます。 これにより、特定の OSD が失敗した場合に、特定のオブジェクトの複数のコピーが確実に存在します。 RADOS には、レプリケーションが実際に実行される複数の使用可能なスキームがあります。これらはプライマリ コピー、チェーン、スプレー レプリケーション スキームです (図 10)。

図 10: RADOS でサポートされているレプリケーション モード。 (出典 2)
プライマリ コピー レプリケーション:プライマリ コピー レプリケーション スキームでは、クライアントは最初に使用可能な OSD (プライマリ レプリカ OSD) と対話してオブジェクトを操作します。 プライマリ レプリカ OSD によって要求が処理され、クライアントに応答します。 書き込みの場合、プライマリ レプリカの OSD によって書き込み要求が r-1 レプリカに転送されます。これにより、オブジェクトのローカル コピーが更新され、マスターに応答します。 マスターに対する書き込み操作は、そのオブジェクトの他の OSD によってすべての書き込みがコミットされるまで遅延されます。 マスターは、クライアントへの書き込みを承認します。 書き込みは、すべてのレプリカがプライマリ コピー OSD に応答するまで完了しません。 同じプロセスが読み取りにも適用されます。プライマリ コピーは、すべてのレプリカに接続され、オブジェクトの値がすべてのレプリカで同じになった後でのみ読み取りに応答します。
チェーン レプリケーション:オブジェクトに対する要求は、r番目 (最後) のレプリカが検出されるまで、チェーンに転送されます。 操作が書き込みの場合は、最後のレプリカまでの各レプリカにコミットされます。 最後のレプリカを含む最後の OSD によって、最終的にクライアントへの書き込みが承認されます。 クラスターからデータを読み取るために必要なホップ数を減らすために、読み取り操作は直接末尾に送られます。
スプレー レプリケーション:スプレー レプリケーションは、プライマリ コピー レプリケーションとチェーン レプリケーションの両方の要素を組み合わせています。 読み取り要求は、レプリカ チェーン内の最後の OSD に送られます。書き込みは最初に先頭に送信されます。 チェーンとは異なり、中央の OSD に対する更新は、プライマリ コピー レプリケーション スキームと同様に並列で実行されます。
これらのレプリケーション スキームに加えて、2 つの個別の受信確認メッセージを使用して、RADOS の永続化が処理されます (図 11)。 各 OSD には、それによって処理されるデータのバッファー キャッシュがあります。 更新はバッファー キャッシュに書き込まれ、ack メッセージを通じて直ちに受信確認が返されます。 このバッファー キャッシュは定期的にディスクにフラッシュされます。最後のレプリカによってデータがディスクにコミットされると、データが永続化されたことを示す commit メッセージがクライアントに送信されます。

図 11: RADOS での ack と commit メッセージ (出典 2)
RADOS の整合性モデル
クライアントからのメッセージとノード間のピアツーピア メッセージの両方について、RADOS 内のすべてのメッセージには、メッセージの順序付けと適用が一貫した方法で行われるようにタイムスタンプが付けられます。 メッセージ要求元からの古いクラスター マップが原因で誤ったメッセージが OSD によって検出された場合、そのメッセージ要求元を最新の状態にするために、増分マップ更新が送信されます。
RADOS によって提供される厳密な整合性の保証を慎重に処理する必要がある厄介なケースがあります。 (クラスター マップが変更されたときに) 特定の OSD の配置グループ マッピングが変更された場合、システムでは、古い OSD と新しい OSD 間の配置グループのハンドオフがシームレスかつ一貫した方法で行われるようにする必要があります。 配置グループの変更時に、新しい OSD が古い OSD に接続して状態の移行を行う必要があります。その間、古い OSD は変更内容を学習し、それらの特定の配置グループに対するクエリへの応答を停止します。
また、ネットワーク分断を引き起こすネットワーク障害が発生した場合に、厳密な一貫性の保証の実現が難しい場合もあります。 この場合、古いクラスター マップを使用している一部のクライアントでは、その OSD に対して引き続き読み取り操作を続行できますが、更新されたマップでは、その配置グループを担当する OSD が変更される可能性があります。 これは、CAP 定理の説明で既に強調表示されたエラー シナリオであることを思い出してください。 この場合、この不整合ウィンドウは常に存在します。 RADOS では、このシナリオの影響を軽減するために、すべての OSD で他のレプリカとのハートビートを既定の 2 秒間隔で行うように要求しています。 特定の OSD が特定のしきい値内の他のレプリカ グループに到達できない場合、その読み取りはブロックされます。 さらに、特定の配置グループの新しいプライマリとして割り当てられている OSD は、古い配置グループのプライマリからの移行の受信確認を受け取るか、またはハートビート間隔が経過した後に古い配置グループのプライマリがダウンしていると見なします。 これにより、ネットワーク分断が存在する場合に、RADOS クラスター内での潜在的な不整合ウィンドウが減少します。
RADOS の障害検出とフォールト トレランス
配置グループに割り当てられた OSD 間、または OSD とモニター ノードの間の通信が失敗したときに、RADOS 内でノード障害が検出されます。 ノードが、限られた回数の再接続試行で応答に失敗する場合、そのノードは停止中として宣言されます。 配置グループの一部である OSD では、ハートビート メッセージを交換して、エラーが検出されるようにします。 これにより、モニター ノードがクラスター マップの更新で主導権を握り、増分マップ更新メッセージを通じてすべてのノードに通知するようになります。 クラスター マップの更新後、OSD では、各配置グループに必要な数のレプリカが保持されるように、オブジェクトが相互に交換されます。 OSD は、自身が停止中として宣言されたことをメッセージを通じて検出した場合に、バッファーをディスクに同期し、自身を強制終了して、動作が一貫するようにします。
Ceph ファイル システム
前の図に示されているように、Ceph FS は、RADOS ストレージ システムに対する抽象化のレイヤーです。 RADOS には、オブジェクト名とは別のオブジェクトのメタデータの概念がありません。 Ceph ファイル システムを使用すると、ファイル メタデータを、RADOS に格納されている個々のファイル オブジェクトの上に階層化できます。 次のビデオでは、CephFS の概念について説明します。
Ceph FS では、OSD とモニターのクラスター ノードの役割に加えて、メタデータ (MDS) サーバーが導入されています (図 12)。 これらのサーバーには、ファイル システム メタデータ (ディレクトリ ツリー、アクセス制御リストとアクセス許可、モード、所有権情報、および各ファイルのタイムスタンプ) が格納されます。

図 12: Ceph ファイル システム内のメタデータ サーバー
Ceph FS によって使用されるメタデータは、さまざまな方法でローカル ファイル システムによって使用されるメタデータとは異なります。 ローカル ファイル システムでは、ファイルが inode によって記述されていることを思い出してください。このファイルには、ファイルのデータ ブロックを指すポインターの一覧が含まれています。 ローカル ファイル システム内のディレクトリは、単に特殊なファイルであり、他のディレクトリまたはファイルである可能性がある他の inode へのリンクがあります。 Ceph FS では、メタデータ サーバー内のディレクトリ オブジェクトには、その内部に埋め込まれているすべての inode が含まれます。
動的サブツリーのパーティション分割
最初は、単一のメタデータ サーバーによってクラスターのメタデータ全体が処理されます。 メタデータ サーバーがクラスターに追加されると、ファイル システムのディレクトリ ツリーがパーティション分割され、結果のメタデータ サーバーのグループに割り当てられます (図 13)。 各 MDS では、カウンターを使用して、そのディレクトリ階層内のメタデータの需要度が測定されます。 重み付けスキーム3 は、ディレクトリ内の特定のリーフ ノードのカウンターだけでなく、そのディレクトリ要素のルートまでの先祖のカウンターも更新するために使用されます。 したがって、各 MDS は、クラスターに追加されたときに新しい MDS に移動できるメタデータ内にホットスポットの一覧を保持できます。

図 13: Ceph ファイル システムでの動的サブツリー パーティション分割
メタデータ サーバーのキャッシュとフォールト トレランス
通常、Ceph FS 内のメタデータ サーバーでは、メモリ内にメタデータ情報がキャッシュされ、ほとんどの要求がメモリから処理されます。 さらに、MDS サーバーでは、ジャーナルの形式が使用されます。これにより、更新内容はジャーナル オブジェクトとしてダウンストリームの RADOS に送信されます。これらは、メタデータ サーバーごとに書き込まれます。 メタデータ サーバーの障害が発生した場合は、ジャーナルを再生して、新しい MDS または既存の MDS 上のツリーの障害が発生した MDS サーバーの部分を再構築することができます。
リファレンス
- Weil, S. A.、Brandt, S. A.、Miller, E. L.、および Maltzahn, C.(2006)。 2006 ACM/IEEE conference on Supercomputing 122 議事録の「CRUSH: レプリケートされたデータの管理されたスケーラブルな分散配置*」
- Weil, S. A.、Brandt, S. A.、Miller, E. L.、および Maltzahn, C.(2006)。 Ceph: スケーラブルでパフォーマンスの高い分散ファイル システム 第 7 回 Symposium on Operating Systems Principles (OSDI) 307-320 の議事録
- Weil, S. A.、Pollack, K. T.、Brandt, S. A.および Miller, E. L.(2004 年)。 2004 ACM/IEEE conference on Supercomputing 4 の議事録の「*ペタバイト規模のファイル システム向けの動的メタデータ管理*」