HDInsight クラスターの作成
HDInsight クラスターを作成するには、簡単なユーザー インターフェイスの Azure portal を使用する方法から、自動化されたデプロイに利用できるスクリプト セットアップまで、さまざまな方法があります。 次の表は、HDInsight クラスターのセットアップに使用できるいろいろな方法を示しています。
| クラスターの作成に使用 | Web ブラウザー | コマンド ライン | REST API | SDK |
|---|---|---|---|---|
| Azure portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Azure Resource Manager テンプレート | ✔ |
HDInsight のすべてのセットアップで、以下を含む基本情報が必要です。
[基本] タブ
プロジェクトの詳細
サブスクリプション
HDInsight の課金と管理に使用する Azure サブスクリプションを定義します。
リソース グループ名
リソース グループは、同じアプリケーションまたはアプリケーションのライフ サイクルに一般的に関連する Azure のテクノロジとサービスを論理的にグループ化したものです。 複数のサービスを同じリソース グループにグループ化すると、管理のメンテナンスが容易になります。

クラスターの詳細
クラスター名
HDInsight クラスター名には次の制限があります。
- 使用できる文字: a-z、0-9、A-Z
- 最大長:59
- 予約済みの名前: apps
- クラスター名の範囲はすべての Azure が対象で、すべてのサブスクリプションに適用されます。 そのため、クラスター名は全世界で一意である必要があります。
- 先頭の 6 文字は VNET 内で一意である必要があります
場所
クラスターの種類を格納する場所を指定します。 場所が定義されていない場合、クラスターは既定のストレージと同じ場所に併置されます。 待機時間を短縮するために、ユーザーにできるだけ近い場所にする必要があります。
クラスターの種類
リソースのクラスターでプロビジョニングされるテクノロジ スタックを定義します。 保有するデータの種類とシナリオで必要な種類の処理に基づいて、クラスターの種類を選択します。 次の表に、使用可能なクラスターの種類を示します。
| クラスターの種類 | 説明 |
|---|---|
| Apache Hadoop | HDFS とシンプルな MapReduce プログラミング モデルを使用して、バッチ データを処理および分析するフレームワーク。 |
| Apache Spark | ビッグ データ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする、オープンソースの並列処理フレームワーク。 |
| HBase | Hadoop 上に構築された NoSQL データベース。大量の非構造化データおよび半構造化データ (数十億行 x 数百万列の可能性もある) へのランダム アクセスと厳密な整合性が提供されます。 |
| Apache Interactive Query | 対話型で高速な Hive クエリのメモリ内キャッシュ。 |
| Apache Kafka | ストリーミング データ パイプラインおよびアプリケーションを構築するために使用されるオープンソースのプラットフォームです。 Kafka には、データ ストリームの発行とサブスクライブを可能にするメッセージ キュー機能も用意されています。 |
バージョン
このクラスターの HDInsight のバージョンを定義します。 HDInsight 4.0 が最新バージョンで、最新のフレームワークがクラスターにプロビジョニングされています。
クラスターの資格情報
HDInsight クラスターには、クラスターの作成時に 2 つのユーザー アカウントを構成できます。
クラスターのログインとパスワード
既定のユーザー名は admin です。Azure portal の基本構成を使用します。 "クラスター ユーザー" と呼ばれることもあります。
SSH ユーザー名とパスワード
SSH を使用してクラスターに接続する際に使用します。
注意
Enterprise セキュリティ パッケージでは、HDInsight を Active Directory と Apache Ranger と統合することができます。 Enterprise セキュリティ パッケージを使用して、複数のユーザーを作成できます。
[ストレージ] タブ
HDInsight クラスターでは、[ストレージ] 画面に表示される次のストレージ オプションを使用できます。
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage General Purpose v2
- Azure Storage General Purpose v1
- Azure Storage ブロック BLOB (セカンダリ ストレージとしてのみサポート)
[ストレージ] 画面では、プライマリ ストレージ アカウントと既定のコンテナーを定義できます。 また、追加の Azure Storage をクラスターにリンクすることもできます。 metastore 設定を使用すると、クラスターが削除された後に、Hive テーブルを格納するための外部 SQL データベースを定義でき、外部ストアにメタデータを格納することで Oozie のパフォーマンスを向上させることができます。

セキュリティとネットワーク
クラスターの種類が Hadoop、Spark、HBase、Kafka、および対話型クエリの場合は、Enterprise セキュリティ パッケージを有効にすることができます。 このパッケージには、Apache Ranger を使用し、Microsoft Entra ID と統合することで、より安全なクラスター セットアップを行うオプションが用意されています。
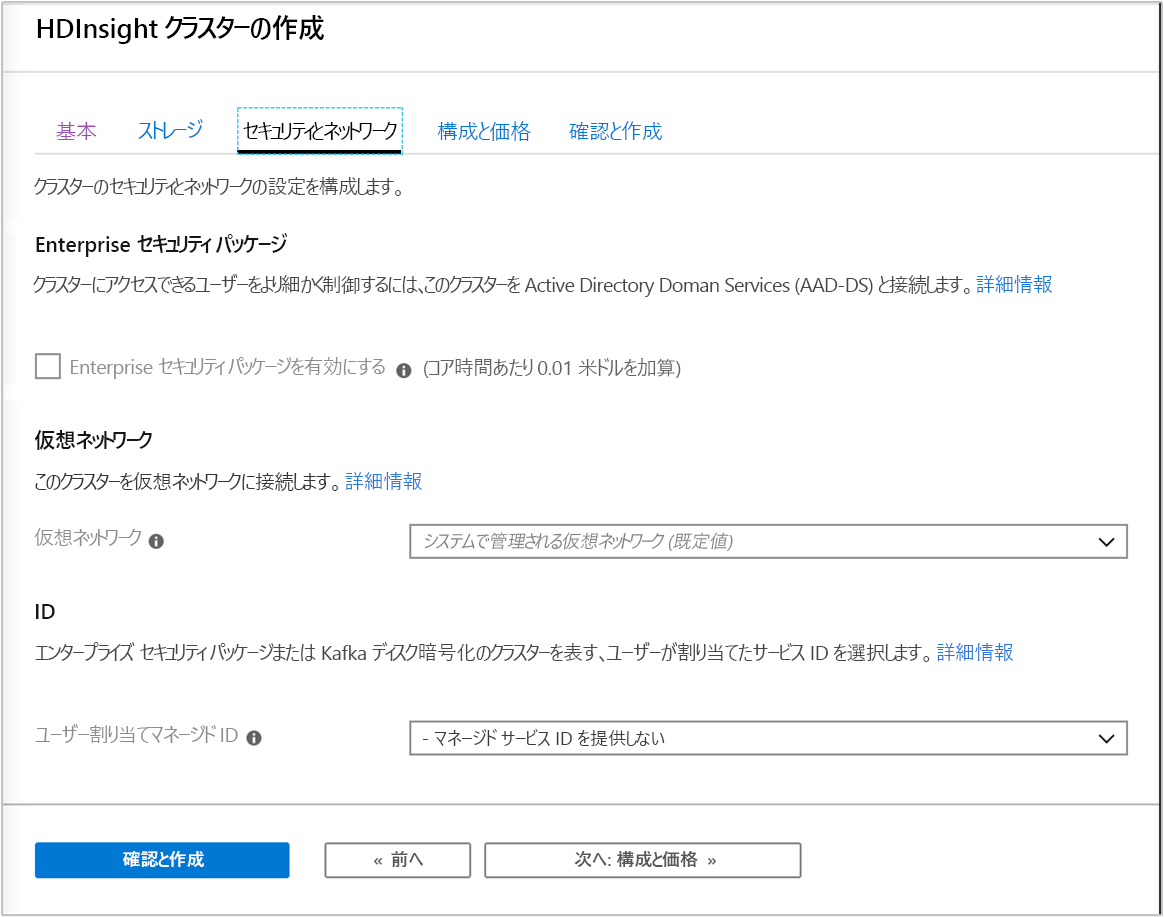
また、VNet 内に HDInsight クラスターをデプロイすることを常にお勧めします。この画面で仮想ネットワークを定義して設定することができます。 複数の種類の HDInsight クラスターにまたがるテクノロジがソリューションに必要な場合は、Azure 仮想ネットワークで、必要な種類のクラスターを接続できます。 この構成により、クラスターと、それにデプロイするすべてのコードで相互に直接通信できるようになります。
構成と価格
このページを使用して、クラスターのサイズとパフォーマンスを構成し、推定コスト情報を表示できます。 この画面では、ヘッド (マスター) ノードとワーカー ノードにも使用される仮想マシンを定義できます。
