インデックスについて理解する
すべての Azure Cosmos DB for NoSQL コンテナーには、各項目のインデックス作成方法を決定する組み込みポリシーがあります。 既定では、このポリシーにより、任意の項目の作成、更新、または削除操作でインデックスを更新し、インデックスにすべての項目のすべてのプロパティを含める必要があります。 このインテリジェントな既定値は、インデックスのチューニングまで深く掘り下げることなく、優れた予測可能なクエリ パフォーマンスが得られるため、多くのソリューションの開始時に最適です。
既定のポリシーの例を実際に確認しましょう。
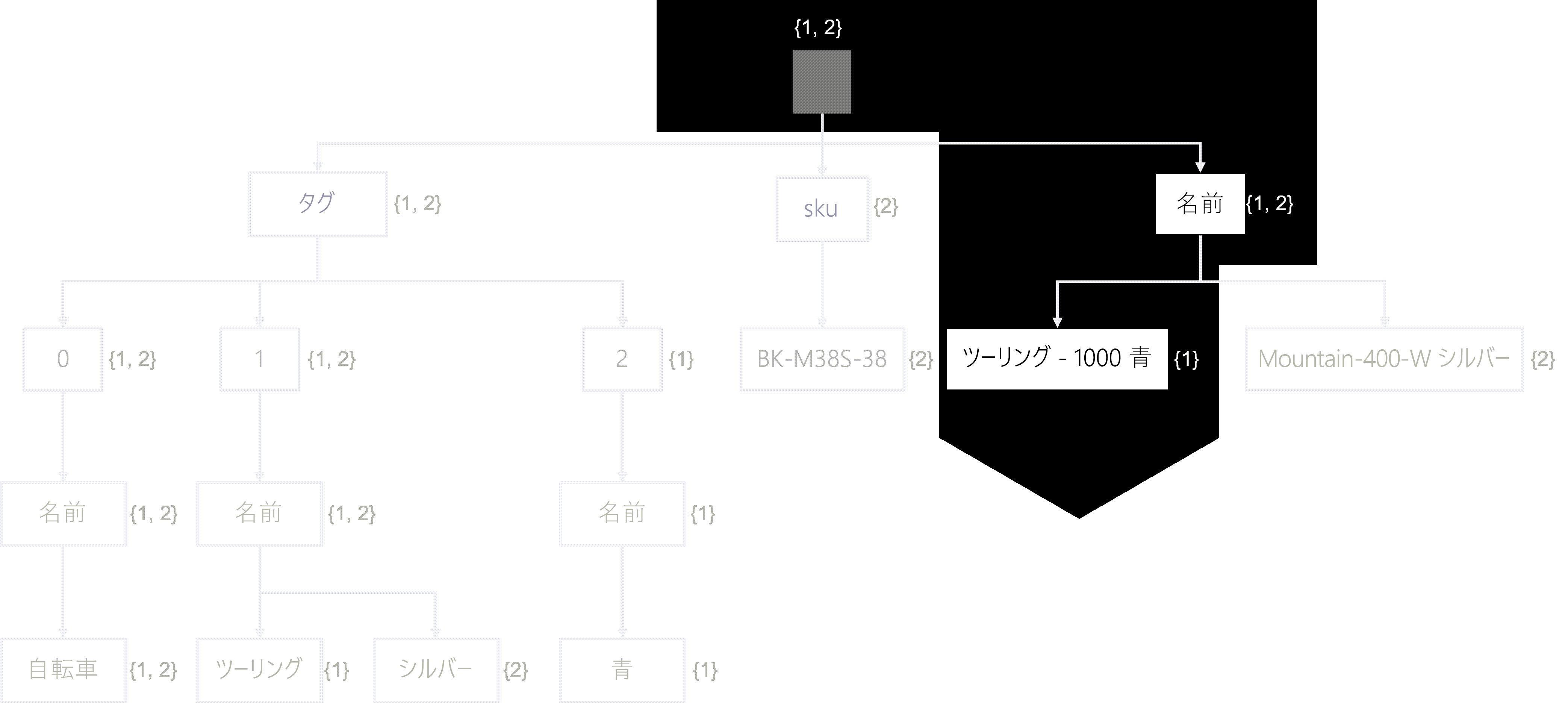
ここでは、3 つのタグ (自転車、ツーリング、青) を持つ Touring-1000 Blue という名前の製品を表す JSON オブジェクトがあります。 タグ配列内の内容の数に注意する必要があります。
{
"name": "Touring-1000 Blue",
"tags": [
{
"name": "bike"
},
{
"name": "touring"
},
{
"name": "blue"
}
]
}
この JSON オブジェクトをツリーとして表す場合、この表現には name プロパティとその値の両方のトラバーサル パスが含まれます (Touring-1000 Blue)。 ツリーには、 タグ 配列内の 3 つのオブジェクトの 3 つのトラバーサル パスも含まれています。それぞれに、 名前 プロパティとそれぞれの値のリーフ ノードがあります。
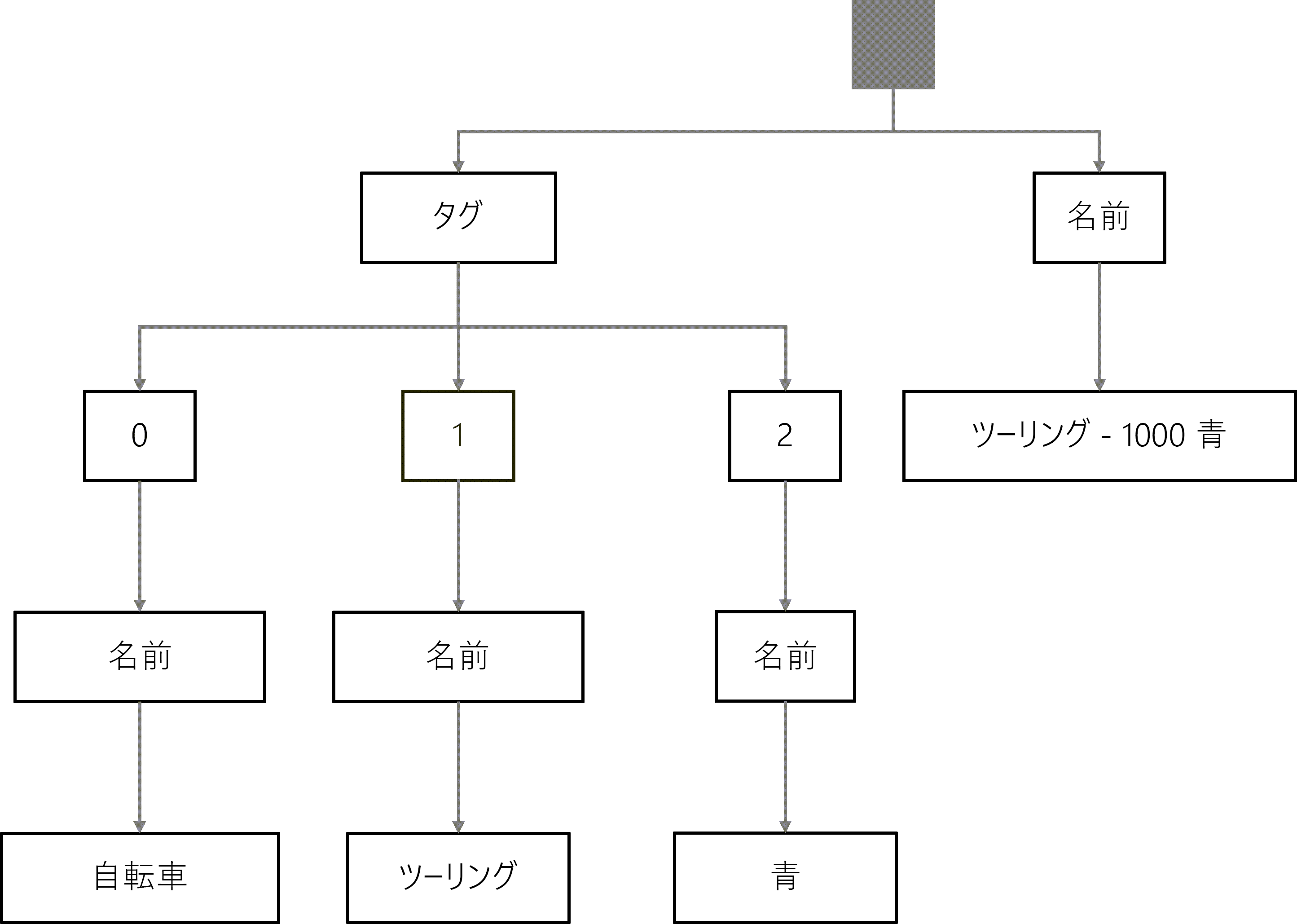
カウンターポイントとして、 Mountain-400-W Silver という名前の 2 つのタグ (bike と silver) のみを含む製品を表す別の JSON オブジェクトを次に示します。 このオブジェクトは、値が BK-M38S-38 の sku プロパティを含むという点でも一意です。
{
"name": "Mountain-400-W Silver",
"sku": "BK-M38S-38",
"tags": [
{
"name": "bike"
},
{
"name": "silver"
}
]
}
この JSON オブジェクトのツリー表現には、 名前 と SKU プロパティの単純なトラバーサル パスが含まれています。 また、 タグ 配列内の 2 つのオブジェクトの 2 つのトラバーサル パスと、 その名前 プロパティとそれぞれの値に対応するリーフ ノードも含まれています。
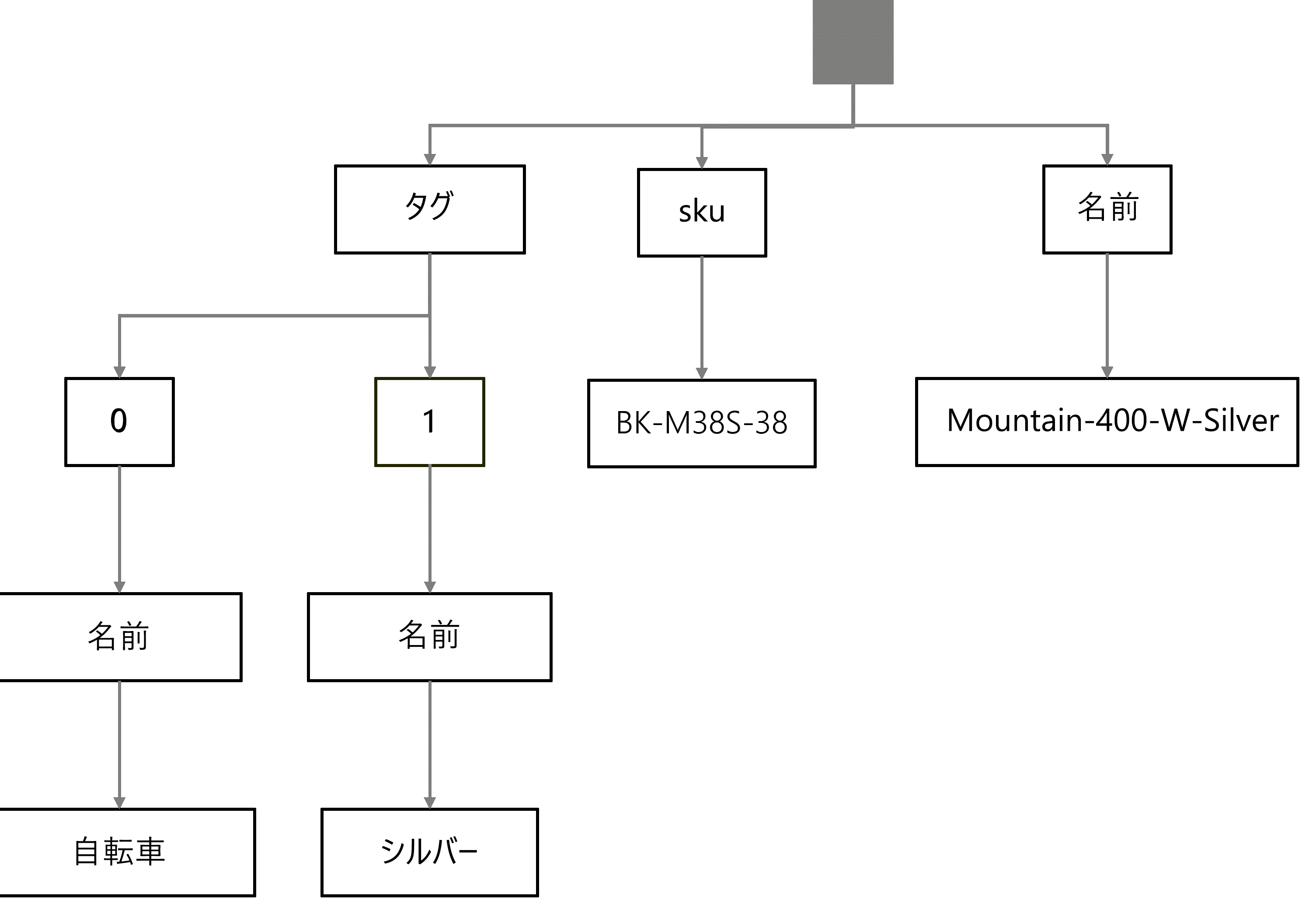
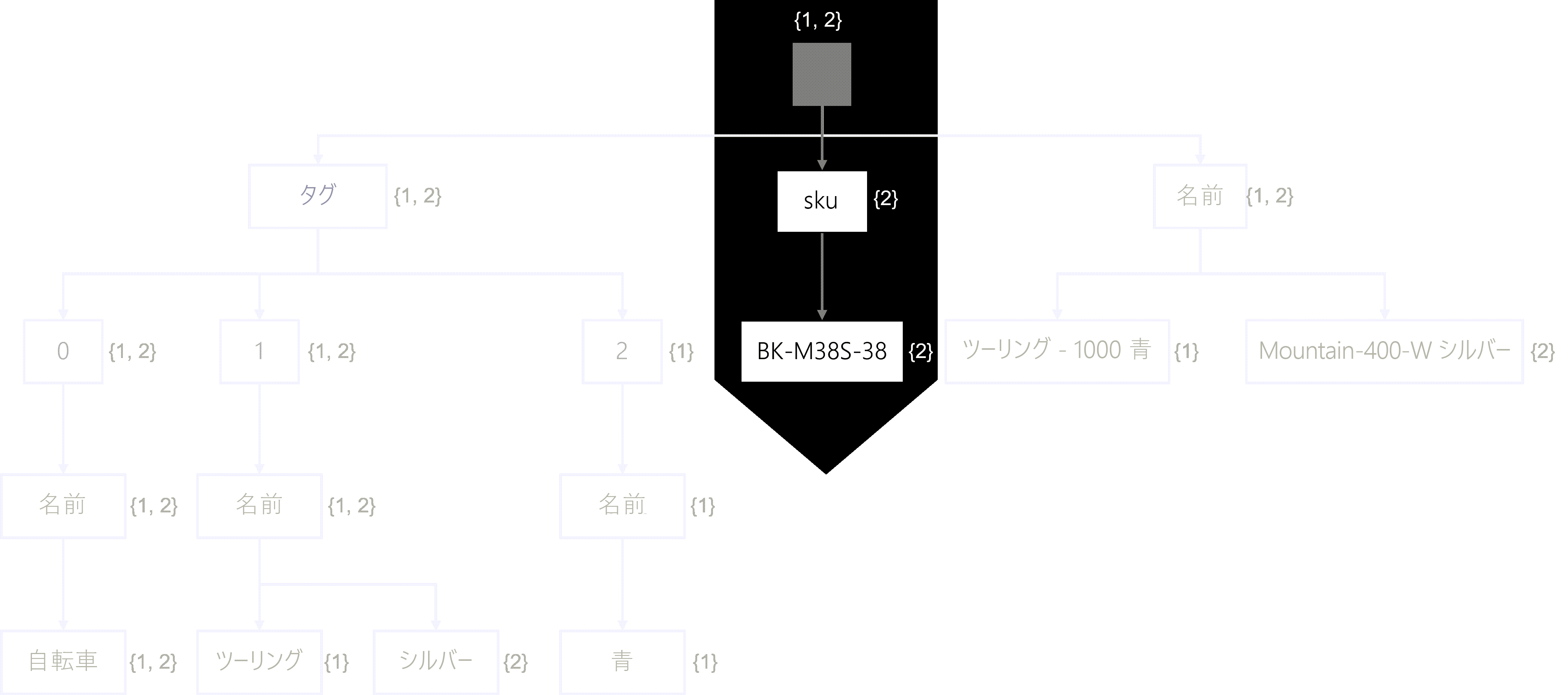
コンテナーのインデックスを概念化する場合、私たちはインデックスをコンテナー内の各項目のすべてのツリーの共用体と考える傾向があります。 全体として、これにより 逆インデックスが作成され 、クエリ操作の実行時にデータベース エンジンが高速かつ効率的に走査できるようになります。 ツリー内の各ノードには、インデックス内のどの項目が特定のノードと一致するかを示すメタデータがあります。
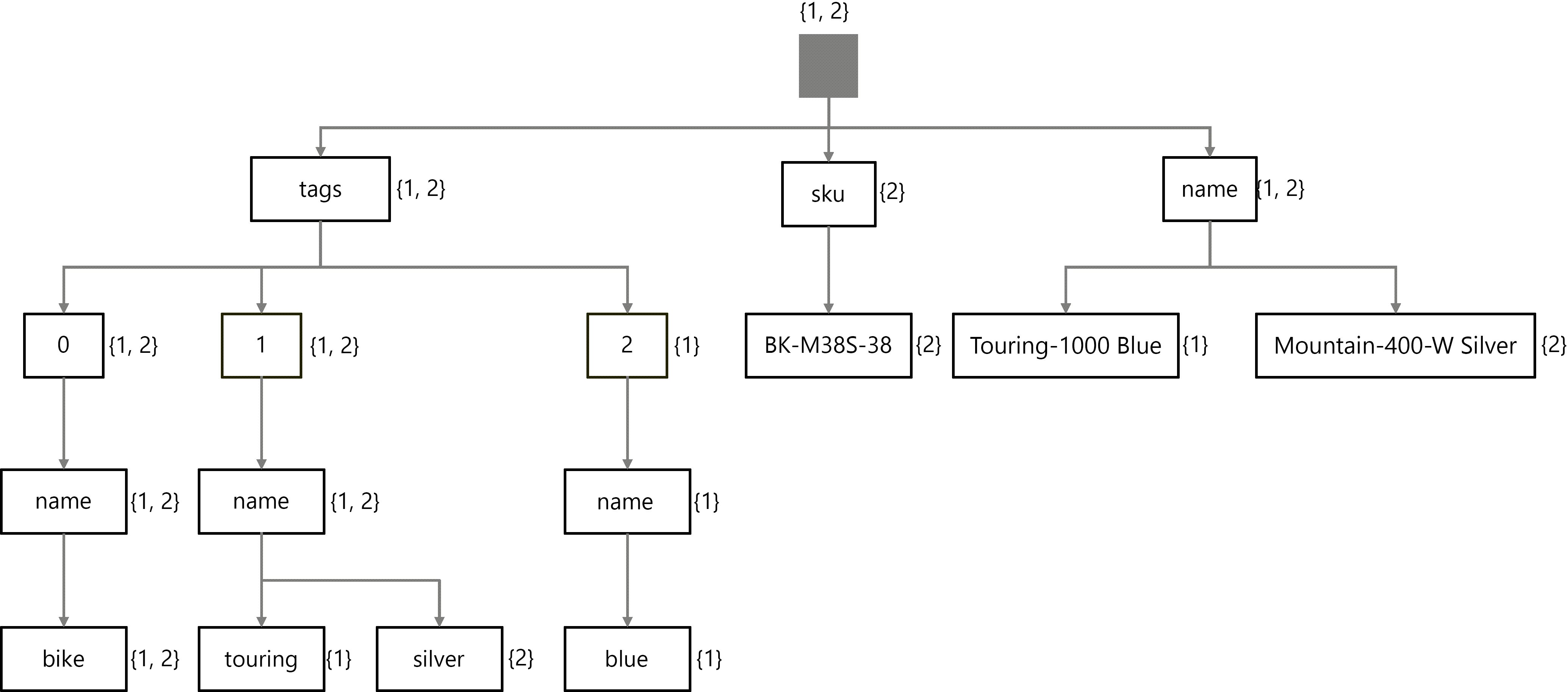
この例を示すため、次の SQL クエリを考えてみましょう。
SELECT * FROM products p WHERE p.sku = 'BK-M38S-38'
検索エンジンは、各項目を個別に走査するのではなく、逆インデックスを走査します。 このクエリでは、サンプル走査について説明します。
- 最初に、検索エンジンがルートから開始されます。 現在のところ、すべての項目が一致します。
- 次に、検索によって sku プロパティが走査されます。 # 2 項目のみが一致するようになりました。
- 最後に、検索は BK-M38S-28 ノードで終了します。 それでも、 #2 項目のみが一致します。
検索結果は、#2 項目 (Mountain-400-W Silver) が一致し、SQL クエリはこの項目からすべてのフィールドを返します。
SQL クエリの別の例を使用します。
SELECT p.id FROM products p WHERE p.name = 'Touring-1000 Blue'
同様の走査を実行できます。
- ルートから始まり、すべての項目が一致します。
- name プロパティに移動しても、すべての項目が一致します。
- 最後に、 Touring-1000 Blue ノードで終わり、 #1 項目のみが一致します。
検索結果は、#1 項目 (Touring-1000 Blue) が一致し、SQL クエリはこの項目の ID フィールドのみを返します。