リレーショナル データ構造について調べる
リレーショナル データベースは、テーブルのセットで構成されます。 テーブルには、0 行 (テーブルが空の場合)、またはそれより多い数の行が存在します。 各テーブルには、固定された列のセットがあります。 テーブル間のリレーションシップは、主キーと外部キーを使用して定義できます。また、SQL を使用して、テーブル内のデータにアクセスすることもできます。
一般的なリレーショナル データベースには、テーブルとは別に、データ編成の最適化やアクセス速度の向上に役立つ、その他の構造体が含まれています。 このユニットでは、これらの構造体のうち、インデックスとビューの 2 つについて詳しく確認します。
インデックスとは
インデックスは、テーブル内でのデータ検索に便利です。 テーブルのインデックスは、書籍の最後に記載される索引のようなものです。 書籍の索引には、並べ替えられた参照のセットと、各参照が存在するページが記載されます。 書籍内である項目に関する参照を見つけたい場合は、索引を調べます。 索引内のページ番号を使用すると、書籍内の正しいページに直接進むことができます。 索引がなければ、探している参照を見つけるために、書籍を最初から最初まで読むことになります。
データベースにインデックスを作成する場合は、テーブルの列を指定します。インデックスによって、テーブル内の対応する行へのポインターも含めて、このデータのコピーが並べ替えられた順序で格納されます。 WHERE 句でこの列を指定するクエリをユーザーが実行すると、データベース管理システムは、このインデックスを使用してテーブル全体を 1 行ごとスキャンする場合よりも速くデータを取り込むことができます。 次の例では、このクエリによって顧客 C1 のすべての注文を取得します。 Orders テーブルには、Customer ID 列のインデックスがあります。 データベース管理システムでは、インデックスを参照して、Orders テーブル内の一致するすべての行をすばやく検索することができます。
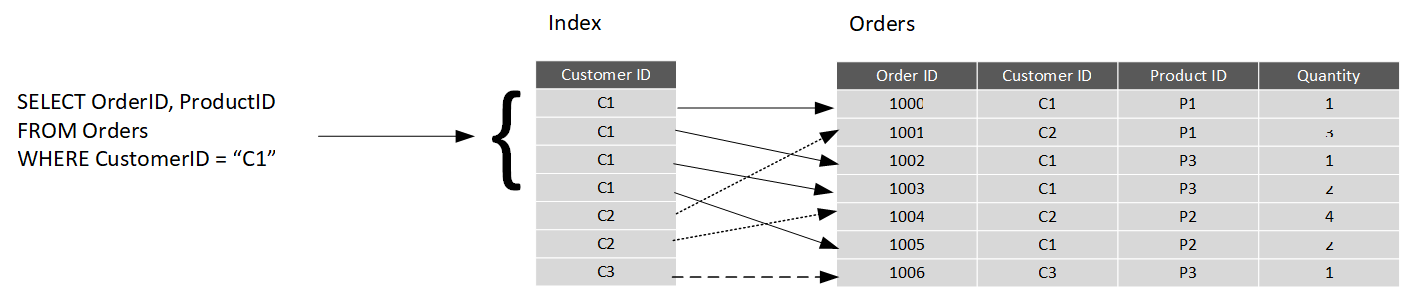
テーブルでは、インデックスを多数作成できます。 そのため、特定の製品のすべての注文を検索する必要がある場合は、Orders テーブルの Product ID 列に別のインデックスを作成すると便利です。 ただし、インデックスはコストがかからないわけではありません。 インデックスは、ストレージ領域をさらに消費する可能性があります。また、テーブル内でデータを挿入、更新、または削除するたびに、そのテーブルのインデックスを維持しなくてはなりません。 この追加の作業によって、挿入、更新、削除の各操作が遅くなるうえに、追加の処理料金が発生する場合があります。 したがって、作成すべきインデックスを決定する際には、クエリの実行を高速化するインデックスと、他の操作の実行コストのバランスについて見極める必要があります。 読み取り専用のテーブル、または変更頻度の低いデータが含まれるテーブルでは、インデックスが増えるとクエリのパフォーマンスが向上します。 テーブルに対してクエリを実行する頻度は低いものの、挿入、更新、削除 (OLTP に関係するテーブルなど) の回数が多い場合は、テーブルにインデックスを作成すると、システムの速度が低下する可能性があります。
一部のリレーショナル データベース管理システムは、"クラスター化インデックス" もサポートしています。 クラスター化インデックスは、インデックス キーによってテーブルを物理的に再編成します。 このような配置によって、クエリのパフォーマンスはさらに向上します。リレーショナル データベース管理システムで、インデックスからの参照に従って、基になるテーブル内にある対応するデータを検索する必要がなくなるからです。 次の画像は、Customer ID 列にクラスター化インデックスが含まれている Orders テーブルを示しています。
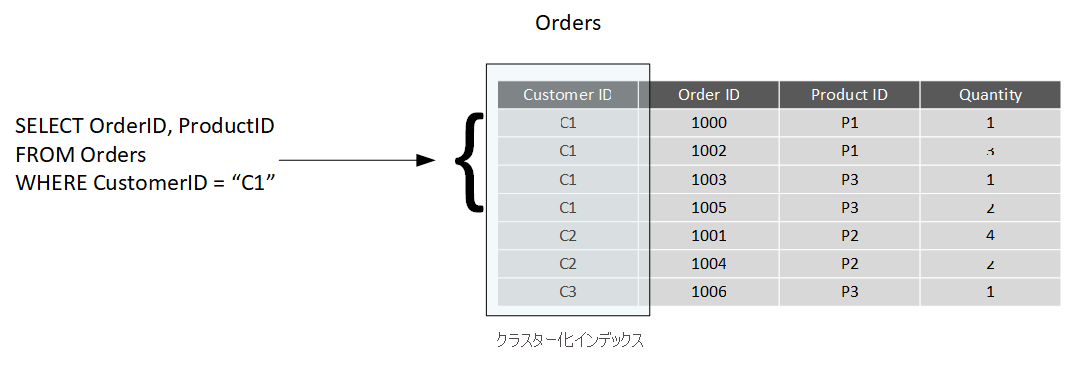
これらをサポートするデータベース管理システムでは、テーブルにクラスター化インデックスを 1 つしか含めることができません。
ビューとは
ビューは、クエリの結果セットに基づく仮想テーブルです。 最も単純なケースでは、ビューを、基になるテーブル内の指定された行のウィンドウと考えることができます。 たとえば、次のように、特定の製品の注文 (この場合は、製品 P1) を一覧表示するビューを Orders テーブルに作成できます。
CREATE VIEW P1Orders AS
SELECT CustomerID, OrderID, Quantity
FROM Orders
WHERE ProductID = "P1"
ビューに対してクエリを実行し、テーブルとほぼ同じ方法でデータをフィルター処理できます。 次のクエリでは、ビューを使用して、顧客 C1 の注文を検索します。 このクエリでは、この顧客によって行われた製品 P1 の注文のみが返されます。
SELECT CustomerID, OrderID, Quantity
FROM P1Orders
WHERE CustomerID = "C1"
ビューでは、テーブルを結合することもできます。 顧客および注文された製品の詳細を定期的に検索する必要がある場合は、前のユニットで示した結合クエリに基づいてビューを作成します。
CREATE VIEW CustomersProducts AS
SELECT Customers.CustomerName, Orders.QuantityOrdered, Products.ProductName
FROM Customers JOIN Orders
ON Customers.CustomerID = Orders.CustomerID
JOIN Products
ON Orders.ProductID = Products.ProductID
次のクエリでは、このビューを使用して、顧客名および QuantityOrdered 100 よりも大きいすべての注文の製品名を検索します。
SELECT CustomerName, ProductName
FROM CustomersProducts
WHERE QuantityOrdered > 100