演習 - 最新のデータ ウェアハウス アーキテクチャのコンポーネントを特定する
データ ウェアハウスは、単にビジネス データを格納するだけのものではありません。 データは、毎年、指数関数的に増加します。 データの量だけでなく、データの種類も、構造化、半構造化、さらには非構造化データまで管理する必要があります。 機械学習、レポート、その他の目的のためにデータの取り込み、変換、および準備を行う際には、データの速度と多様性が、データ エンジニアリングの課題になります。
最新のデータ ウェアハウスは、これらの課題に対処するために役立ちます。 優れたデータ ウェアハウスは、追加の価値も提供します。たとえば、すべてのデータを一元化する役割を担ったり、しだいに増加するデータに合わせてスケーリングしたり、データ エンジニア、データ アナリスト、データ サイエンティスト、および開発者に使い慣れたツールとエコシステムを提供したりします。
これらの要素を詳しく見ていきましょう。
すべてのデータの一元化
最新のデータ ウェアハウスでは、Synapse Analytics を使用する場合、すべてのデータ用の 1 つのハブがあります。
Synapse Analytics を使用すると、オーケストレーション パイプラインを通じて、複数のデータ ソースからデータを取り込むことができます。
[統合] ハブを選択します。
[統合] ハブでは、統合パイプラインを管理します。 Azure Data Factory (ADF) に習熟している場合は、このハブに慣れていることでしょう。 パイプラインの作成エクスペリエンスは、ADF の場合と同じです。これは Azure Synapse Analytics に組み込まれたもう 1 つの強力な統合であり、データ移動と変換のパイプラインのために Azure Data Factory を使用する必要がなくなります。
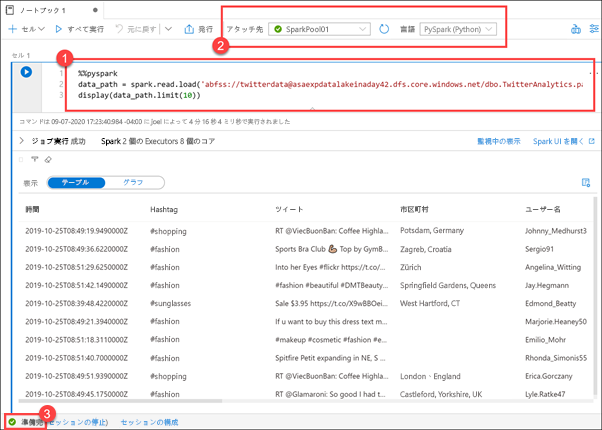
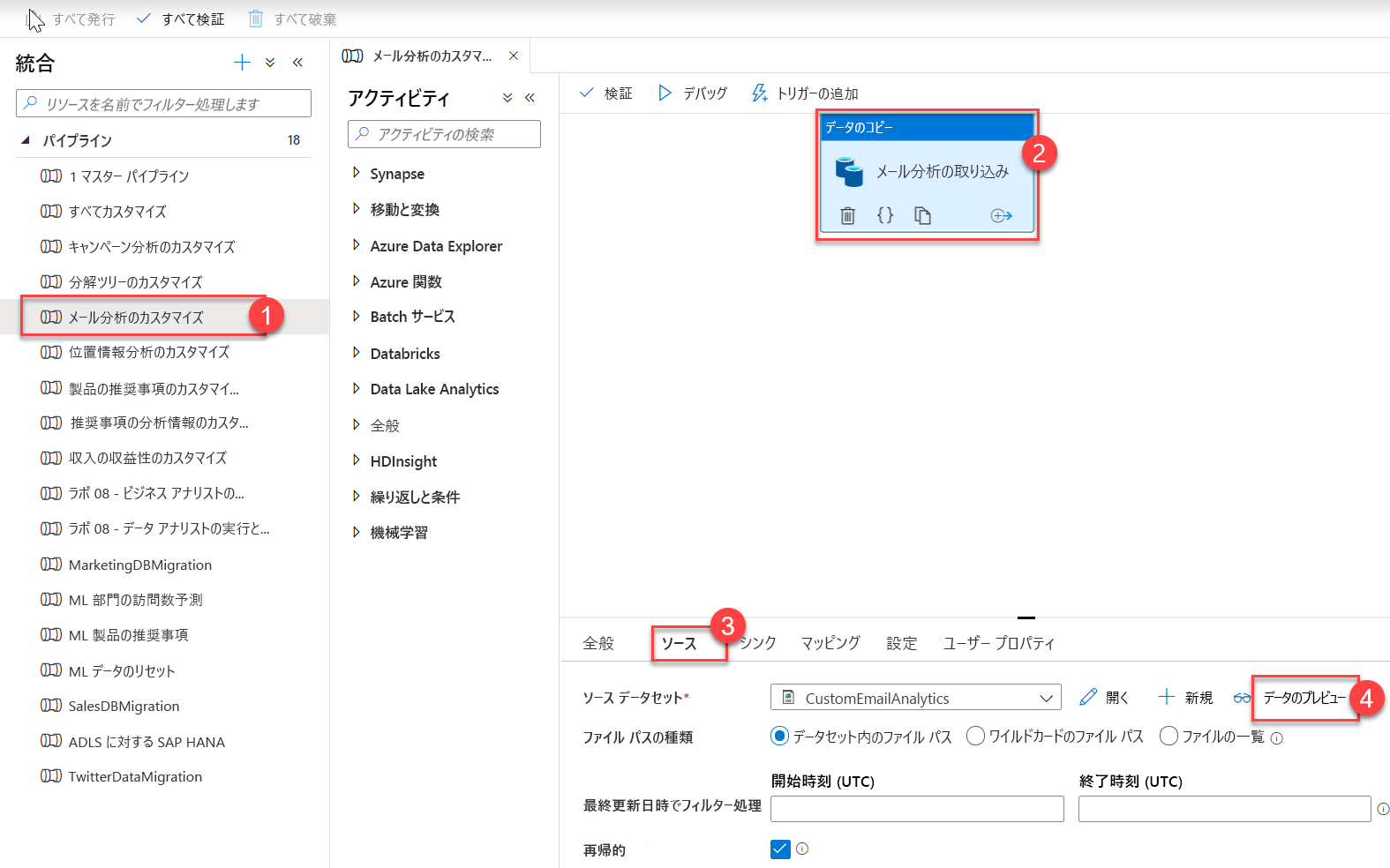
パイプラインを展開し、[Customize EMail Analytics](電子メール分析のカスタマイズ) (1) を選択します。 キャンバスで [データのコピー] アクティビティを選択し (2)、[ソース] タブを選択してから (3)、[データのプレビュー] (4) を選択します。
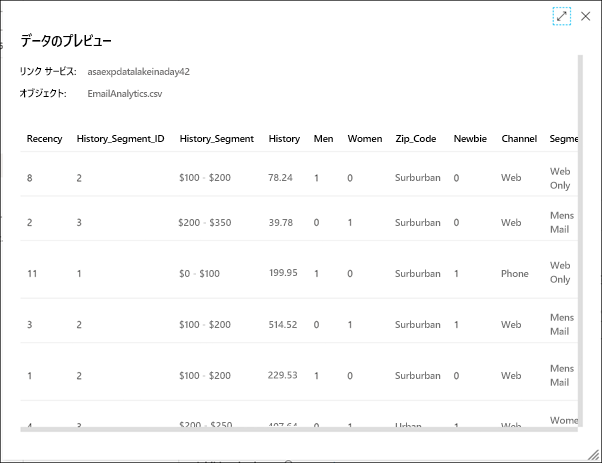
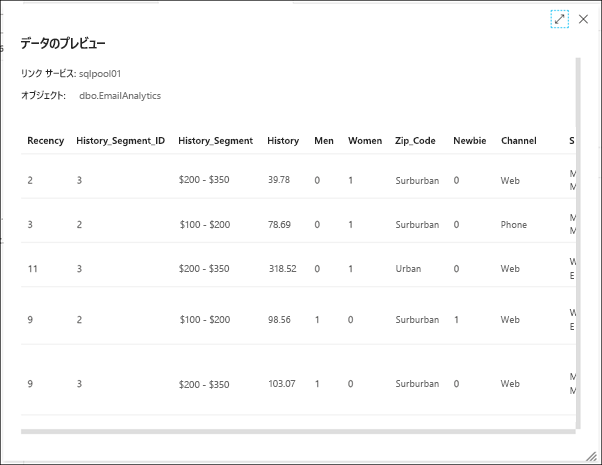
パイプラインによって取り込まれるソース CSV データが、次のように表示されます。
プレビューを閉じ、[CustomEmailAnalytics] ソース データセットの横にある [開く] を選択します。
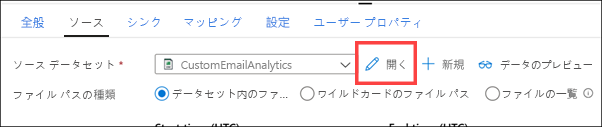
データセットの接続に関連付けられているリンクされたサービスと、CSV ファイルのパスが表示されます (1)。 パイプラインに返すデータセットを閉じます (2)。
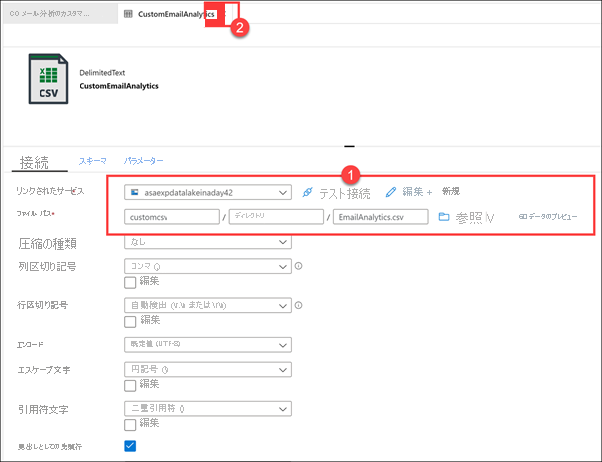
パイプラインで [シンク] タブを選択します (1)。 一括挿入のコピー方法が選択されていて、EmailAnalytics テーブルを切り詰めるコピー前スクリプトがあります。このスクリプトは、CSV ソースのデータのコピーの前に実行されます (2)。 EmailAnalytics シンク データセットの横にある [開く] を選択します (3)。
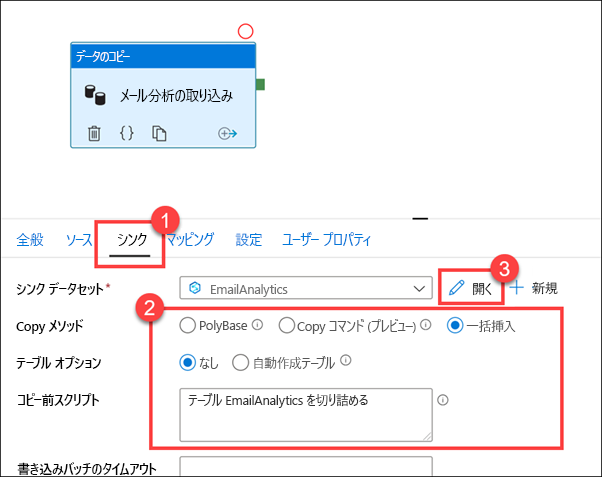
[リンクされたサービス] は Azure Synapse Analytics SQL プールで、[テーブル] は EmailAnalytics (1) です。 パイプラインの "データのコピー" アクティビティでは、このデータセット内の接続の詳細を使用して、CSV データ ソースから SQL プールにデータをコピーします。 [データのプレビュー] (2) を選択します。
テーブルに既にデータが含まれていることを確認できます。これは、過去にパイプラインを正常に実行できたことを意味します。
EmailAnalytics データセットを閉じます。
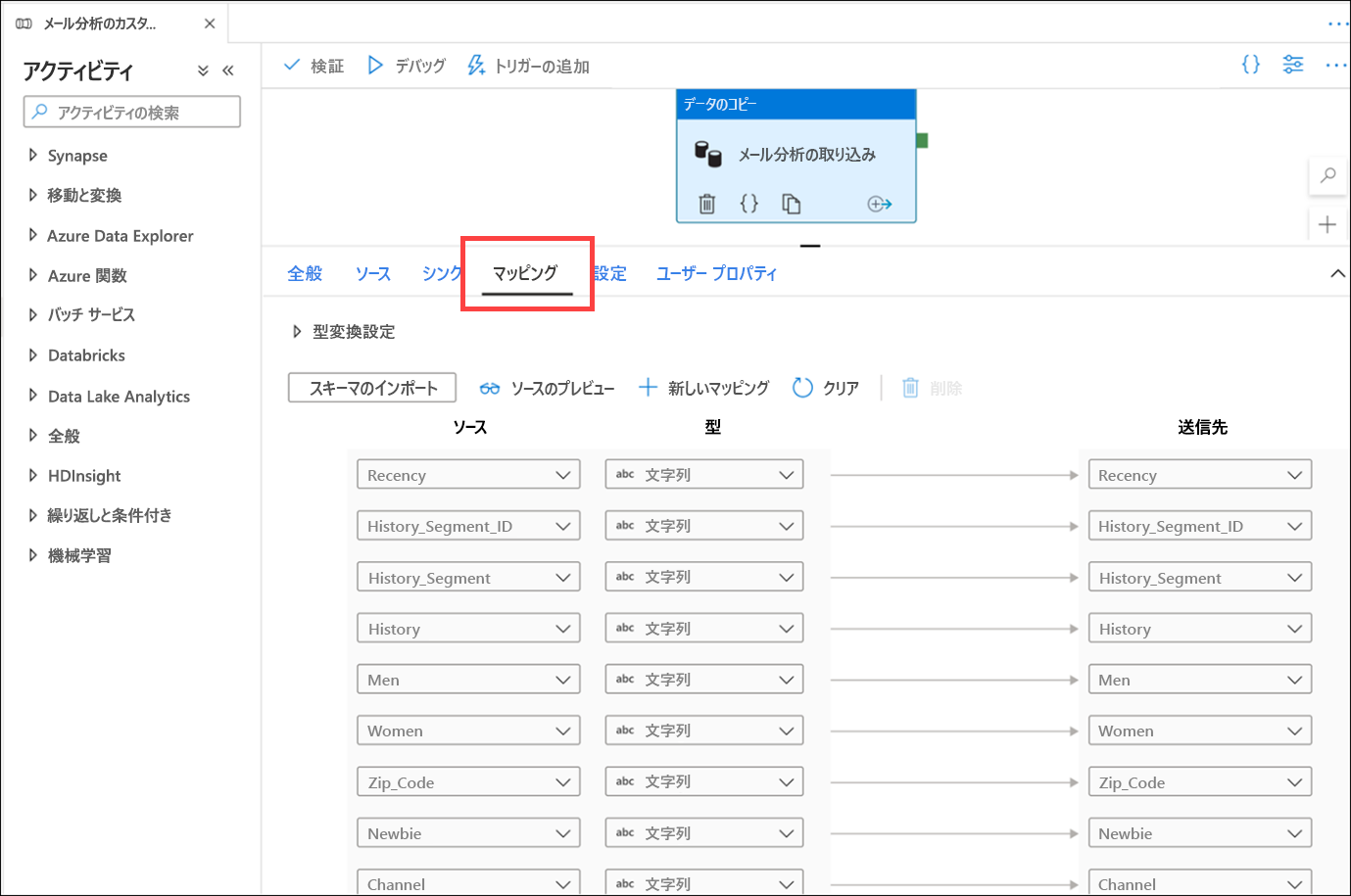
[マッピング] タブを選択します。ここでは、ソースとシンクのデータセット間のマッピングを構成します。 [スキーマのインポート] ボタンを押すと、データセットのスキーマが CSV ファイルや JSON ファイルなどの非構造化または半構造化データ ソースに基づいている場合、スキーマの推測が試行されます。 また、Synapse Analytics SQL プールなどの構造化データ ソースのスキーマも読み取られます。 スキーマ マッピングを手動で作成することもできます。その場合は、[+ 新しいマッピング] をクリックするか、データ型を変更します。
[MarketingDBMigration] (1) パイプラインを選択します。 パイプラインのキャンバス (2) に注意してください。
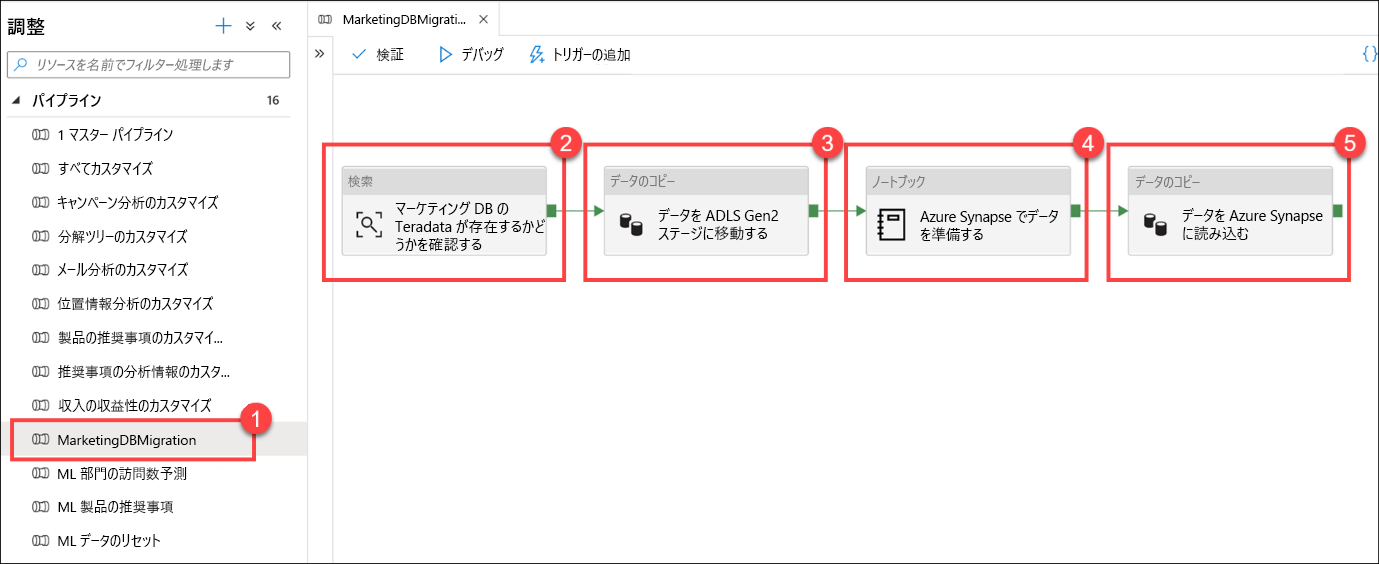
このパイプラインは、Teradata データベースからデータをコピーする役割を果たします。 最初のアクティビティは、ソース データが存在することを確認するための検索 (2) です。 データが存在する場合は、"データのコピー" アクティビティ (3) に進んで、ソース データをデータ レイク (ADLS Gen2 プライマリ データ ソース) に移動します。 次の手順は Notebook アクティビティ (4) です。このアクティビティでは、Synapse Notebook 内の Apache Spark を使用してデータ エンジニアリング タスクを実行します。 最後の手順は、もう 1 つの "データのコピー" アクティビティ (5) です。準備されたデータを読み込み、Azure Synapse SQL プールのテーブルに格納します。
このワークフローは、データ移動オーケストレーションを実施する場合に一般的です。 Synapse Analytics パイプラインを使用すると、データの移動と変換の手順を簡単に定義し、これらの手順を最新のデータ ウェアハウス内で保守および監視できる反復可能なプロセスとしてカプセル化できます。
[SalesDBMigration] (1) パイプラインを選択します。 パイプラインのキャンバス (2) に注意してください。
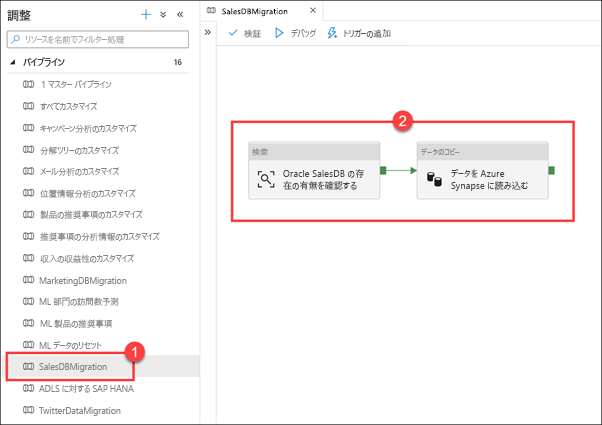
次に、外部データ ソースをウェアハウスに統合するために役立つデータ移動オーケストレーション パイプラインのもう 1 つの例を示します。 この例では、Oracle 販売データベースから Azure Synapse SQL プール テーブルにデータを読み込みます。
[SAP HANA TO ADLS](SAP HANA から ADLS へ) パイプラインを選択します。 このパイプラインは、財務 SAP HANA データ ソースから SQL プールにデータをコピーします。
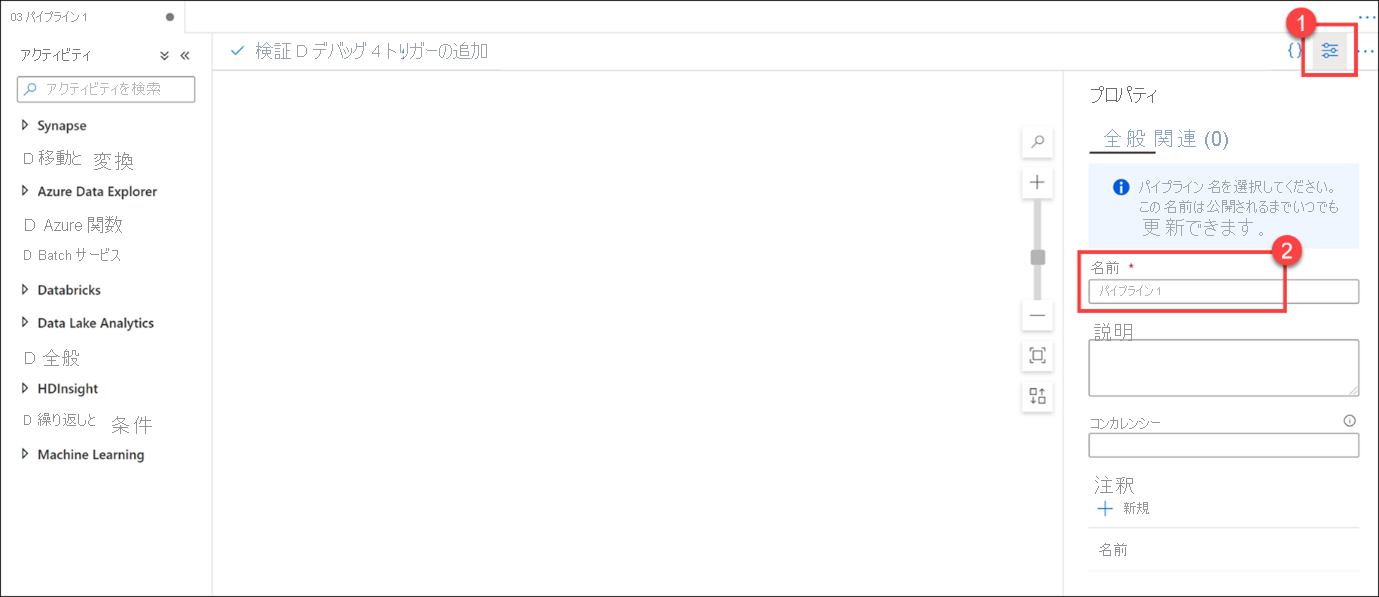
[統制] ブレードの上部にある [+] ボタンを選び、[パイプライン] を選んで、新しいパイプラインを作成します。

新しいパイプラインが開かれると、[プロパティ] ブレードが表示され (1)、パイプラインに名前を指定できます (2)。
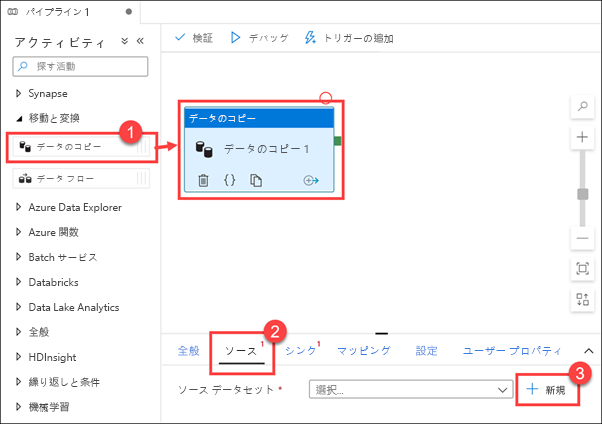
[Move & transform]\(移動と変換\) アクティビティ グループを展開し、[データのコピー] アクティビティをデザイン キャンバスにドラッグします (1)。 "データのコピー" アクティビティを選択した状態で、[ソース] タブを選択し (2)、ソース データセットの横にある [+ 新規] (3) を選択します。
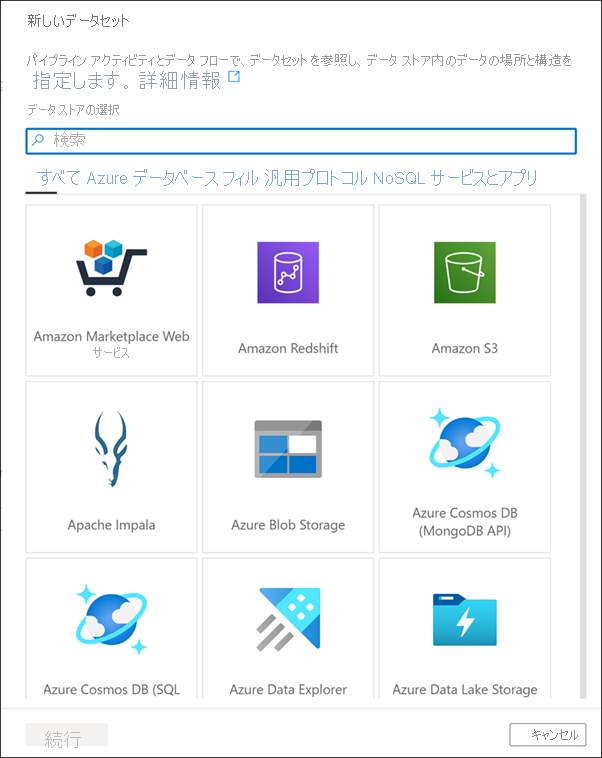
データセットのソースの一覧をスクロールして、多数のデータ接続を自由に表示してから、[キャンセル] をクリックします。
無制限のデータ スケーリング
[管理] ハブを選択します。
[SQL プール] (1) を選択します。 [SQLPool01] の上にポインターを合わせ、[スケール] ボタンを選択します (2)。
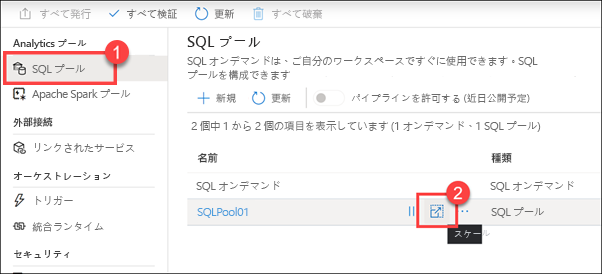
[パフォーマンス レベル] スライダーを右および左にドラッグします。
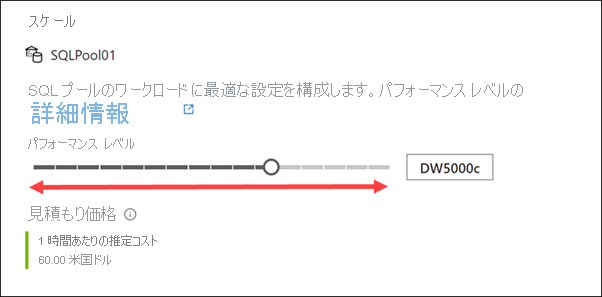
SQL プールに割り当てられる Data Warehouse ユニット (DWU) の数を調整することで、コンピューティングをスケールアウトまたはスケールインすることができます。 この調整により、ユニットを追加するにつれて、読み込みとクエリのパフォーマンスが直線的に向上します。
スケーリング操作を行うために、SQL プールは、最初にすべての受信クエリを中止し、次にトランザクションをロールバックして一貫性のある状態を確保します。 スケーリングは、トランザクションのロールバックが完了して初めて実行されます。
このスライダーを使用して、いつでも SQL コンピューティングをスケーリングできます。 また、プログラムを使用して Data Warehouse ユニットを調整することもできます。これにより、スケジュールやその他の要因に基づいてプールを自動的にスケーリングするシナリオが可能になります。
[スケール] ダイアログを取り消し、[管理] ハブの左側のメニューで [Apache Spark プール] (1) を選択します。 [SparkPool01] の上にポインターを合わせ、自動スケーリングの設定ボタンを選択します (2)。
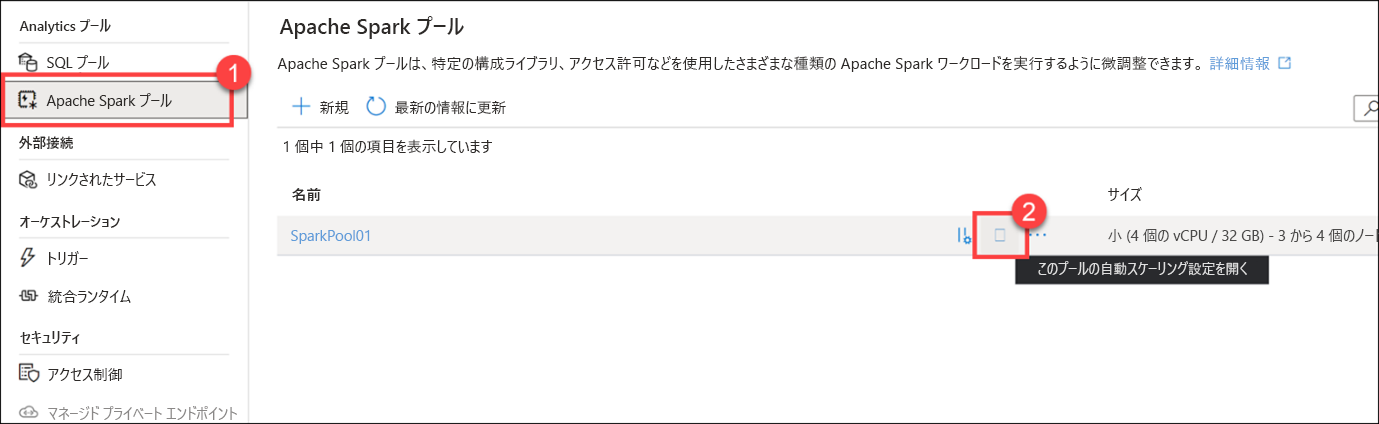
[Number of nodes](ノードの数) スライダーを右および左にドラッグします。
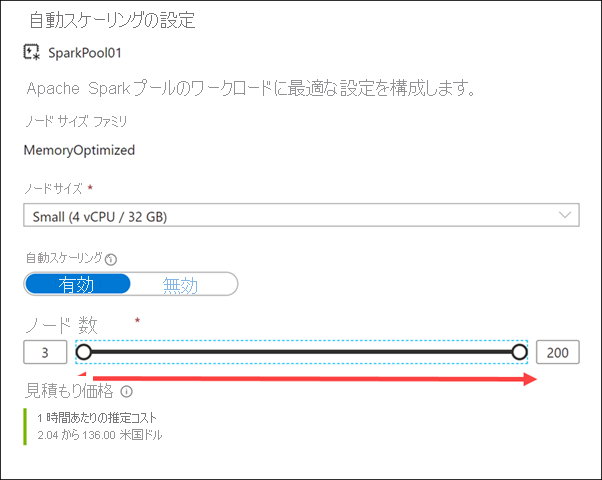
自動スケーリング設定を無効にすることで、Apache Spark プールを固定サイズになるように構成できます。 ここでは、自動スケーリングを有効にし、適用されるスケールの量を制御するためにノードの最小数と最大数を設定しました。 自動スケーリングを有効にすると、Synapse Analytics によって負荷のリソース要件が監視され、ノードの数がスケールアップまたはスケールダウンされます。 そうするために、保留中の CPU、保留中のメモリ、空き CPU、空きメモリ、および使用されているメモリが、ノード メトリックを通じて継続的に監視されます。 これらのメトリックが 30 秒ごとに確認され、値に基づいてスケーリングの判断が行われます。
スケーリング操作が完了するには、1 分から 5 分かかる場合があります。
自動スケーリング ダイアログを取り消し、管理ハブの左側のメニューで [リンクされたサービス] (1) を選択します。 WorkspaceDefaultStorage の ADLS Gen2 ストレージ アカウントをメモしておきます (2)。
新しい Azure Synapse Analytics ワークスペースをプロビジョニングするときに、既定のストレージ Azure Data Lake Storage Gen2 アカウントを定義します。 Data Lake Storage Gen2 によって、Azure Storage は、Azure 上にエンタープライズ データ レイクを構築するための基盤となります。 Data Lake Storage Gen2 は、当初から、何百ものギガビット単位のスループットを維持しつつ、複数のペタバイト単位の情報を利用可能にする目的で設計されているため、大量のデータを簡単に管理することができます。
階層型名前空間によって、ファイルがディレクトリの階層として整理され、アクセスが効率的になり、ファイルレベルに至るきめ細かいセキュリティを設定できます。
ADLS Gen2 では、データ レイクを事実上無制限にスケーリングできます。 必要に応じてさらに ADLS Gen2 アカウントを追加して、拡張性と柔軟性を高めることができます。
使い慣れたツールとエコシステム
[開発] ハブを選択します。
[SQL スクリプト] を展開し、[1 SQL Query With Synapse](1 SQL クエリと Synapse) を選択します。 SQLPool01 (2) に接続していることを確認します。 スクリプトの最初の行を強調表示 (3) し、実行します。 Sales テーブル内のレコードの数が 3,443,486 であることを確認します (4)。
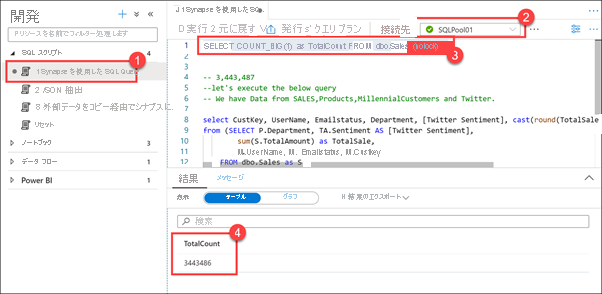
この SQL スクリプトの最初の行を実行すると、約 350 万行が含まれていることがわかります。
スクリプトの残りの部分 (8 行目から 18 行目) を強調表示し、実行します。
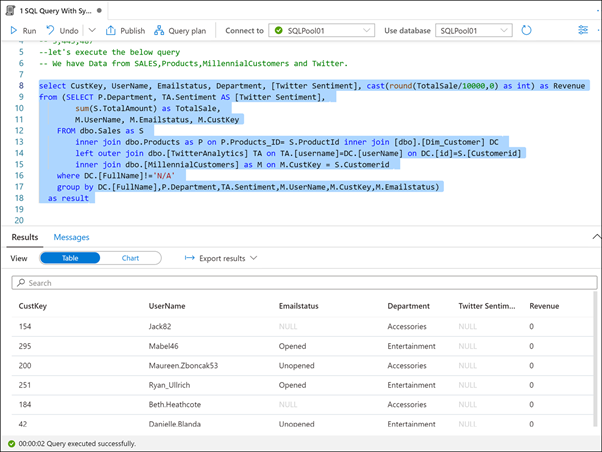
Synapse Analytics のような最新のデータ ウェアハウスを使用する利点の 1 つは、すべてのデータを 1 か所にまとめることができることです。 ここで実行したスクリプトは、販売データベース、製品カタログ、人口統計データから抽出されたミレニアル世代の顧客、および twitter からのデータを結合します。
[2 JSON Extractor](2 JSON エクストラクター) (1) スクリプトを選択し、まだ SQLPool01 に接続されていることを確認します。 最初の select ステートメント (2) (3 行目) を強調表示します。 TwitterData 列 (3) に格納されているデータが JSON 形式であることを確認します。
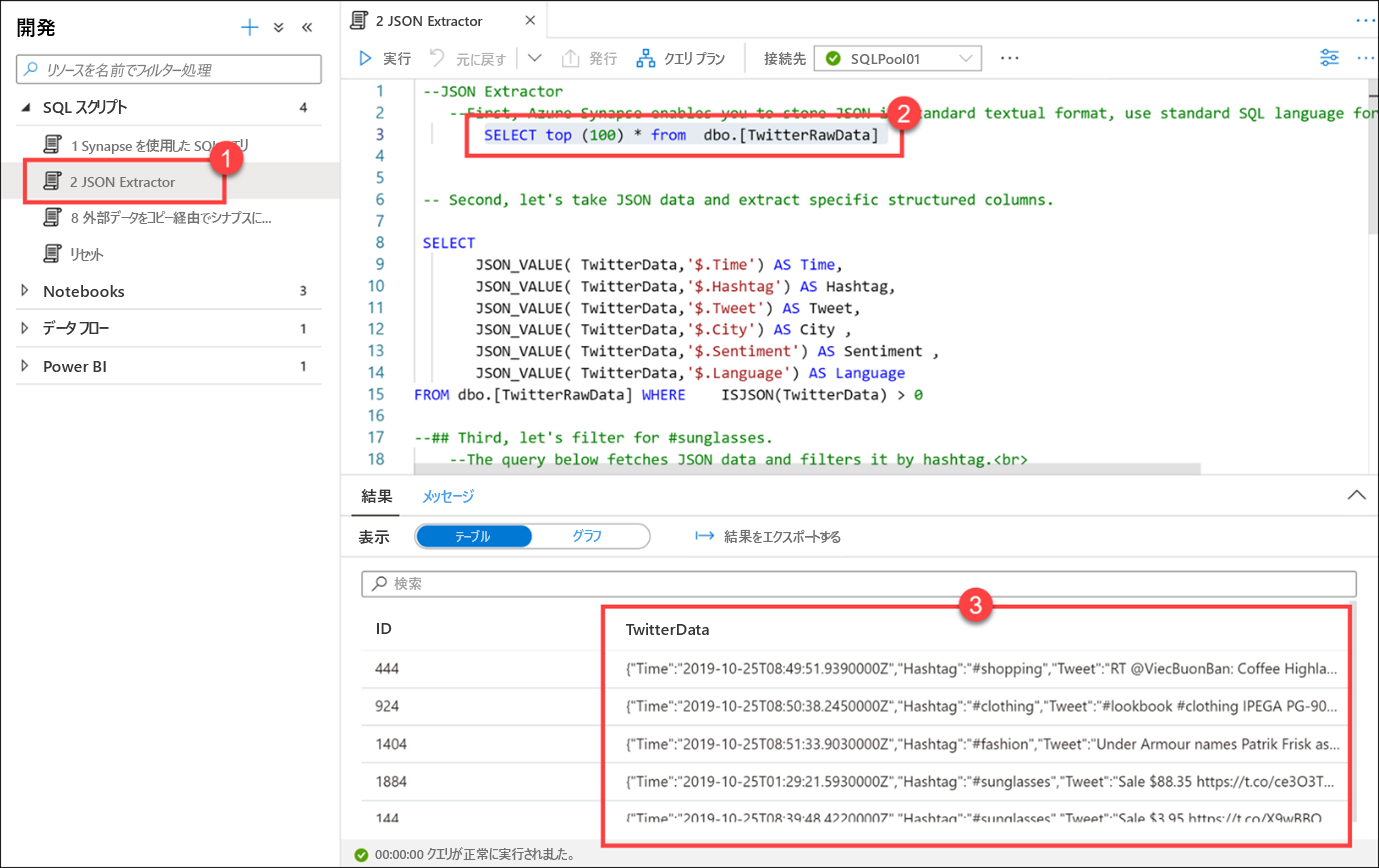
Azure Synapse を使用すると、標準のテキスト形式で JSON を格納できます。 JSON データのクエリには、標準の SQL 言語を使用します。
次の SQL ステートメント (8 行目から 15 行目) を強調表示し、実行します。
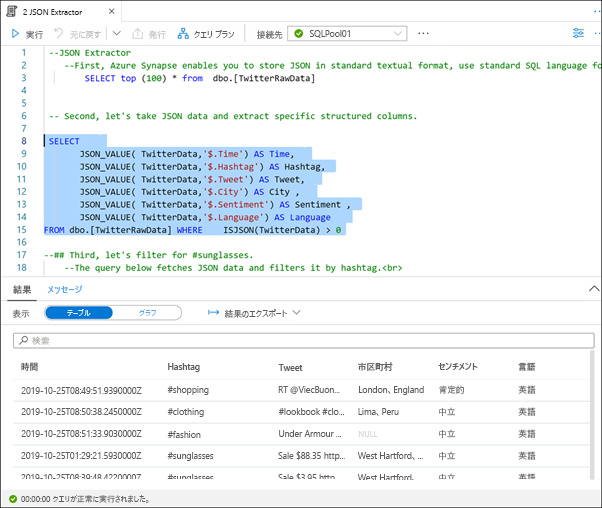
JSON_VALUE や ISJSON などの JSON 関数を使用して、JSON データを抽出したり、特定の構造化列に抽出したりすることができます。
次の SQL ステートメント (21 行目から 29 行目) を強調表示し、実行します。
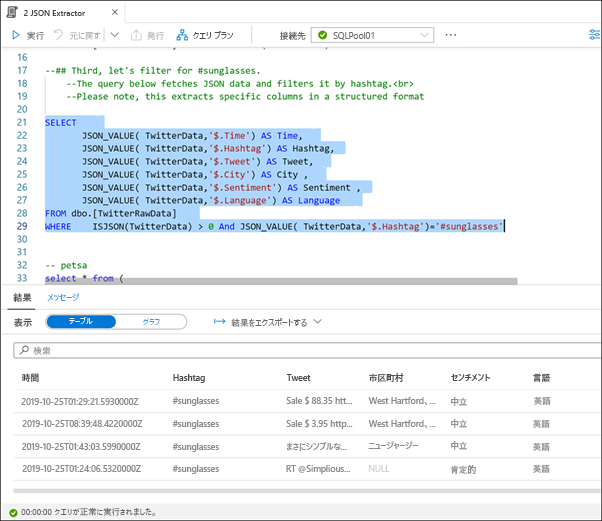
#sunglassess ハッシュタグをフィルター処理します。 このクエリは、JSON データをフェッチし、構造化列に抽出してから、派生した Hashtag 列でフィルター処理を行います。
最後のスクリプトは同じことを行いますが、サブクエリ形式だけを使用します。
[8 External Data To Synapse Via Copy Into](コピーを通じて外部データを Synapse に) (1) スクリプトを選択します。 実行しないでください。 スクリプト ファイルをスクロールし、以下のコメントを使用してスクリプトの動作を理解します。
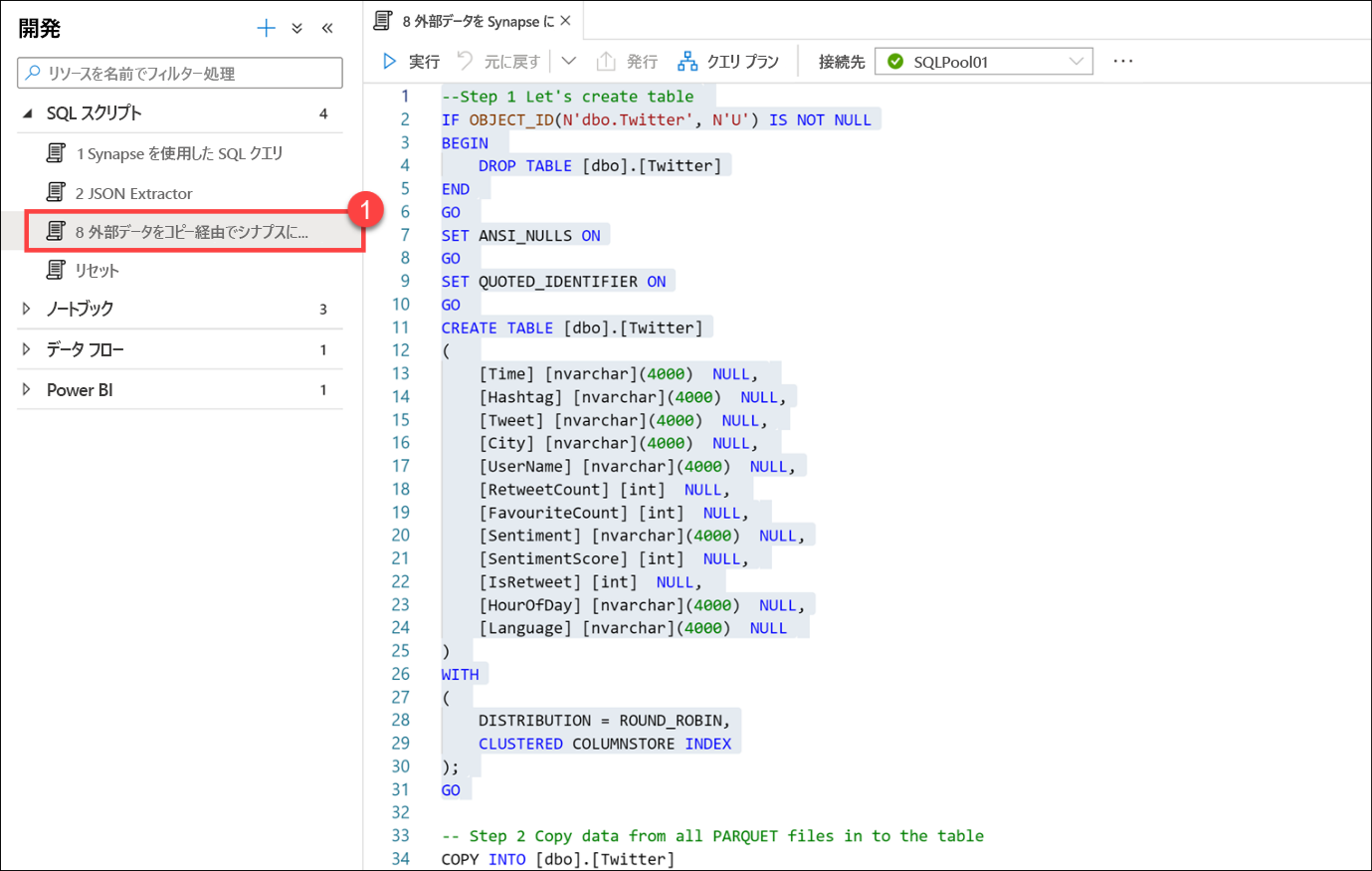
このスクリプトでは、Parquet ファイルに格納されている Twitter データを格納するテーブルを作成します。 Parquet ファイルに格納されているすべてのデータを新しいテーブルにすばやく効率よく読み込むために、COPY コマンドを使用します。
最後に、最初の 10 行を選択して、データの読み込みを確認します。
COPY コマンドと PolyBase を使用すると、ここに示すような T-SQL スクリプトを通じて、またはオーケストレーション パイプラインから、さまざまな形式のデータを SQL プールにインポートできます。
[データ] ハブを選択します。
[リンク] タブ (1) を選択し、Azure Data Lake Storage Gen2 グループ、プライマリ ストレージ アカウントの順に展開して、[twitterdata] コンテナー (2) を選択します。 [dbo.TwitterAnalytics.parquet] ファイルを右クリックし (3)、[新しいノートブック] (4) を選択します。
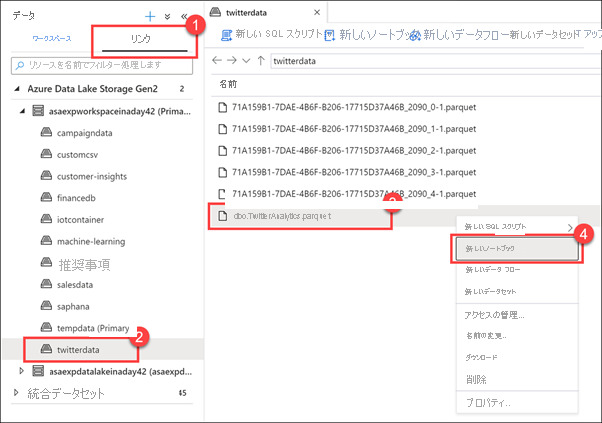
Synapse Studio には、アタッチされているストレージ アカウントに格納されているファイルを操作するためのいくつかのオプションが用意されています。たとえば、新しい SQL スクリプト、ノートブック、データ フロー、または新しいデータセットを作成することです。
Synapse ノートブックを使用すると、Apache Spark の機能を活用して、データの探索と分析、データ エンジニアリング タスク、およびデータ サイエンスを行うことができます。 プライマリ データ レイク ストレージ アカウントなど、リンクされたサービスによる認証と承認は完全に統合されているため、アカウントの資格情報を処理することなく、すぐにファイルの操作を開始できます。
ここでは、[データ] ハブで右クリックした Parquet ファイルで Spark DataFrame を読み込む新しいノートブック (1) を示しています。 いくつかの簡単な手順で、すぐにファイルの内容を調べ始めることができます。 ノートブックの上部に、これが Spark プールの SparkPool01 にアタッチされていて、ノートブックの言語が Python (2) に設定されていることが表示されます。
Spark プールの準備ができていない場合は、ノートブックを実行しないでください (3)。 プールがアイドル状態の場合は、開始までに最大で 5 分かかることがあります。 または、ノートブックを実行し、後で戻ってきて結果を表示することもできます。