事業継続とディザスター リカバリーの計画を立てる
あなたは、組織からアプリケーションのサイトの回復戦略を設計するよう依頼されています。 まず、ハイブリッド環境のサイト回復を構築するための特定の要件を理解する必要があります。 また、Azure で利用できるツールについても理解しておく必要があります。
このユニットでは、主要なインフラストラクチャ、目標復旧時間 (RTO)、回復ポイントの目標 (RPO) を識別する方法について説明します。 使用しているサービスとしてのプラットフォーム (PaaS) サービスに関連する可能性のある要件について学習します。 また、バックアップとディザスター リカバリーに向けて計画を立てる方法についても説明します。 最後に、サイトの回復ソリューションの構築に役立つ Azure の機能についても説明します。
事業継続とディザスター リカバリー
適切なサイトの回復ソリューションを設計するために、BCDR 計画を策定する必要があります。 BCDR は、重大なイベントが発生した後にアプリケーションを機能状態に復元するのに役立つプロセスを指します。 このイベントは、地震などの自然災害である可能性があります。 または、データベースの削除など、技術的な種類のものもあります。 このようなイベントの規模は広範囲にわたり、回復するには大きな労力が伴います。
優れたディザスター リカバリー プロセスを策定するには、まず障害が引き起こすビジネスへの影響を評価する必要があります。 回復プロセスを可能な限り自動化するとします。 当然ながら、ディザスター リカバリー プロセスの一部は人間による介入が必要になるため、プロセスを完全に文書化する必要があります。 また、回復プロセスを有効に保つために、障害を定期的にシミュレートする必要があります。
主要な関係者とインフラストラクチャを特定する
アプリケーションを機能し続けるために必要な関係するすべてのユーザーを特定します。 これらの利害関係者は、外部ユーザーでも内部ユーザーでもかまいません。 サポート スタッフや BCDR プロセスに介入する必要があるユーザーは、関係者です。 アプリケーションに依存する他のアプリケーションやサービスも、関係者になることがあります。
アプリケーションの環境を構築するインフラストラクチャを特定します。 このインフラストラクチャは、通常、仮想マシン (VM)、ネットワーク リソース、ストレージ リソース、および一緒に実行されるその他のサービスです。
回復ポイントの目標と目標復旧時間を特定する
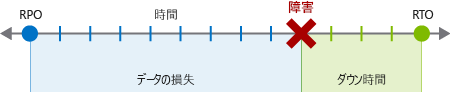
RPO とは、障害が発生した場合にアプリケーションで許容できるデータ損失量を意味します。 たとえば、アプリケーションがダウンしている場合は、実行に使用できるのは復旧後 30 分以内のデータしか許容できない場合があります。 一部のアプリケーションは古いデータでも機能しますが、その他のアプリケーションでは、可能な限り最新のデータで実行することが重要です。
RTO は、アプリケーションで許容されるダウンタイムの最大時間です。 たとえば、営業上の損失を踏まえ、4 時間以上アプリケーションがダウンすることが許容されない場合があります。 重要なアプリケーションの RTO は、より短くする必要があります。
契約または規制の要件は、多くの場合、アプリケーションの RPO と RTO に影響を与える可能性があります。 RPO と RTO は、アプリケーションごとに異なる場合もあります。 重要度の低いアプリケーションでは、RPO と RTO の値が大きくなることがありますが、ビジネスに不可欠なアプリケーションの場合、ダウンタイムとデータ損失の許容範囲は小さくなります。 組織で想定しているデータの損失とダウンタイムによって発生するリスクと発生するコストに応じて RTO と RPO を計算します。
PaaS の要件を特定する
独自で管理するアプリケーションのダウンタイムと復旧を制御することはできますが、PaaS サービスに対しては同様の制御を行えない場合があります。 使用する PaaS サービスには、BCDR プランで考慮する必要がある独自の可用性の保証と復旧計画が含まれる場合があります。
依存しているサービスを特定してインベントリを作成し、その復旧機能を BCDR プランに組み込むことができます。 関連する要件とそれらがどのように BCDR プロセスに影響するかを理解しておくことが重要です。
Azure Site Recovery
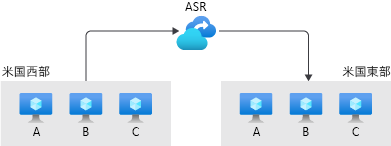
Azure Site Recovery は、Azure、オンプレミス、および他のクラウド プロバイダーのアプリケーション向けの BCDR 機能を提供するサービスです。 Site Recovery には、ディザスター リカバリーの自動化に役立つ計画があります。 これにより、マシンのフェールオーバーの方法や、フェールオーバー成功後の再起動の順序を定義できます。 これにより、Site Recovery はタスクを自動化し、RTO をさらに短縮することができます。 また、Site Recovery を使用して、フェールオーバーと回復プロセスの全体的な有効性を定期的にテストすることができます。
データのバックアップ
バックアップは、アプリケーションを誤って削除したり、データが破損したりすることを防ぐのに役立ちます。 バックアップは、どの BCDR プランでも重要な役割を果たします。
RPO は、バックアップ プロセスをどの頻度で定期的に実行するかによって異なります。 たとえば、2 時間ごとにバックアップ プロセスが実行されるように構成されていて、次のバックアップの 5 分前に障害が発生した場合、1 時間と 55 分のデータが失われます。 バックアップを頻繁に実行すると、RPO が削減されます。 全体的な計画には、詳細なバックアップ プロセスを含める必要があります。
Azure Backup をバックアップ プロセスに使用することができます。 Azure Backup は、Azure で管理されるすべてのデータ資産に対して安全なバックアップを提供するサービスです。 これは、ゼロインフラストラクチャ ソリューションを使用して、セルフサービスのバックアップと復元を可能にします。大規模な管理が予測可能なコストで実現します。
Azure Backup では Azure とオンプレミスの VM の専用バックアップ ソリューションが提供されています。 また、Azure Backup を使うと、Azure VM で実行されている SQL Server や SAP HANA などのワークロードで、エンタープライズクラスのバックアップと復元のオプションを使用できます。
Azure Backup と Azure Site Recovery はどちらも、障害や失敗に対してシステムの回復力を高めることを目的としています。 ただし、Azure Backup の主な目的は、迅速に復旧できるようにステートフルなデータのコピーを維持することです。 Site Recovery は、ほぼリアルタイムでデータをレプリケートし、フェールオーバーを可能にします。 Azure Backup の詳細を表示します。
Azure の復元機能
Azure には、アプリケーションとインフラストラクチャを確実に回復できるようにするのに役立つ機能が用意されています。
リージョンのペアリング
すべての Azure リージョンは、別のリージョンとペアになっています。 リージョンのペアでは、リージョンが同時に更新されることはありません。 そうではなく、1 つずつ更新されます。 あるリージョンで何らかの問題が発生した場合は、もう一方にアクセスできるようになります。
これらのリージョンのペアは、レプリケーションにも使用されます。 ストレージ サービスと多くの PaaS サービスはレプリケートされ、ペアになっているリージョンに、フェールオーバーした際に使用するペアが置かれています。 BCDR 計画の一環として、リージョンのペアを使い、その分離を利用することが重要です。 障害からの復旧にかかる時間を短縮し、可用性を高めることができます。
可用性セット
可用性セットは、Azure の論理グループ化機能です。 これにより、Azure データセンター内にデプロイされるときに、その中に配置された VM リソースが互いに分離されます。 可用性セットは、"更新ドメイン" と "障害ドメイン" で構成されています。
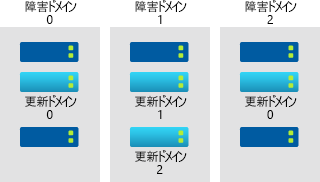
Azure データセンター内の VM ホストがメンテナンスのためにダウンタイムを必要とする場合でも、更新ドメインにより、アプリケーションのサーバーのサブセットは実行状態を確実に維持できるようになります。 VM ホストに対するほとんどの更新は、実行されている VM に影響を与えることなく実行できますが、この種類の更新が実行できない場合があります。
更新プログラムがすべての VM に対して同時に実行されないようにするために、Azure データ センターは論理的に更新ドメインに区分されています。 パフォーマンス更新プログラムやホストに適用する必要がある重要なセキュリティ パッチなどのメンテナンス イベントが発生した場合は、更新ドメインを経由してシーケンス処理されます。 更新ドメインを経由したシーケンス処理により、プラットフォームの更新中およびパッチ適用中もデータセンター全体が利用できなくなることはありません。
障害ドメインはデータセンターの物理的なセクションを表し、これにより可用性セット内でのサーバーのラック多様性の確保に役立ちます。 障害ドメインは、データセンター内の共有ハードウェアの物理的な分離に合わせて整列されます。 共有ハードウェアには、サーバー ラック上の物理サーバーをサポートする電源、冷却装置、およびネットワーク ハードウェアが含まれます。
あるサーバー ラックをサポートするハードウェアが使用できなくなっても、その停止の影響を受けるのは、そのサーバー ラックのみです。 可用性セットに VM を配置すると、それらは複数の障害ドメインに自動的に分散されます。 ハードウェア障害が発生した場合、影響を受けるのは一部の VM のみです。
可用性ゾーン
可用性ゾーンは、リージョン内にある独立した物理的なデータセンターの場所です。 独自の電源、冷却装置、ネットワークを備えています。 リソースのデプロイ時に可用性ゾーンを考慮に入れると、リージョンでのプレゼンスを維持しながら、データセンターの停止からワークロードを保護するのに役立ちます。
"ゾーン サービス" は、リージョン内の特定のゾーンにデプロイできるサービス (仮想マシンなど) です。 他のサービスは ''ゾーン冗長サービス'' であり、特定の Azure リージョン内の複数の可用性ゾーンにわたってレプリケートされます。 どちらの種類も、Azure リージョン内で単一障害ポイントが発生しないようにするのに役立ちます。