データ インジェスト パイプラインを調べる
大規模なデータ ウェアハウス ソリューションのアーキテクチャと、大量のデータを処理するために使用できる分散処理テクノロジについて少し理解できたので、次に、1 つ以上のソースから分析データ ストアにデータが取り込まれる方法を調べます。
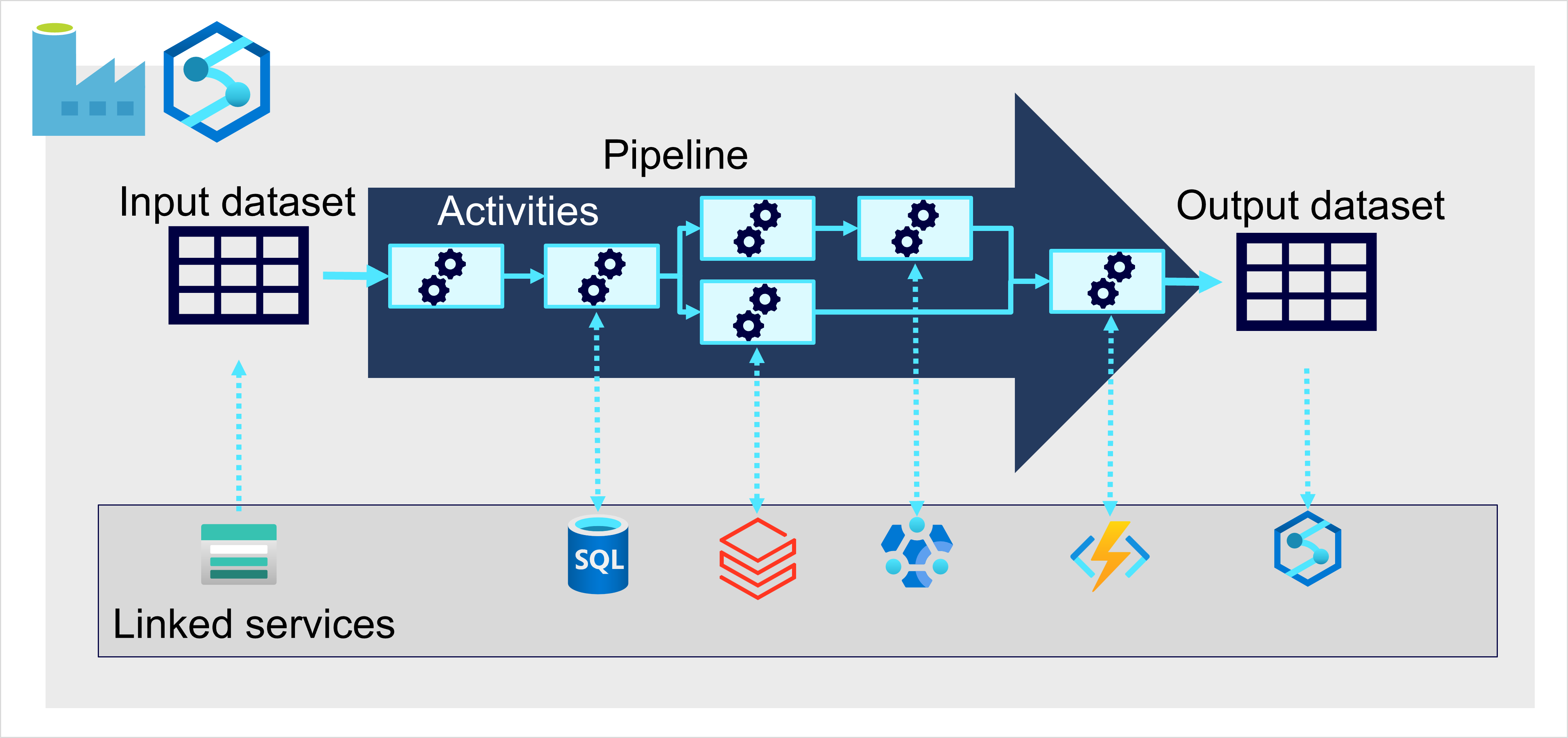
Azure で、大規模なデータ インジェストに最適な実装は、ETL プロセスを調整する "パイプライン" を作成することです。 Azure Data Factory を使って、パイプラインを作成して実行できます。または、統合ワークスペースでデータ分析ソリューションのすべてのコンポーネントを管理する場合は、Azure Synapse Analytics または Microsoft Fabric で同様のパイプライン エンジンを使用できます。
どちらの場合も、パイプラインはデータを操作する 1 つ以上の "アクティビティ" で構成されます。 入力データセットはソース データを提供し、アクティビティは、出力データセットが生成されるまでデータを増分的に操作するデータ フローとして定義できます。 パイプラインから外部データ ソースに接続して、さまざまなデータ サービスと統合できます。