正規化とは
データベースの正規化とは、データ セットをデータベース内のテーブルと列に整理するために使用する設計プロセスです。 それぞれのテーブルには特定の "事物" に関するデータが入っており、かつ、各テーブル内のデータはその特定の "事物" を裏付けるものであることが理想です。 このプロセスの目的は、データベースの中のデータの重複を減らし、データベースの挿入と更新のパフォーマンス低下を軽減することにあります。 たとえば、顧客の住所の変更は、顧客の住所が格納されている場所が顧客テーブルのみの場合、実装がはるかに簡単になります。 正規形として特によく知られているのが、第 1 正規形、第 2 正規形、第 3 正規形です。以下では、この 3 つについて説明します。
第 1 正規形
第 1 正規形は、次の条件を満たす形式です。
- 関連性のあるデータのセットごとに個別のテーブルを作成している
- 個々のテーブルで繰り返し出てくる部分を排除している
- 関連性のあるデータのセットがそれぞれ、主キーにより特定される
このモデルでは、似たようなデータを格納する列を 1 つのテーブル内にいくつも設けないようにする必要があります。 たとえば、製品の色が何種類もある場合に、1 行に色の値が異なる列がいくつもあるという状況は望ましくありません。 以下に示した 1 つ目のテーブル (ProductColors) は、第 1 正規形になっていません。色について、値の繰り返しが存在するためです。 色が 1 つだけの製品に、無駄な領域が発生しています。 また、製品の色が 3 種類よりも多かったらどうなるでしょうか? 2 つ目のテーブル (ProductColor) に示したような形に組み替えてやると、色の最大数を固定する必要がなくなります。 第 1 正規形の条件としてはほかにも、テーブルに一意のキーが必要です。一意のキーというのは、行を一意に特定できる値が入った (1 つまたは複数の) 列です。 2 つ目のテーブルの列はどちらも単体では一意ではありませんが、ProductID と Color を組み合わせると一意になります。 複数の列が必要な場合には、複合キーと呼びます。
| ProductID | Color1 | Color2 | Color3 |
|---|---|---|---|
| 1 | [赤] | [緑] | 黄 |
| 2 | 黄 | ||
| 3 | 青 | [赤] | |
| 4 | 青 | ||
| 5 | [赤] |
| ProductID | 色 |
|---|---|
| 1 | [赤] |
| 1 | [緑] |
| 1 | 黄 |
| 2 | 黄 |
| 3 | 青 |
| 3 | [赤] |
| 4 | 青 |
| 5 | [赤] |
3 つ目のテーブル ProductInfo は、各行が特定の製品に対応しており、繰り返し部分がなく、ProductID 列が主キーとなっていることから、第 1 正規形です。
| ProductID | ProductName | 価格 | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | ウィジェット | 15.95 | United States | US |
| 2 | Foop | 41.95 | イギリス | 英国 |
| 3 | Glombit | 49.95 | イギリス | 英国 |
| 4 | Sorfin | 99.99 | フィリピン共和国 | RepPhil |
| 5 | Stem Bolt | 29.95 | United States | US |
第 2 正規形
第 2 正規形は、第 1 正規形に必要な条件を満たしたうえで、さらに次の条件を満たす形式です。
- テーブルに複合キーが存在する場合に、属性がいずれも複合キーに従属している (複合キーの一部だけに従属していてはならない)。
第 2 正規形は、上で 2 番目に示したテーブル ProductColor のように、複合キーのあるテーブルにのみ関係がある概念です。 ProductColor テーブルに製品の価格が含まれていた場合を考えてみましょう。 このテーブルでは、ProductID と Color の 2 列の値を使ってはじめて行を一意に特定できるため、この 2 列から成る複合キーがあることになります。 色が変わっても製品の価格が変わらないとすると、データは次のテーブルに示したようになります。
| ProductID | 色 | 価格 |
|---|---|---|
| 1 | [赤] | 15.95 |
| 1 | [緑] | 15.95 |
| 1 | 黄 | 15.95 |
| 2 | 黄 | 41.95 |
| 3 | 青 | 49.95 |
| 3 | [赤] | 49.95 |
| 4 | 青 | 99.95 |
| 5 | [赤] | 29.95 |
上のテーブルは、第 2 正規形になっていないと言えます。 価格の値が ProductID には従属しているものの、Color には従属していません。 ProductID 1 の行が 3 つあり、製品価格が 3 回繰り返されています。 第 2 正規形に違反することによる問題は、価格の更新が必要になった場合に、全部の場所で更新しなければならなくなるという点です。 最初の行で価格を更新しておきながら、2 行目や 3 行目を更新しなかった場合には、いわゆる "更新不整合" が発生します。 更新後に、ProductID 1 の実際の価格がわからなくなってしまうのです。 対策としては、ProductID が単独の列キーとなっているテーブルに Price 列を移動させることが挙げられます。Price が従属する唯一の列が、ProductID 列であるからです。 たとえば、3 つ目のテーブルに価格を入れておくことが考えられます。
製品の価格がその色に応じて異なる場合には、4 つ目のテーブルは第 2 正規形であると言えます。価格がキーの両方の要素、つまり ProductID と Color に従属するからです。
第 3 正規形
ほとんどの OLTP データベースが通常目指す形が、第 3 正規形です。 第 3 正規形は、第 2 正規形に必要な条件を満たしたうえで、さらに次の条件を満たす形です。
- キー列でない列がいずれも、推移的でない形で主キーに従属している。
推移的なリレーションシップとは、テーブル内のある列が、何か別の列を挟んだうえで、さらに別の列に関係していることを指します。 依存関係とは、依存関係の結果として、列の値を別の列から派生させることができることを意味します。 たとえば、生年月日からは年齢が特定できるので、年齢は生年月日に従属しています。 3 番目のテーブル ProductInfo に戻りましょう。 このテーブルは第 2 正規形ですが、第 3 正規形にはなっていません。 ShortLocation 列が、キーではない ProductionCountry 列に従属しています。 第 3 正規形に違反すると、第 2 正規形と同じように更新不整合が発生する可能性があります。 ある行で ShortLocation を更新したものの、その場所が出てきている行をすべて更新しなかった場合には、データに不整合が発生します。 これを防ぐには、別のテーブルを作成して国や地域の名前とその短縮形を格納できます。
非正規化
第 3 正規形は理論上望ましいものではあるのですが、あらゆるデータで常に実現できるわけではありません。 また、データベースを正規化すれば必ず最善のパフォーマンスが得られるとも限りません。 正規化したデータは、何回か結合操作を経ないと、1 回のクエリの結果を返すのに必要なデータの全部を取得できないことが少なくありません。 データの正規化と非正規化には、トレードオフの関係があります。前者はクエリ結果を返すうえで必要な結合の回数が原因で CPU 使用率が高くなるのに対し、後者は必要な結合回数と CPU 使用率を少なくできるものの、更新不整合のリスクが生じます。
注意
データを非正規化するのは、正規化しないということではありません。 非正規化では、まず正規化したテーブルを設計します。 次に、必要な結合の回数を減らせるよう、いくつかのテーブルに列を追加します。このとき、更新不整合が起こりうる可能性は、きちんと認識しています。 そこで、更新を実施した場合に、重複するデータもすべて更新できるようなトリガーその他の処理を用意するのです。
データ ウェアハウスのように読み取りの負荷が大きなワークロードの場合には特に、データを非正規化するとクエリの効率が良くなることがあります。 そのような場合には、列を追加することによって、もっと優れたクエリ パターンやシンプルなクエリを使えるようになる可能性があるのです。
スター スキーマ
正規化は OLTP ワークロードのために実施するのがほとんどです。これに対して、データ ウェアハウスには独自のモデル構造があります。そして、それは通常、非正規化を使用したモデルです。 この設計では、販売などの特定のイベントに関する測定値やメトリックを記録する "ファクト テーブル" を、"ディメンション テーブル" に結合しています。ディメンション テーブルは、行数という点ではファクト テーブルよりも小規模ですが、ファクト データを説明する列を大量に備えています。 ディメンションの例をいくつか挙げると、在庫、時点、地域などがあります。 この設計パターンを使用する目的は、データベースのクエリを実行しやすくし、読み取りワークロードのパフォーマンスを高めることです。
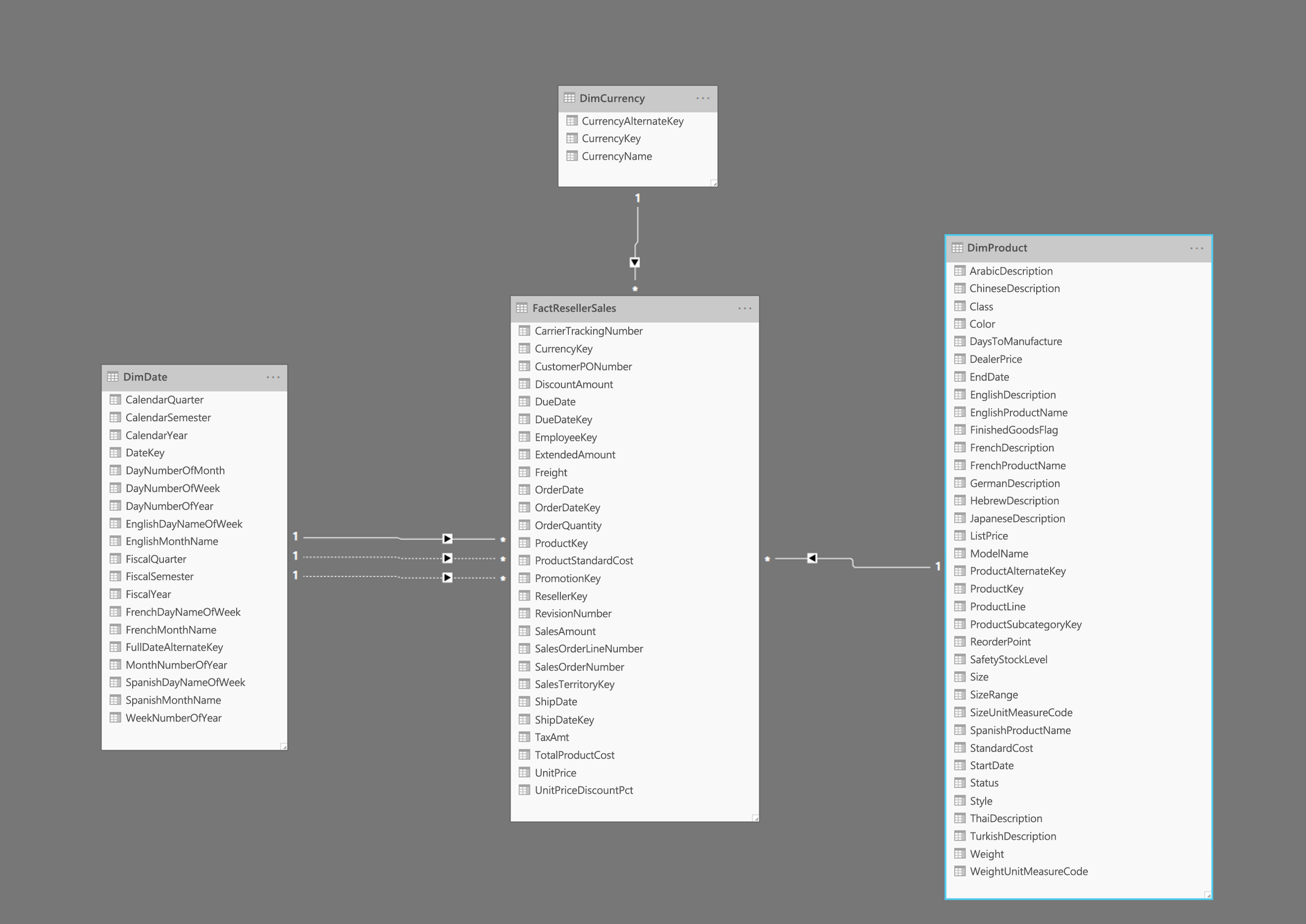
上の画像はスター スキーマの例を示したものです。FactResellerSales というファクト テーブルに加えて、日付、通貨、製品の 3 つのディメンションがあります。 ファクト テーブルには販売取引に関連するデータが、ディメンションには販売データの特定の一要素に関連するデータのみが、それぞれ格納されます。 たとえば、FactResellerSales テーブルには、販売した製品を示す ProductKey だけが入っています。 各製品に関する詳細はすべて DimProduct テーブルにあり、ProductKey 列によりファクト テーブルと関連付けられています。
スター スキーマに関連した設計として、スノーフレーク スキーマがあります。スノーフレーク スキーマでは、1 つのビジネス エンティティに関して、スター スキーマよりも正規化の度合いを強めたテーブルを複数使用します。 次の図は、スノーフレーク スキーマの 1 つのディメンションの例を示したものです。 製品のディメンションが正規化され、DimProductCategory、DimProductSubcategory、DimProduct という 3 つのテーブルに格納されています。
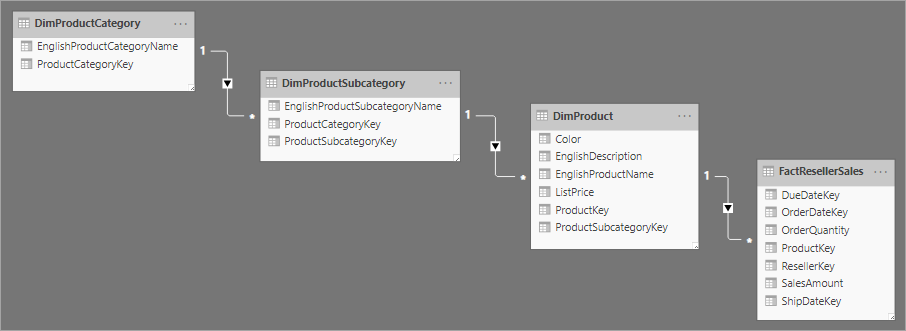
スター スキーマとスノーフレーク スキーマの主な違いは、スノーフレーク スキーマのディメンションは正規化により冗長性が抑えられており、記憶領域を節約できるという点です。 その代わり、クエリで発生する結合回数が多くなるため、複雑さが増し、パフォーマンスが低下する可能性があります。