問題のあるクエリ プランを特定する
DBA がクエリパフォーマンスのトラブルシューティングに使用する一般的なアプローチでは、まず問題のあるクエリを特定し、通常は最も多くのシステム リソースを消費し、その実行プランを取得します。 主に 2 つのシナリオがあります。 1 つのシナリオは、クエリのパフォーマンスが一貫して低下することです。 これは、ハードウェア リソースの制約 (通常は単独で実行される 1 つのクエリには影響しません)、最適でないクエリ構造、データベースの互換性設定、インデックスの不足、クエリ オプティマイザーによるプランの不適切な選択など、さまざまな問題が原因である可能性があります。 2 つ目のシナリオは、一部の実行ではクエリが適切に実行されますが、他の実行ではパフォーマンスが低い場合です。 この不整合は、パラメーター化されたクエリのデータ スキューなどの要因が原因で発生する可能性があります。これは、一部の実行には効率的なプランがあり、他の実行には不適切なプランがあります。 その他の一般的な要因には、ブロック、テーブルへのアクセスを取得するために別のクエリが完了するまでクエリが待機する、ハードウェアの競合などがあります。
これらの各シナリオについて詳しく見ていきましょう。
ハードウェア制約
ハードウェアの制約は通常、1 回のクエリの実行中には現れないが、CPU スレッドとメモリが制限されていると、運用環境の負荷の下で明らかになる。 CPU の競合は、サーバーの CPU 使用率を測定するパフォーマンス モニター カウンター '% プロセッサ時間' を監視することで検出できます。 SQL Server では、 SOS_SCHEDULER_YIELD 待機の種類と CXPACKET 待機の種類が CPU 負荷を示している可能性があります。 ストレージ システムのパフォーマンスが低下すると、最適化された 1 回のクエリ実行でも速度が低下する可能性があります。 記憶域のパフォーマンスは、I/O 操作の完了時間を測定するパフォーマンス モニター カウンター Disk Seconds/Read と Disk Seconds/Writeを使用して、オペレーティング システム レベルで最適に追跡されます。 SQL Server では、I/O に 15 秒を超える時間がかかる場合、ストレージパフォーマンスが低下します。 SQL Server での高 いPAGEIOLATCH_SH 待機は、ストレージのパフォーマンスの問題を示している可能性があります。 通常、ハードウェア パフォーマンスは、評価が容易なため、トラブルシューティング プロセスの早い段階で評価されます。
ほとんどのデータベース パフォーマンスの問題は、最適ではないクエリ パターンに起因し、ハードウェアに過度の負荷をかける可能性があります。 たとえば、インデックスが見つからないと、必要以上に多くのデータを取得することで、CPU、ストレージ、メモリの負荷が発生する可能性があります。 ハードウェアの問題に対処する前に、最適でないクエリに対処して調整することをお勧めします。 次に、クエリのチューニングについて説明します。
最適でないクエリコンストラクト
リレーショナル データベースは、セットでデータ (INSERT、 UPDATE、 DELETE、 SELECT) を操作し、単一の値または結果セットを生成するセット ベースの操作を実行するときに最適に実行されます。 別の方法は、カーソルまたは while ループを使用した行ベースの処理です。これは、影響を受ける行の数に応じてコストを直線的に増加させます。これは、データ ボリュームの増加に伴う問題のあるスケールです。
カーソルまたは WHILE ループを使用した行ベースの操作の最適でない使用を検出することは重要ですが、認識する SQL Server のアンチパターンは他にもあります。 テーブル値関数 (TVF) (特に複数ステートメントの TVF) により、SQL Server 2017 より前に問題のある実行プラン パターンが発生しました。 開発者は、多くの場合、複数ステートメント TVF を使用して 1 つの関数内で複数のクエリを実行し、結果を 1 つのテーブルに集計します。 ただし、TVF を使用すると、パフォーマンスが低下する可能性があります。
SQL Server には、インラインステートメントとマルチステートメントの 2 種類の TVF があります。 インライン TVF はビューのように扱われますが、複数ステートメントの TVF はクエリ処理中にテーブルのように扱われます。 TVF は動的であり、統計がないため、SQL Server では、クエリ プランのコストを見積もるための固定行数が使用されます。 これは行数が少ない場合は問題ありませんが、数千行または数百万行の場合は非効率的です。
もう 1 つのアンチパターンは、同様の推定と実行の問題があるスカラー関数の使用です。 Microsoft は、互換性レベル 140 と 150 の下で、インテリジェント クエリ処理のパフォーマンスを大幅に向上させました。
SARGability
リレーショナル データベースの SARGable という用語は、インデックスを使用してクエリの実行を高速化するために書式設定された述語 (WHERE 句) を指します。 正しい形式の述語は、"検索引数" または SARG と呼ばれます。 SQL Server では、SARG を使用すると、オプティマイザーは、インデックスまたはテーブル全体をスキャンして値を取得するのではなく、 SARG で参照されている列の非クラスター化インデックスを使用して SEEK 操作を評価することを意味します。
SARG が存在しても、SEEK に対するインデックスの使用は保証されません。 オプティマイザーのコスト計算アルゴリズムでは、特に SARG がテーブル内の行の大部分を参照している場合は特に、インデックスのコストが高すぎると判断される可能性があります。 SARG が存在しない場合、オプティマイザーは非クラスター化インデックスの SEEK を評価しないことを意味します。
SARGable 以外の式の例には、文字列の先頭にワイルドカードを使用する LIKE 句 ( WHERE lastName LIKE '%SMITH%'など) が含まれます。 SARGable でない他の述語は、列に対して WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22' などの関数を使用する場合に起こります。 通常、これらのクエリは、シークが発生する必要があるインデックスまたはテーブル スキャンの実行プランを調べることで識別されます。
SARGable以外の関数を使用したクエリと実行プランのスクリーンショット。
City 列には、クエリの WHERE 句で使用されているインデックスがあり、上記のこの実行計画で使用される際に、インデックスがスキャンされていることを確認できます。つまり、インデックス全体が読み込まれています。 述語の LEFT 関数は、この式を非SARGable にします。 オプティマイザーは、City 列のインデックスに対してインデックスシークを用いて評価を行いません。
このクエリは、SARGable である述語を使用するように記述できます。 その後、オプティマイザーはSEEKをCity列のインデックスで評価します。 この場合、インデックス シーク演算子は、より小さな行セットを読み取ります。
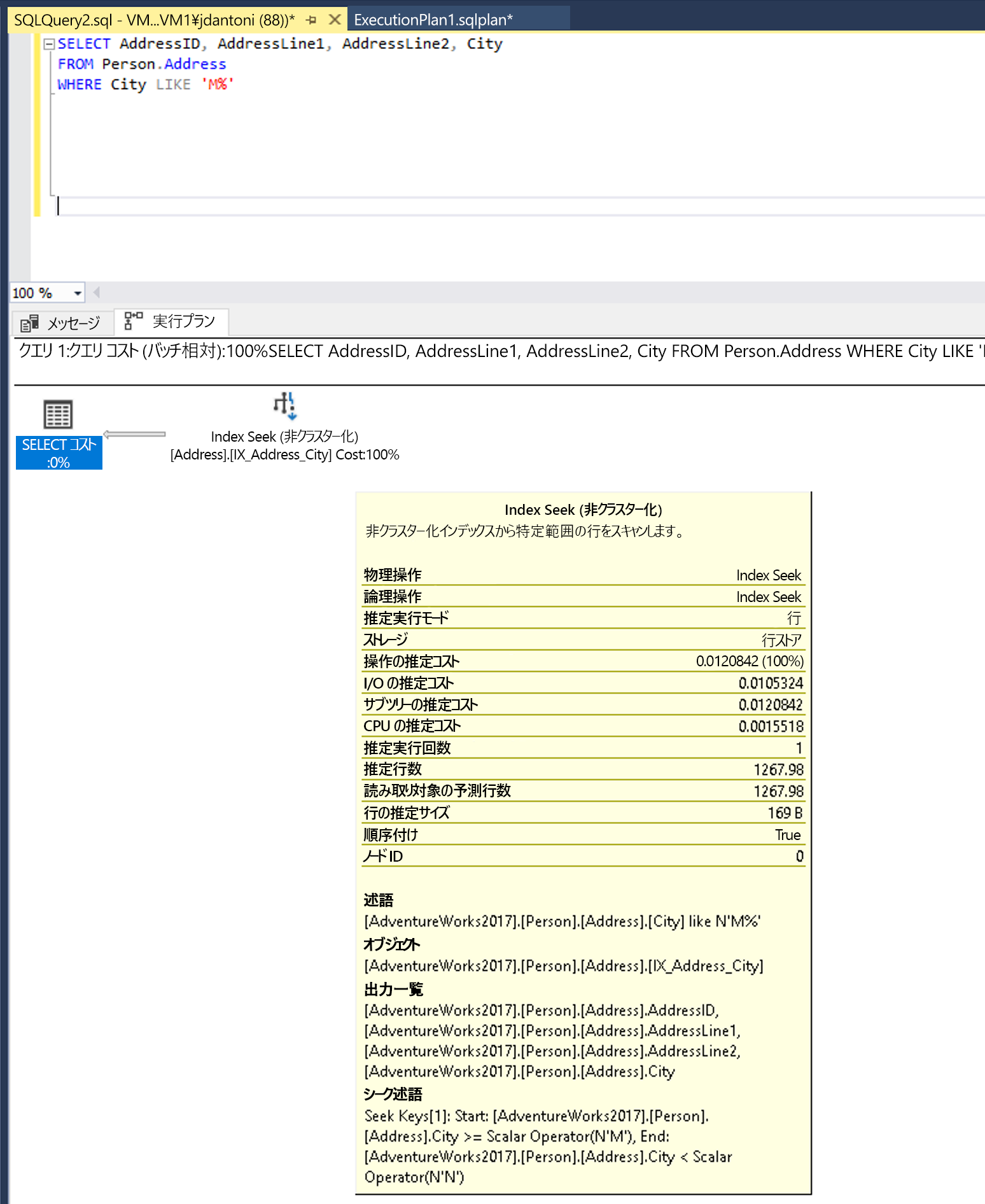
LEFT関数をLIKEに変更すると、インデックスシークが発生します。
注
この例では、LIKE キーワードの左側にはワイルドカードがないため、M で始まる都市が検索されます。これが "両側" の場合、またはワイルドカード ("%M%" または "%M") で始まる場合は、SARGable (検索引数化可能) ではなくなります。 シーク操作は、約1,267行を返すと推定されており、これは非SARGable述語を含むクエリの予測行数の約15%に相当します。
他のデータベース開発のアンチパターンの中には、データベースをデータ ストアではなくサービスとして扱うものもあります。 データベースを使用してデータを JSON に変換したり、文字列を操作したり、複雑な計算を実行したりすると、CPU 使用率が過剰になり、待機時間が長くなる可能性があります。 すべてのレコードを取得し、データベースで計算を実行しようとするクエリは、IO と CPU の過剰な使用につながる可能性があります。 理想的には、データ アクセス操作と、集計などの最適化されたデータベースコンストラクトにデータベースを使用する必要があります。
欠落したインデックス
データベース管理者にとって最も一般的なパフォーマンスの問題は、有用なインデックスがないため、エンジンがクエリ結果を返すために必要以上に多くのページを読み取ることから生じます。 インデックスはリソースを消費します (書き込みパフォーマンスに影響を与え、領域を消費します)、多くの場合、パフォーマンスの向上は追加のリソース コストを上回ります。 これらの問題がある実行プランは、クエリ 演算子 のクラスター化インデックス スキャン 、または 非クラスター化インデックス シーク と キー参照の組み合わせによって識別できます。既存のインデックスに列が見つからない場合を示します。
データベース エンジンは、実行プランで不足しているインデックスを報告するのに役立ちます。 推奨されるインデックスの名前と詳細は、動的管理ビューの sys.dm_db_missing_index_detailsで確認できます。 sys.dm_db_index_usage_statsやsys.dm_db_index_operational_statsなどの他の DMV では、既存のインデックスの使用率が強調表示されます。
未使用のインデックスを削除すると、適切な場合があります。 インデックス DMV とプランの警告が欠落している場合は、クエリをチューニングするための開始点になります。 重要なクエリを理解し、それらをサポートするためのインデックスを作成することが重要です。 不足しているすべてのインデックスをコンテキストで評価せずに作成することはお勧めしません。
不足している統計と古い統計情報
クエリ オプティマイザーに対する列統計とインデックス統計の重要性を理解することは非常に重要です。 また、古い統計につながる可能性がある条件と、この問題が SQL Server でどのように現れるかを認識することも重要です。 Azure SQL オファリングでは、既定で自動更新統計が ON に設定されます。 SQL Server 2016 より前では、自動更新統計の既定の動作では、インデックス内の列に対する変更の数がテーブル内の行数の約 20% になるまで統計を更新しません。 この動作により、統計を更新せずにクエリのパフォーマンスを変更する大幅なデータ変更が発生し、古い統計に基づく最適でないプランになる可能性があります。
SQL Server 2016 より前のバージョンでは、トレース フラグ 2371 を使用して、必要な変更数を動的な値に変更できるため、テーブルが大きくなるにつれて、統計の更新をトリガーするために必要な行の変更の割合が減少しました。 新しいバージョンの SQL Server、Azure SQL Database、および Azure SQL Managed Instance では、既定でこの動作がサポートされています。 動的管理機能 sys.dm_db_stats_properties は、統計が最後に更新された時刻と前回の更新以降の変更の数を示します。これにより、手動更新が必要な統計をすばやく特定できます。
オプティマイザーの選択が不適切
クエリ オプティマイザーは、ほとんどのクエリを最適化する優れたジョブを実行しますが、コストベースのオプティマイザーが完全には理解されていない影響を与える意思決定を行うことができるエッジ ケースがいくつかあります。 安定した最適なクエリ プランに到達するために、クエリ ヒント、トレース フラグ、実行プランの強制、その他の調整の使用など、さまざまな方法で対処できます。 Microsoft には、これらのシナリオのトラブルシューティングに役立つサポート チームがあります。
AdventureWorks2017 データベースの以下の例では、クエリヒントを使用して、データベースオプティマイザーがシアトルという都市名を常に使用するように指示しています。 このヒントでは、すべての市区町村の値に最適な実行プランが保証されるわけではありませんが、予測可能です。 @city_name の 'Seattle' の値は、最適化の際にのみ使用されます。 実行中に、実際に指定された値 (‘Ascheim’) が使用されます。
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
この例に示すように、クエリではヒント (#D0 句) を使用して、特定の変数値を使用してその実行プランを構築するようにオプティマイザーに指示します。
パラメーターのスニッフィング
SQL Server は、今後使用するためにクエリ実行プランをキャッシュします。 実行プランの取得プロセスはクエリのハッシュ値に基づいているため、クエリ テキストは、使用するキャッシュされたプランに対するクエリの実行ごとに同じである必要があります。 同じクエリで複数の値をサポートするために、多くの開発者は、次の例に示すように、ストアド プロシージャを介して渡されるパラメーターを使用します。
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
プロシージャ sp_executesqlを使用して、クエリを明示的にパラメーター化することもできます。 ただし、個々のクエリの明示的なパラメーター化は、 PREPARE と EXECUTE の何らかの形式 (API に応じて) を使用してアプリケーションを通じて行われます。 データベース エンジンは、そのクエリを初めて実行するときに、パラメーターの初期値 (この場合は 42) に基づいてクエリを最適化します。 パラメーター スニッフィングと呼ばれるこの動作により、クエリのコンパイルの全体的なワークロードをサーバー上で削減できます。 ただし、データスキューがある場合、クエリのパフォーマンスは大きく異なる可能性があります。
たとえば、1,000 万個のレコードを含むテーブルと、それらのレコードの 99% の ID は 1 であり、他の 1 つの% は一意の数値であり、パフォーマンスはクエリを最適化するために最初に使用された ID に基づいています。 この大きく変動するパフォーマンスはデータ スキューを示しており、パラメーター スニッフィングに固有の問題ではありません。 この動作は、注意する必要がある、かなり一般的なパフォーマンスの問題です。 問題を軽減するためのオプションを理解する必要があります。 この問題に対処するにはいくつかの方法がありますが、それぞれにトレードオフがあります。
- クエリで
RECOMPILEヒントを使用するか、ストアド プロシージャのWITH RECOMPILE実行オプションを使用します。 このヒントにより、クエリまたはプロシージャが実行されるたびに再コンパイルされます。これにより、サーバーでの CPU 使用率は増加しますが、常に現在のパラメーター値が使用されます。 OPTIMIZE FOR UNKNOWNクエリ ヒントを使用できます。 このヒントにより、オプティマイザーはパラメーターをスニッフィングせず、値を列データ ヒストグラムと比較することを選択します。 このオプションでは、可能な限り最適なプランは得られませんが、一貫した実行プランが可能になります。- 既知の面倒なパラメーターに対してのみ RECOMPILE にパラメーター値に関するロジックを追加して、プロシージャまたはクエリを書き直します。 次の例では、SalesPersonID パラメーターが NULL の場合、クエリは
OPTION (RECOMPILE)で実行されます。
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
この例は適切なソリューションですが、非常に大規模な開発作業と、データ分散に対する十分な理解が必要です。 データの変更に合ったメンテナンスが必要です。