機械学習モデル
注
詳細については、「 テキストと画像 」タブを参照してください。
機械学習は数学と統計に基づいているため、機械学習モデルを数学的に考えるのが一般的です。 基本的に、機械学習モデルは、1 つ以上の入力値に基づいて出力値を計算する 関数 をカプセル化するソフトウェア アプリケーションです。 その関数を定義するプロセスは トレーニングと呼ばれます。 関数が定義されたら、それを使用して推論と呼ばれるプロセスの新しい値 を予測できます。
トレーニングと推論に関連する手順を見てみましょう。
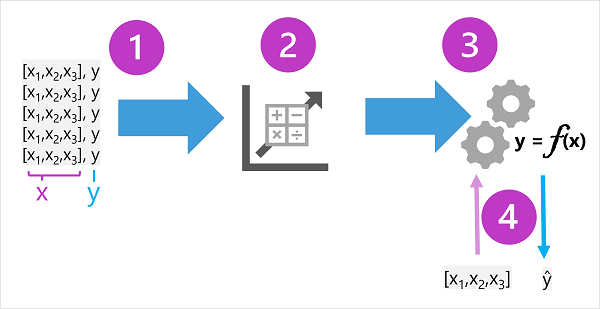
トレーニング データは、過去の観測値で構成されます。 ほとんどの場合、観測には、観察される対象の属性または 特徴 、および予測するモデルをトレーニングする対象の既知の値 ( ラベルと呼ばれます) が含まれます。
数学的な用語では、短縮形変数名 x を使用して参照される特徴と、 y と呼ばれるラベルがよく表示されます。 通常、観測値は複数の特徴値で構成されるため、 x は実際には ベクトル (複数の値を持つ配列) になります (例: [x1,x2,x3,...])。
これを明確にするために、前に説明した例を考えてみましょう。
- アイスクリーム販売シナリオでは、天候に基づいてアイスクリームの販売数を予測できるモデルをトレーニングすることを目標としています。 その日の気象測定値 (温度、降水量、風雨など) は 特徴 (x) になり、毎日販売されるアイスクリームの数は ラベル (y) になります。
- 医療シナリオでは、患者が臨床測定に基づいて糖尿病のリスクがあるかどうかを予測することが目標です。 患者の測定値 (体重、血糖値など) は 特徴 (x) であり、糖尿病の可能性 (たとえば、リスクがある場合は 1 、危険ではない場合は 0 ) は ラベル (y) です。
- 南極の研究シナリオでは、ペンギンの種をその物理的属性に基づいて予測したいと考えています。 ペンギンの主要な測定値 (フリッパーの長さ、くちばしの幅など) は 特徴量 (x) であり、種 (例: Adelie の場合は 0 、Gentoo の場合は 1 、チンストラップの場合は 2 ) は ラベル (y) です。
アルゴリズムがデータに適用され、特徴とラベルの間のリレーションシップを特定し、そのリレーションシップを x に対して実行して y を計算できる計算として一般化します。 使用される特定のアルゴリズムは、解決しようとしている予測問題の種類によって異なりますが (これについては後で詳しく説明します)、基本的な原則は、特徴の値を使用してラベルを計算できる関数にデータを 合わせ ようとすることです。
アルゴリズムの結果は、アルゴリズムによって派生した計算を関数としてカプセル化するモデルです。f と呼びます。 数学表記の場合:
y = f(x)
トレーニング フェーズが完了したら、トレーニング済みのモデルを推論に使用できます。 モデルは基本的に、トレーニング プロセスによって生成される関数をカプセル化するソフトウェア プログラムです。 特徴値のセットを入力し、対応するラベルの予測を出力として受け取ることができます。 モデルからの出力は、観察された値ではなく、関数によって計算された予測であるため、多くの場合、関数からの出力が ŷ ("y-hat" として楽しく言語化されます) と表示されます。