機械学習の種類
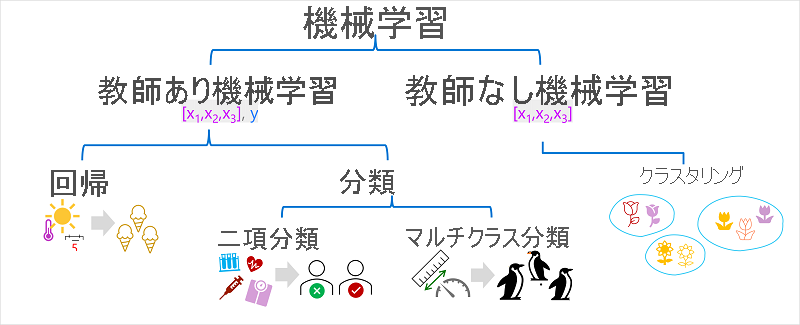
機械学習には複数の種類があり、予測対象に応じて適切な種類を適用する必要があります。 一般的な種類の機械学習の内訳を次の図に示します。
教師あり機械学習
教師あり 機械学習は機械学習アルゴリズムの一般的な用語であり、トレーニング データには 特徴 値と既知の ラベル 値の両方が含まれます。 教師あり機械学習は、過去の観測で特徴とラベルの間の関係を決定することによってモデルをトレーニングするために使用され、将来のケースで特徴の不明なラベルを予測できます。
回帰
回帰 は、モデルによって予測されるラベルが数値である教師あり機械学習の一種です。 例えば次が挙げられます。
- 温度、降水量、風雨に基づいて、特定の日に販売されたアイスクリームの数。
- 平方フィート単位のサイズ、それに含まれる寝室の数、および場所の社会経済的メトリックに基づくプロパティの販売価格。
- エンジンのサイズ、重量、幅、高さ、および長さに基づく自動車の燃費 (1 ガロンあたりマイル単位)。
分類
分類 は、ラベルが分類または クラスを表す教師あり機械学習の形式です。 2 つの一般的な分類シナリオがあります。
二項分類
"二項分類" では、その観測された項目が特定のクラスのインスタンスであるか (または、でないか) が、ラベルによって判断されます。 別の言い方をすると、二項分類モデルは、相互に排他的な 2 つの結果の 1 つを予測します。 例えば次が挙げられます。
- 患者が体重、年齢、血糖値などの臨床指標に基づいて糖尿病のリスクを負うかどうか。
- 銀行のお客様が収入、信用履歴、年齢、その他の要因に基づいてローンをデフォルトにするかどうか。
- メーリング リストの顧客が人口統計属性と過去の購入に基づいてマーケティング オファーに肯定的に応答するかどうか。
これらのすべての例で、モデルは、1 つの可能なクラスに対して 2 項 true/false または 正/負 の予測を予測します。
多クラス分類
多クラス分類 は、二項分類を拡張して、複数の可能なクラスのいずれかを表すラベルを予測します。 たとえば、
- ペンギンの種 (Adelie、 Gentoo、 または Chinstrap) は、物理的な測定値に基づいています。
- キャスト、監督、予算に基づく映画 (コメディ、 恐怖、 ロマンス、 冒険、 またはサイエンス フィクション) のジャンル。
複数のクラスの既知のセットを含むほとんどのシナリオでは、多クラス分類を使用して相互に排他的なラベルを予測します。 たとえば、ペンギンを Gentoo と Adelie の両方にすることはできません。 ただし、 複数ラベル 分類モデルのトレーニングに使用できるアルゴリズムもあります。このアルゴリズムでは、1 つの観測に対して複数の有効なラベルが存在する可能性があります。 たとえば、映画は 、サイエンス フィクション と コメディの両方として分類される可能性があります。
教師なし機械学習
教師なし 機械学習には、既知のラベルのない 特徴 値のみで構成されるデータを使用したモデルのトレーニングが含まれます。 教師なし機械学習アルゴリズムは、トレーニング データ内の観測の特徴間の関係を決定します。
クラスタリング
教師なし機械学習の最も一般的な形式は 、クラスタリングです。 クラスタリング アルゴリズムは、特徴に基づいて観測値間の類似点を識別し、それらを個別のクラスターにグループ化します。 例えば次が挙げられます。
- 大きさ、葉の数、花弁の数に基づいて同様の花をグループ化します。
- 人口統計属性と購入行動に基づいて、類似する顧客のグループを特定します。
クラスタリングは、いくつかの点で多クラス分類に似ています。観測値を個別のグループに分類するという点で、 違いは、分類を使用する場合、トレーニング データ内の観測値が属するクラスが既にわかっているということです。そのため、アルゴリズムは特徴と既知の分類ラベルの間の関係を決定することによって機能します。 クラスタリングでは、以前に知られていたクラスター ラベルはなく、アルゴリズムは特徴の類似性に基づいてデータの観測値をグループ化します。
場合によっては、クラスタリングを使用して、分類モデルをトレーニングする前に存在するクラスのセットを決定します。 たとえば、クラスタリングを使用して顧客をグループに分割し、それらのグループを分析して、顧客のさまざまなクラス (高価値 - 低ボリューム、 頻繁に小規模な購入者など) を特定して分類することができます。 その後、分類を使用してクラスタリング結果の観測値にラベルを付け、ラベル付けされたデータを使用して、新しい顧客が属する可能性のある顧客カテゴリを予測する分類モデルをトレーニングできます。