ディープ ラーニング
注
詳細については、「 テキストと画像 」タブを参照してください。
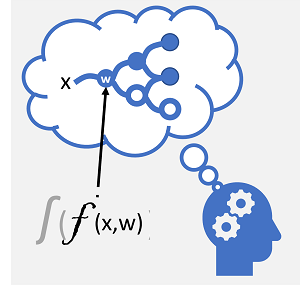
ディープ ラーニング は、人間の脳が学習する方法をエミュレートしようとする高度な機械学習の形式です。 ディープ ラーニングの鍵は、次に示すように、数学関数を使用して生体ニューロンの電気化学活性をシミュレートする人工 ニューラル ネットワーク の作成です。
| 生体ニューラル ネットワーク | 人工ニューラル ネットワーク |
|---|---|

|
|
| 電気化学的刺激に応じてニューロンが発火します。 起動すると、シグナルは接続されたニューロンに渡されます。 | 各ニューロンは、入力値 (x) と 重み (w) で動作する関数です。 この関数は、出力を渡すかどうかを決定する アクティブ化 関数にラップされます。 |
人工ニューラル ネットワークは、ニューロンの複数の 層 で構成され、本質的に深く入れ子になった機能を定義します。 このアーキテクチャは、この手法が ディープ ラーニング と呼ばれる理由であり、そこで生成されるモデルはディープ ニューラル ネットワーク (DNN) と呼ばれることがよくあります。 ディープ ニューラル ネットワークは、回帰や分類など、さまざまな種類の機械学習の問題に対して使用できるほか、自然言語処理やコンピューター ビジョンのためのより特殊なモデルにも使用できます。
このモジュールで説明されている他の機械学習手法と同様に、ディープ ラーニングでは、1 つ以上の特徴 (x) の値に基づいてラベル (y) を予測できる関数にトレーニング データを適合させる必要があります。 関数 (f(x) は、ニューラル ネットワークの各層が x とそれらに関連付けられた重み (w) 値を操作する関数をカプセル化する、入れ子になった関数の外側の層です。 モデルのトレーニングに使用されるアルゴリズムでは、トレーニング データ内の特徴値 (x) をレイヤーを介して繰り返しフィードし 、ŷ の出力値を計算し、計算された ŷ 値が既知の y 値からどれだけ離れているかを評価するモデルを検証します (モデル内の誤差レベルまたは 損失のレベルを定量化します)。 次に、重み (w) を変更して損失を減らします。 トレーニング済みモデルには、最も正確な予測を行う最終的な重み値が含まれます。
例 - ディープ ラーニングを使用した分類
ディープ ニューラル ネットワーク モデルのしくみをより深く理解するために、ペンギン種の分類モデルを定義するためにニューラル ネットワークを使用する例を見てみましょう。
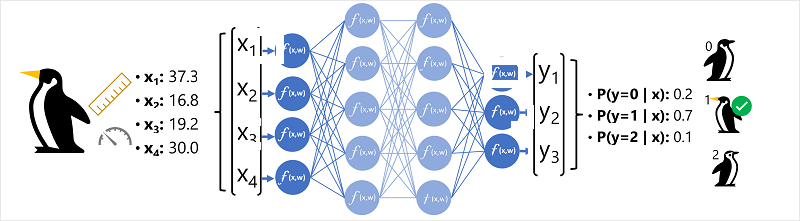
特徴データ (x) は、ペンギンのいくつかの測定値で構成されます。 具体的には、測定値は次のとおりです。
- ペンギンのくちばしの長さ。
- ペンギンのくちばしの深さ。
- ペンギンのフリッパーの長さ。
- ペンギンの体重。
この場合、 x は 4 つの値、つまり数学的には x=[x1,x2,x3,x4] のベクトルです。
予測しようとしているラベル (y) はペンギンの種であり、次の 3 つの種が考えられます。
- Adelie
- "ジェンツーペンギン"
- あご紐
これは分類の問題の例です。機械学習モデルでは、観測が属する最も可能性の高いクラスを予測する必要があります。 分類モデルでは、各クラスの確率で構成されるラベルを予測することによってこれを実現します。 つまり、y は 3 つの確率値のベクトルです。可能なクラスごとに 1 つ: [P(y=0|x),P(y=1|x),P(y=2|x)]。
このネットワークを使用して予測されたペンギン クラスを推論するプロセスは次のとおりです。
- ペンギン観察の特徴ベクトルは 、x 値 ごとにニューロンで構成されるニューラル ネットワークの入力層に供給されます。 この例では、次の x ベクトルが入力として使用されます: [37.3, 16.8, 19.2, 30.0]
- ニューロンの最初の層の関数は、 x 値とw 重みを組み合わせて重み付けされた合計を計算し、次のレイヤーに渡されるしきい値を満たしているかどうかを判断するアクティブ化関数に渡します。
- レイヤー内の各ニューロンは、次の層 ( 完全に接続されたネットワークとも呼ばれるアーキテクチャ) 内のすべてのニューロンに接続されるため、各レイヤーの結果は、出力層に到達するまでネットワークを介して転送されます。
- 出力層は値のベクトルを生成します。この場合、 ソフトマックス または同様の関数を使用して、ペンギンの3つの可能なクラスの確率分布を計算します。 この例では、出力ベクトルは [0.2, 0.7, 0.1] です。
- ベクトルの要素は、クラス 0、1、および 2 の確率を表します。 2 番目の値は最も高いため、モデルではペンギンの種が 1 (Gentoo) であると予測されます。
ニューラル ネットワークはどのように学習しますか?
ニューラル ネットワークの重みは、ラベルの予測値を計算する方法の中心です。 トレーニング プロセス中に、モデルは最も正確な予測をもたらす重みを 学習 します。 この学習がどのように行われるかを理解するために、トレーニング プロセスをもう少し詳しく見てみましょう。
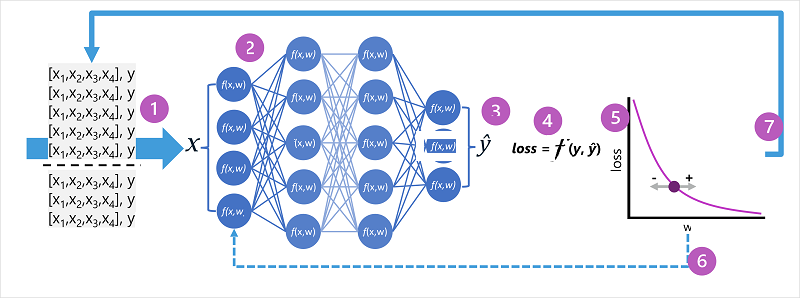
- トレーニングデータセットと検証データセットが定義され、トレーニング機能が入力レイヤーにフィードされます。
- ネットワークの各層のニューロンは、その重み (最初はランダムに割り当てられます) を適用し、ネットワーク経由でデータをフィードします。
- 出力レイヤーは 、ŷ の計算値を含むベクターを生成します。 たとえば、ペンギン クラス予測の出力は [0.3] になります。0.1. 0.6]。
- 損失関数は、予測された ŷ 値を既知の y 値と比較し、差 (損失と呼ばれます) を集計するために使用されます。 たとえば、前の手順で出力を返したケースの既知のクラスが Chinstrap の場合、 y 値は [0.0, 0.0, 1.0] である必要があります。 このベクトルと ŷ ベクトルの絶対差は [0.3, 0.1, 0.4] です。 実際には、損失関数は複数のケースの集計分散を計算し、それを単一 の損失 値として要約します。
- ネットワーク全体は基本的に 1 つの大きな入れ子になった関数であるため、最適化関数は差分微積分を使用して、ネットワーク内の各重みの損失への影響を評価し、全体的な損失の量を減らすために調整する方法 (上下) を決定できます。 特定の最適化手法はさまざまですが、通常は、各重量を増減して損失を最小限に抑える 勾配降下 法が含まれます。
- 重みの変更はネットワーク内のレイヤーに逆伝播され、以前に使用した値が置き換えられる。
- 損失が最小限に抑えられ、モデルが許容可能な精度で予測されるまで、プロセスは複数の反復 ( エポックと呼ばれます) で繰り返されます。
注
トレーニング データが一度に 1 つずつネットワークを通過する場合は、それぞれのケースを考える方が簡単ですが、実際には、データはマトリックスにバッチ処理され、線形代数計算を使用して処理されます。 このため、ニューラル ネットワーク トレーニングは、ベクターとマトリックスの操作用に最適化されたグラフィカル処理ユニット (GPU) を持つコンピューターで最適に実行されます。