Microsoft Fabric を使用してデータを探索および処理する
データは、特に人工知能を実現するための機械学習モデルのトレーニングを目指す場合に、データ サイエンスの基礎となります。 通常、モデルは、トレーニング データセットのサイズが大きくなるにつれてパフォーマンスが向上します。 データの量に加えて、データの品質も同様に重要です。
データの品質と量の両方を保証するには、Microsoft Fabric の堅牢なデータ インジェストエンジンと処理エンジンを使用する価値があります。 重要なデータ インジェスト、探索、および変換パイプラインを確立するときに、低コードまたはコード優先のアプローチを柔軟に選択できます。
Microsoft Fabric にデータを取り込む
Microsoft Fabric でデータを操作するには、まずデータを取り込む必要があります。 ローカル データ ソースとクラウド データ ソースの両方の複数のソースからデータを取り込むことができます。 たとえば、ローカル コンピューターまたは Azure Data Lake Storage (Gen2) に格納されている CSV ファイルからデータを取り込むことができます。
ヒント
Microsoft Fabric を使用して さまざまなソースからデータを取り込み、調整する方法について説明します。
データ ソースに接続した後、データを Microsoft Fabric Lakehouse に保存できます。 レイクハウスを中央の場所として使用して、構造化、半構造化、および非構造化ファイルを格納できます。 その後、探索や変換のためにデータにアクセスする場合は常に、レイクハウスに簡単に接続できます。
データの探索と変換
データ サイエンティストは、 ノートブックでのコードの記述と実行に最も慣れているかもしれません。 Microsoft Fabric は、Spark コンピューティングを利用した使い慣れたノートブック エクスペリエンスを提供します。
Apache Spark は、大規模なデータ処理と分析のためのオープン ソースの並列処理フレームワークです。
ノートブックは Spark コンピューティングに自動的にアタッチされます。 ノートブックでセルを初めて実行すると、新しい Spark セッションが開始されます。 セッションは、後続のセルを実行するときに保持されます。 Spark セッションは、一定時間非アクティブになると自動的に停止し、コストを節約します。 セッションを手動で停止することもできます。
ノートブックで作業している場合は、使用する言語を選択できます。 データ サイエンス ワークロードの場合は、PySpark (Python) または SparkR (R) を使用する可能性があります。
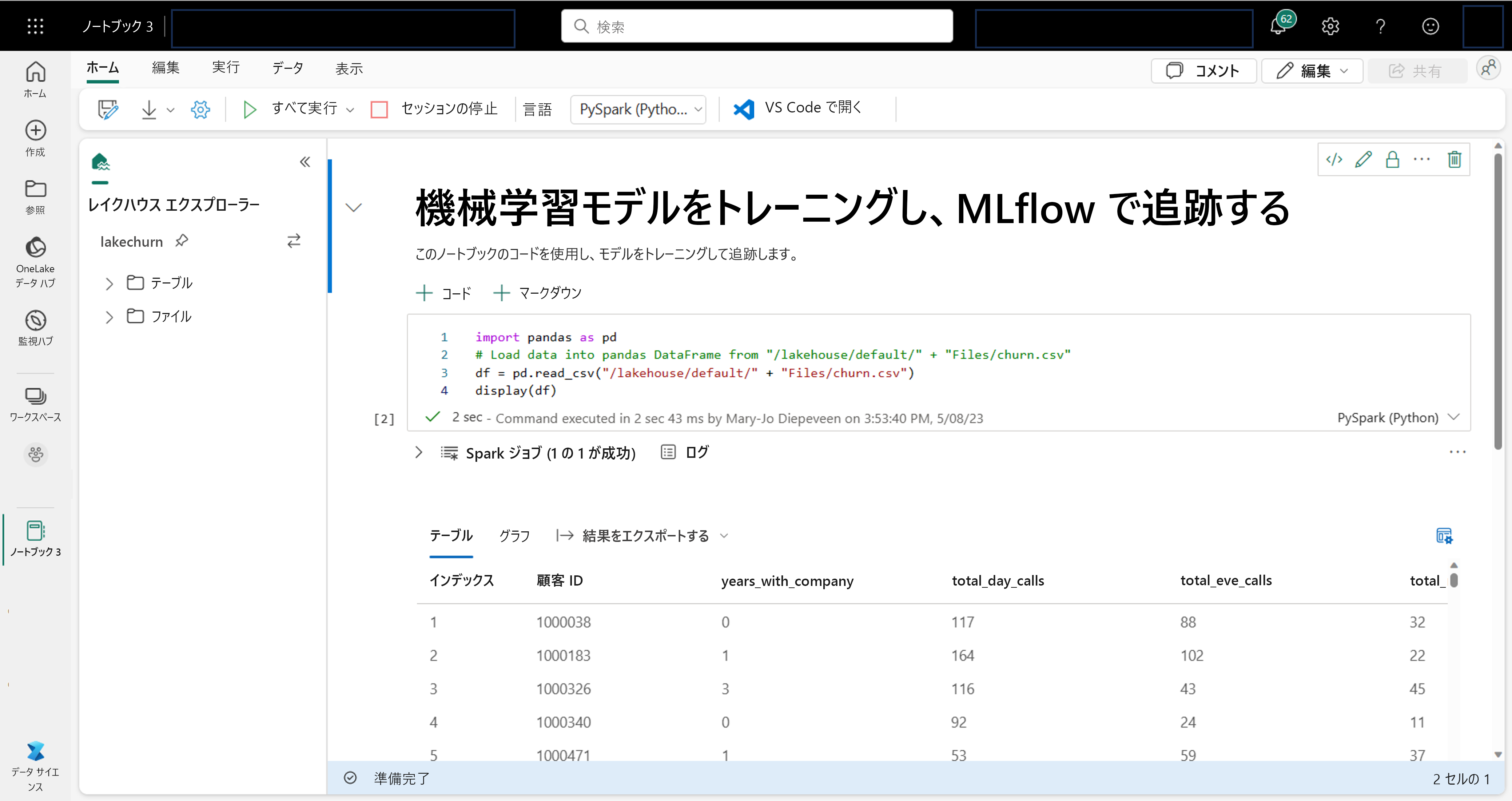
ノートブック内では、任意のライブラリまたは組み込みの視覚化オプションを使用して、データを探索できます。 必要に応じて、データを変換し、処理されたデータを lakehouse に書き戻して保存できます。
Data Wrangler を使用してデータを準備する
データの探索と変換をより迅速に行うために、Microsoft Fabric には使いやすい Data Wrangler が用意されています。
Data Wrangler を起動すると、使用しているデータの概要が説明されます。 データの概要統計を表示して、欠損値などの問題を見つけることができます。
データをクリーンアップするには、組み込みのデータ クリーニング操作のいずれかを選択できます。 操作を選択すると、結果と関連するコードのプレビューが自動的に生成されます。 必要なすべての操作を選択したら、変換をコードにエクスポートし、データに対して実行できます。