HDInsight の構成オプション
HDInsight には、ストリーミング データとバッチ データの両方のシナリオを処理するために使用できるさまざまな OSS テクノロジが組み込まれています。これらは、ラムダ アーキテクチャで定義されている用語です。 このアーキテクチャ モデルでは、データのホット パスとデータのコールド パスがあります。 データのホット パスは、デバイス、センサー、またはアプリケーションによってリアルタイムで生成され、データ分析はほぼリアルタイムで実行されます。これは、ストリーミング データと呼ばれることがよくあります。 コールド データ パスは、データが (通常は他のデータ ストアから) バッチで移動される場合で、バッチ データと呼ばれることがよくあります。
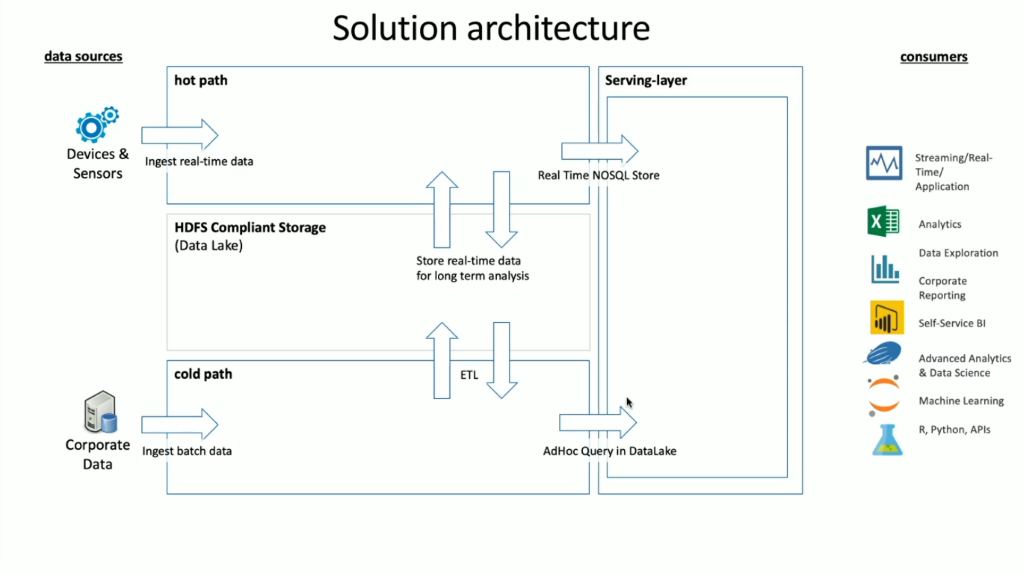
HDInsight を実装するときに、データのストレージは準拠している Hadoop 分散ファイル システム (HDFS) 内に保持されます。 Azure では、Data Lake Gen2 は HDFS に準拠しているため、通常はデータ ストアとして使用されます。 ホット パスとコールド パスからのデータは、処理後にデータ レイクと呼ばれる一元的なデータ ストアに格納されます。 データ レイクそのものをコンパートメント化して、データの状態 (ランディング ゾーン、変換ゾーンなど)、アクセス要件 (ホット、ウォーム、コールド)、およびビジネス グループによって定義できるさまざまなコンパートメントにデータを保持することができます。 サービス レイヤーは、さまざまな種類のコンシューマーが使用できる形式でデータを保持する、データ レイクの最終的なコンパートメントです。
HDInsight のコンピューティングの側面は、ストリーミング データまたはバッチ データの処理に関するもので、HDInsight クラスターのプロビジョニング時に選択したクラスターの種類によって異なる場合があります。 HDInsight では、次の表に示すように、個々のクラスター オプションでサービスを提供しています。
| クラスターの種類 | 説明 |
|---|---|
| Apache Hadoop | HDFS とシンプルな MapReduce プログラミング モデルを使用して、バッチ データを処理および分析するフレームワーク。 |
| Apache Spark | ビッグ データ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする、オープンソースの並列処理フレームワーク。 |
| HBase | Hadoop 上に構築された NoSQL データベース。大量の非構造化データおよび半構造化データ (数十億行 x 数百万列の可能性もある) へのランダム アクセスと厳密な整合性が提供されます。 |
| Apache Interactive Query | 対話型で高速な Hive クエリのメモリ内キャッシュ。 |
| Apache Kafka | ストリーミング データ パイプラインおよびアプリケーションを構築するために使用されるオープンソースのプラットフォームです。 Kafka には、データ ストリームの発行とサブスクライブを可能にするメッセージ キュー機能も用意されています。 |
そのため、解決しようとしているビジネス ケースに合わせて、正しいクラスターの種類を選択することが重要です。 選択されているクラスターの種類に関係なく、次のような追加機能を提供するために、追加のオープンソース コンポーネントもクラスター内に追加されます。
Hadoop 管理
HCatalog - Hadoop のテーブルとストレージの管理レイヤー
Apache Ambari - Apache Hadoop クラスターの管理と監視を容易にする
Apache Oozie - Apache Hadoop ジョブを管理するためのワークフロー スケジューラ システム
Apache Hadoop YARN - リソース管理とジョブのスケジュール設定および監視を管理する
Apache ZooKeeper - 構成情報の保持、名前付け、分散同期の提供、およびグループ サービスの提供を行うための一元化されたサービス
データ処理
Apache Hadoop MapReduce - 膨大な量のデータを処理するアプリケーションを簡単に作成するためのフレームワーク
Apache Tez - データを処理するためのアプリケーション フレームワーク
Apache Hive - SQL を使用して分散ストレージに存在する大規模なデータセットの管理を容易にする
データ分析
Apache Pig - MapReduce の上に大規模なデータセットを分析する抽象化レイヤーを提供する
Apache Phoenix - Hadoop で OLTP と運用分析を有効にする
Apache Mahout - 独自のアルゴリズムを作成するための代数フレームワーク
Note
このドキュメントの作成時点では、Azure Data Lake Gen1 と Azure Blob Storage は、HDInsight のデータ ストレージ層としてサポートされています。 Azure Data Lake Gen2 は、Spark と Hadoop に推奨されるストレージ プラットフォームであり、HBase の既定の選択であるため、このデータをこれに移行することを検討してください。