演習 - Azure Machine Learning のリンクされたサービスを作成する
Synapse Analytics のリンクされたサービスは、サービス プリンシパルを使用して Azure Machine Learning で認証を行います。 サービス プリンシパルは、Azure Synapse Analytics GA Labs という名前の Microsoft Entra アプリケーションに基づいており、既にデプロイ手順によって自動的に作成されています。 また、サービス プリンシパルに関連付けられたシークレットも作成されており、ASA-GA-LABS という名前で Azure Key Vault に保存されています。
Note
この例では、Microsoft Entra アプリケーションを 1 つの Microsoft Entra テナントで使用します。つまり、関連付けられているサービス プリンシパルは 1 つだけです。 そのため、Microsoft Entra アプリケーションとサービス プリンシパルという用語を同じ意味で使用します。 Microsoft Entra アプリケーションとセキュリティ上の原則の詳細については、「Microsoft Entra ID のアプリケーション オブジェクトとサービス プリンシパル オブジェクト」を参照してください。
サービス プリンシパルを表示するには、Azure portal を開き、Microsoft Entra ID のインスタンスに移動します。 [App registrations] (1) セクションを選択すると、[Owned applications] タブの下に Azure Synapse Analytics GA Labs SUFFIX(2) (この例の SUFFIX は 297032 です) アプリケーションが表示されます。
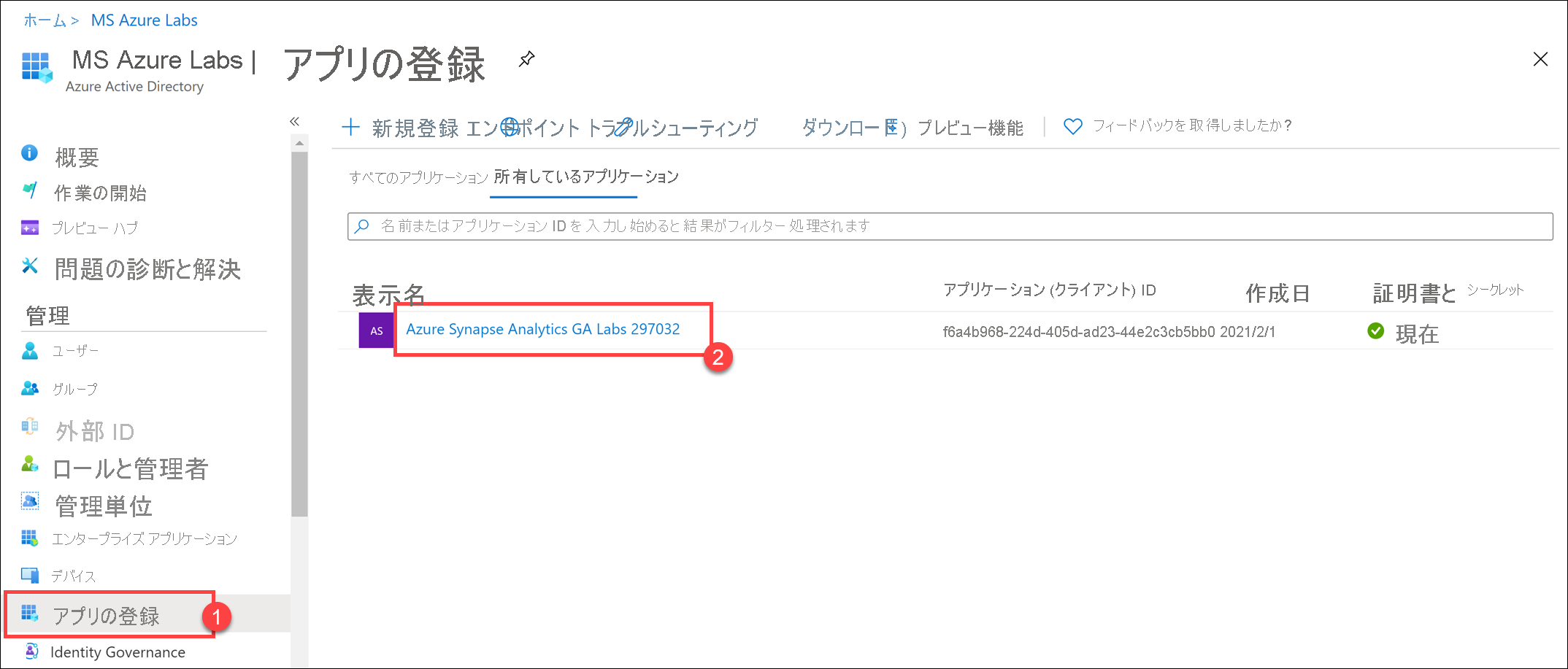
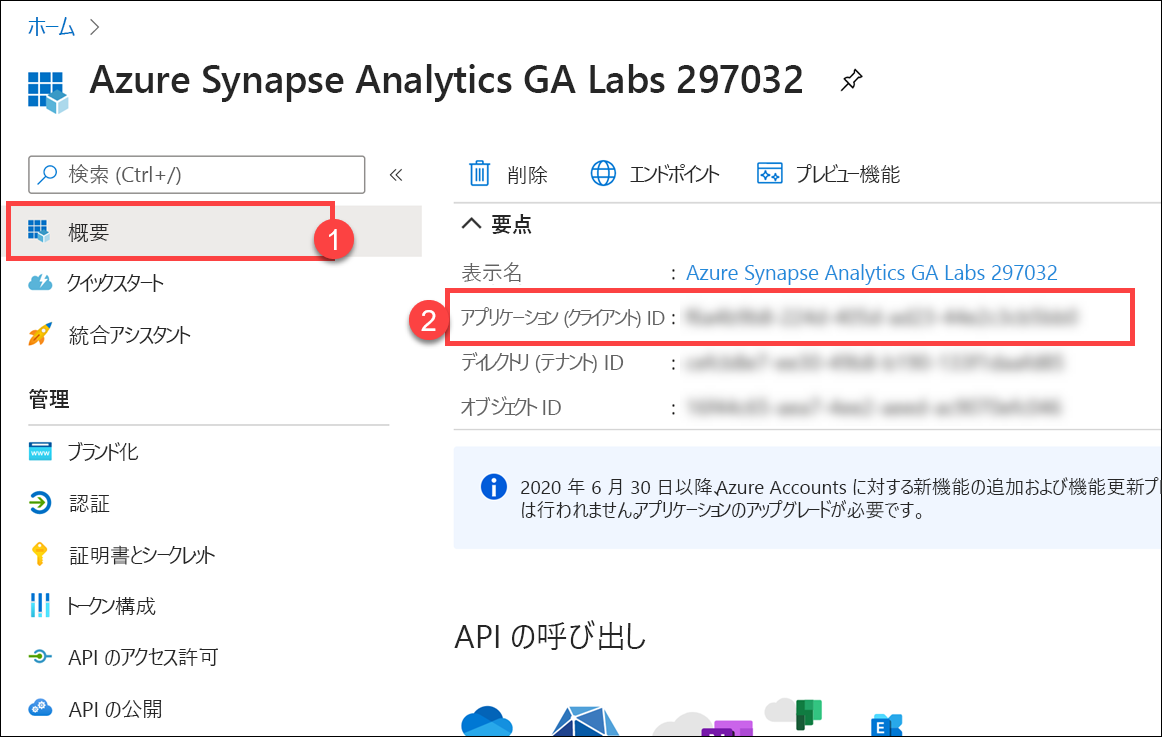
アプリケーションを選択して、そのプロパティを表示し、[Application (client) ID] (2) プロパティの値をコピーします (リンクされたサービスを構成する際に必要になります)。
シークレットを表示するには、Azure portal を開き、ご使用のリソース グループに作成された Azure Key Vault インスタンスに移動します。 [Secrets] (1) セクションを選択すると、ASA-GA-LABS(2) シークレットが表示されます。

最初に、サービス プリンシパルに、Azure Machine Learning ワークスペースを操作するアクセス許可があることを確認する必要があります。 Azure portal を開き、ご使用のリソースグループに作成された Azure Machine Learning ワークスペースに移動します。 左側の [Access control (IAM)] (1) セクションを選択し、[+ Add] (2)、[Add role assignment] の順に選択します。 [Add role assignment] ダイアログで、[Contributor] (3) ロールを選択し、Azure Synapse Analytics GA Labs SUFFIX(4) (ここで、SUFFIX は、ラボのデプロイで使用する一意のサフィックスです) サービス プリンシパルを選択して、[Save] (5) を選択します。

これで、Azure Machine Learning のリンクされたサービスを作成する準備が整いました。
リンクされたサービスを新規作成するには、Synapse ワークスペースを開いて Synapse Studio を開き、[Manage] ハブ (1)、[Linked services] (2)、[+ New] (3) の順に選択します。 [New linked service] ダイアログの検索フィールドに、「Azure Machine Learning」 (4) と入力します。 [Azure Machine Learning] (5) オプション、[Continue] (6) の順に選択します。

[New linked service (Azure Machine Learning)] ダイアログで、次のプロパティを指定します。
- 名前 (1): 「
asagamachinelearning01」と入力します。 - Azure サブスクリプション (2): ご使用のリソース グループを含む Azure サブスクリプションが選択されていることを確認します。
- Azure Machine Learning ワークスペース名 (3): ご使用の Azure Machine Learning ワークスペースが選択されていることを確認します。
- 自動的に入力される
Tenant identifierがどのように入力されているかに注意してください。 - サービス プリンシパル ID (4): 先ほどコピーしたアプリケーションのクライアント ID を入力します。
- [
Azure Key Vault] (5) オプションを選択します。 - AKV のリンクされたサービス (6): Azure Key Vault サービスが選択されていることを確認します。
- シークレット名: 「
ASA-GA-LABS」 (7) と入力します。

次に、[Test connection] (8) を選択して、すべての設定が正しいことを確認し、[Create] (9) を選択します。 以上で、Azure Machine Learning のリンクされたサービスが Synapse Analytics ワークスペースに作成されます。
重要
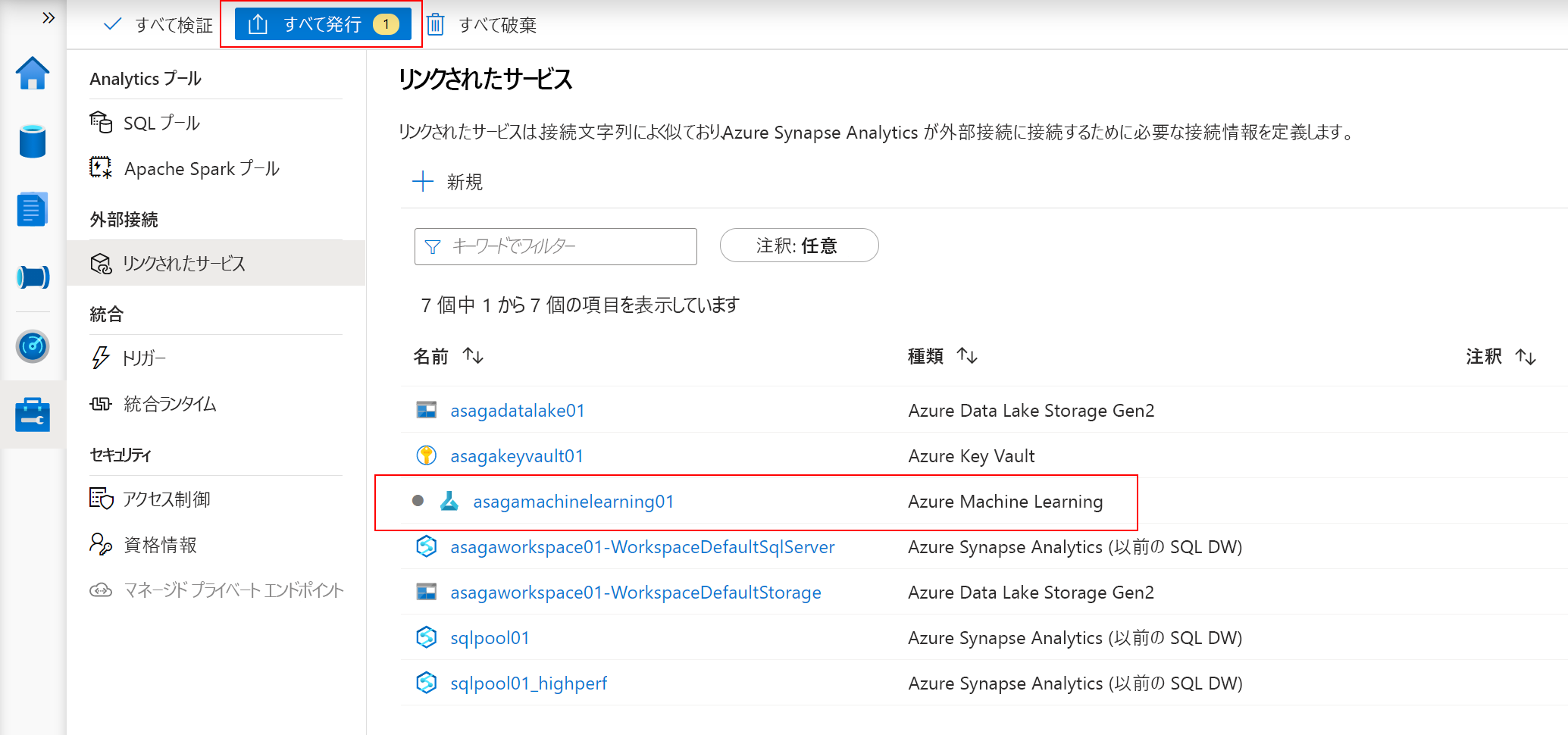
リンクされたサービスは、ワークスペースに発行するまで完了しません。 Azure Machine Learning のリンクされたサービスの近くにあるインジケーターに注意してください。 発行するには、[Publish all]、Publish の順に選択します。
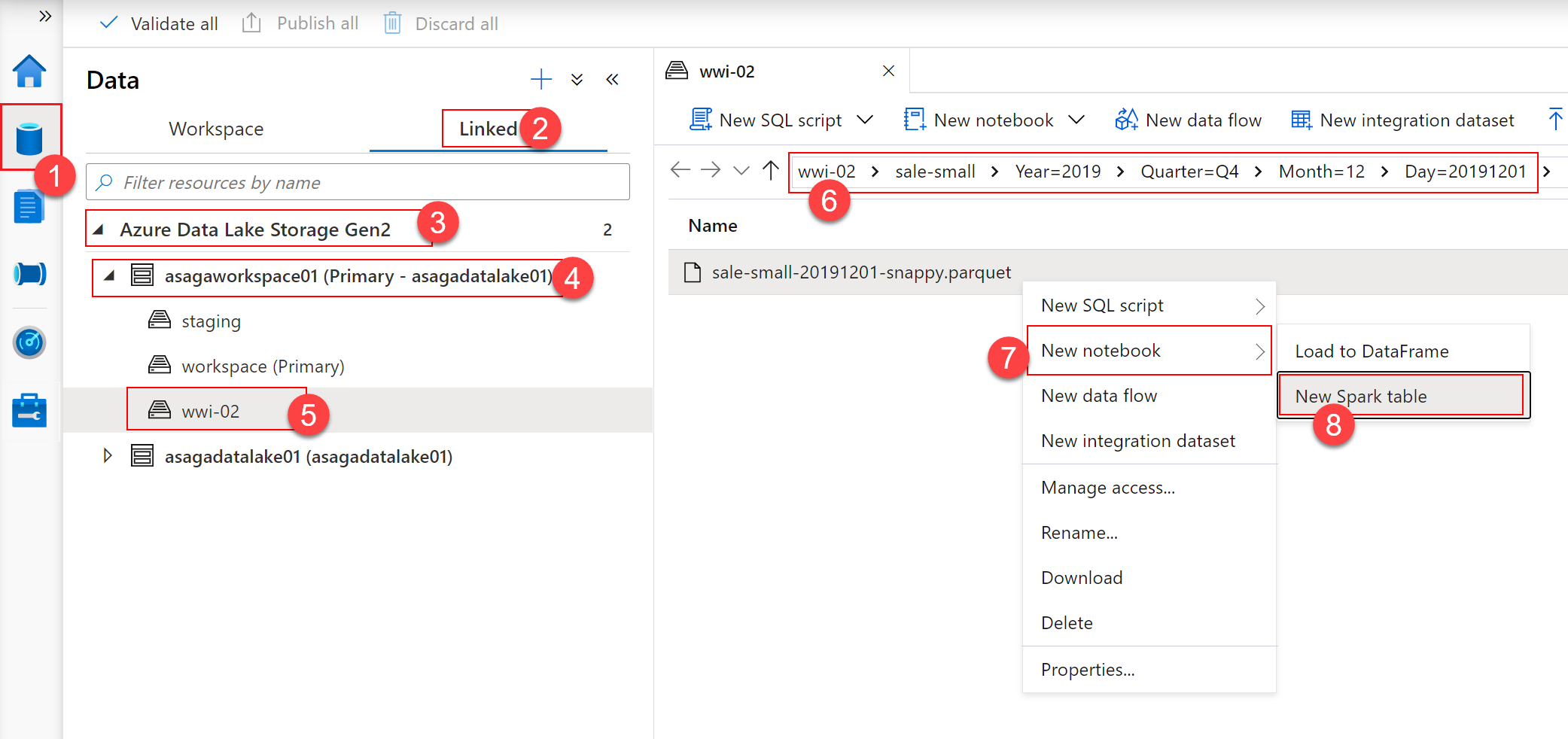
Azure Machine Learning のリソースを Synapse ワークスペースに接続したので、Machine Learning モデルのトレーニング プロセスの開始点として Spark テーブルを作成する必要があります。 Synapse Studio で、[Data] (1) ハブ、[Linked] (2) セクションの順に選択します。 プライマリ Azure Data Lake Storage Gen 2(3) アカウントで、[wwi-02] (5) ファイル システムを選択し、wwi-02\sale-small\Year=2019\Quarter=Q4\Month=12\Day=20191201(6) 下の sale-small-20191201-snappy.parquet ファイルを選択します。 ファイルを右クリックし、[New notebook -> New Spark table] (7-8) を選択します。
ノートブック セルの内容を次のコードに置き換えて、セルを実行します。
import pyspark.sql.functions as f
df = spark.read.load('abfss://wwi-02@<data_lake_account_name>.dfs.core.windows.net/sale-small/Year=2019/Quarter=Q4/Month=12/*/*.parquet',
format='parquet')
df_consolidated = df.groupBy('ProductId', 'TransactionDate', 'Hour').agg(f.sum('Quantity').alias('TotalQuantity'))
df_consolidated.write.mode("overwrite").saveAsTable("default.SaleConsolidated")
注意
<data_lake_account_name> を Synapse Analytics プライマリ データ レイク アカウントの実際の名前に置き換えます。
このコードでは、2019 年 12 月に利用可能なすべてのデータを取得し、それを ProductId、TransactionDate、Hour レベルで集計して、販売された製品数量の合計を TotalQuantity として計算します。 この後、結果は、SaleConsolidated という名前の Spark テーブルとして保存されます。 このテーブルを [Data] ハブに表示するには、[Workspace] (2) セクションの [default (Spark)] (4) データベースを展開します。 テーブルが Tables フォルダーに表示されます。 テーブル名 (5) の右側にある 3 個のドットを選択すると、コンテキスト メニューに [Machine Learning] (6) オプションが表示されます。
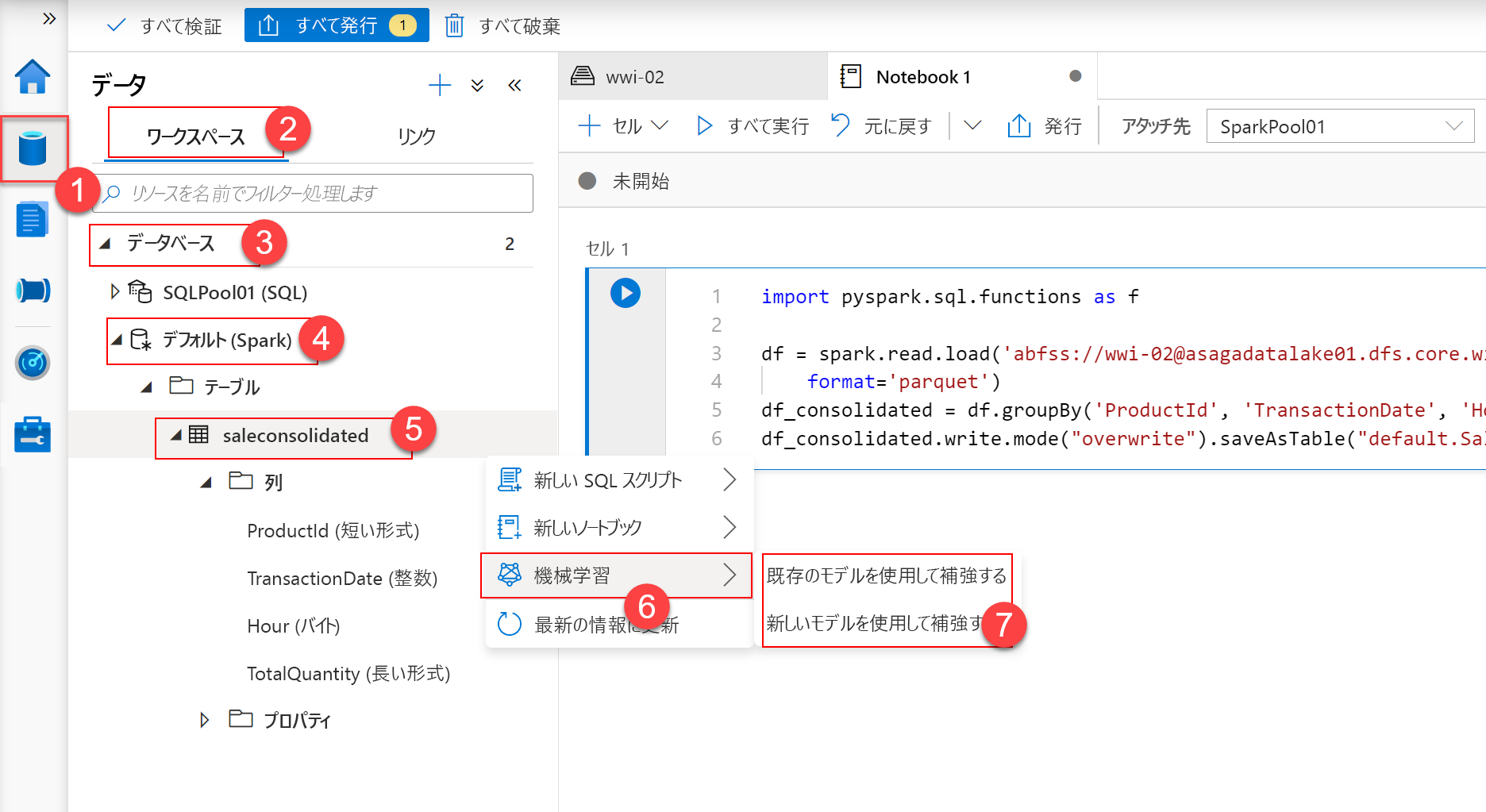
[Machine Learning] (7) セクションでは、次のオプションを使用できます。
- Enrich with a new model(新しいモデルでエンリッチする): 新しいモデルをトレーニングするために AutoML の実験を開始できます。
- Enrich with existing model(既存のモデルでエンリッチする): 現在の Azure Cognitive Services モデルを使用できます。