演習 - PREDICT 関数でトレーニング済みモデルを使用してデータをエンリッチする
この演習では、既存のトレーニング済みモデルを使用してデータに対する予測を実行します。 タスク 1 では、Azure Machine Learning service のトレーニング済みモデルを使用し、タスク 2 では、Azure Cognitive Services のトレーニング済みモデルを使用します。
タスク 1 - Azure Machine Learning service のトレーニング済みモデルを使用して SQL プール テーブルのデータをエンリッチする
Synapse Studio で、[Data] (1) ハブ、[Workspace] (2) タブの順に選択し、SQLPool01 (SQL)(4) データベース (Databases(3) の下) 内の wwi.ProductQuantityForecast(5) テーブルを見つけます。 テーブル名の右側にある [...] (6) を選択してコンテキスト メニューをアクティブにし、[New SQL script > Select TOP 100 rows] を選択します。 表には次の列が含まれています。
- ProductId: 予測する製品の識別子
- TransactionDate: 予測する将来の日付
- Hour: 予測する将来の日付の時間
- TotalQuantity: 指定した製品、日時について予測する値。

すべての行の [TotalQuantity] (7) が 0 であることに注意してください。これは、取得しようとしている予測値のプレースホルダーです。
Azure Machine Learning でトレーニングしたばかりのモデルを使用するには、wwi.ProductQuantityForecastのコンテキスト メニューをアクティブにし、[Machine Learning > Enrich with existing model] を選択します。 これにより、[Enrich with existing model] ダイアログが開き、モデル (1)を選択できます。 最新のモデルを選択し、[Continue] (2) を選択します。
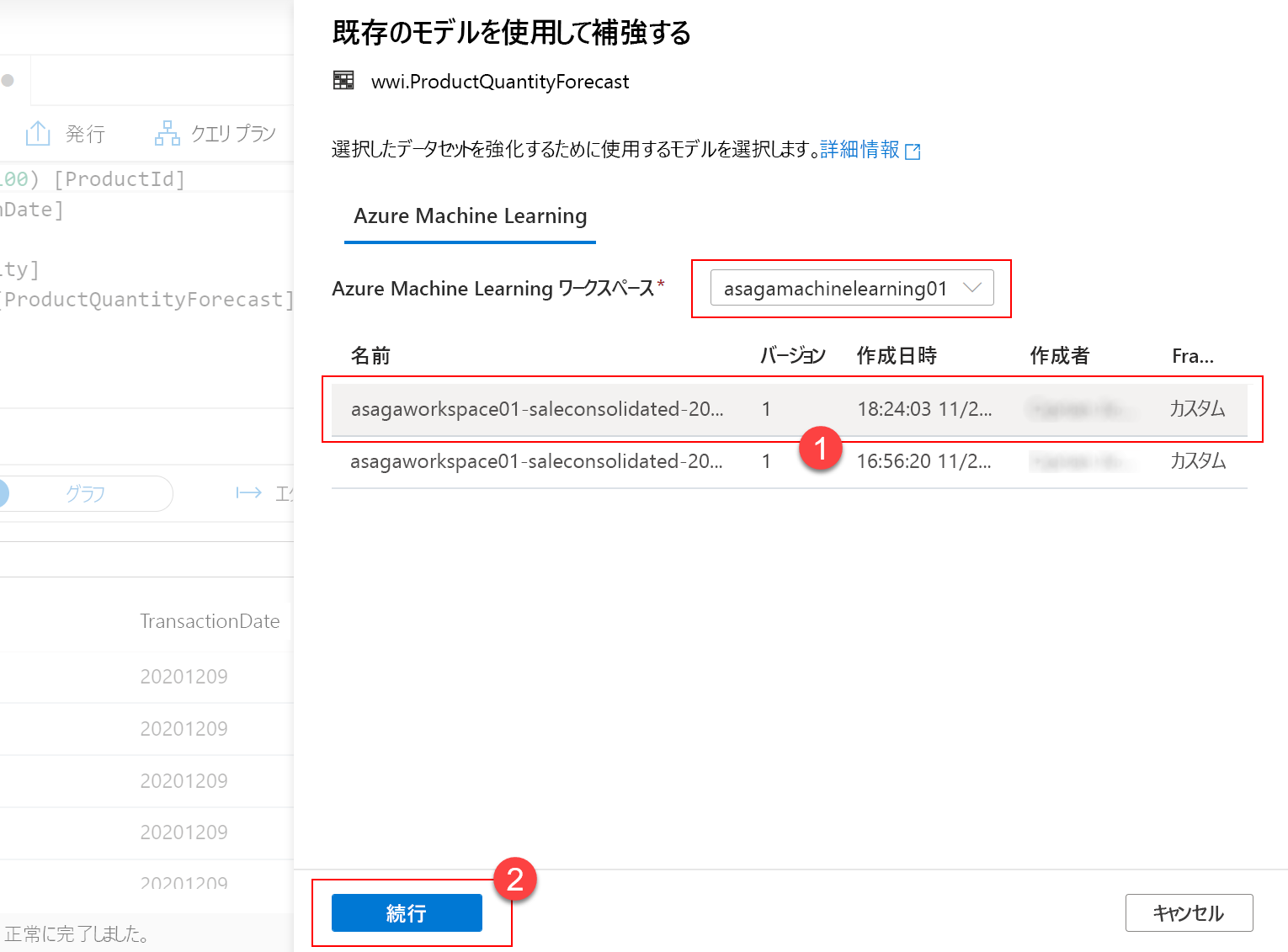
次に、入力列と出力列のマッピングを管理します。 ターゲット テーブルの列名とモデルのトレーニングに使用されるテーブルは一致するため、すべてのマッピングを、提示された既定値のままにしておくことができます。 [Continue] を選択して先に進みます。
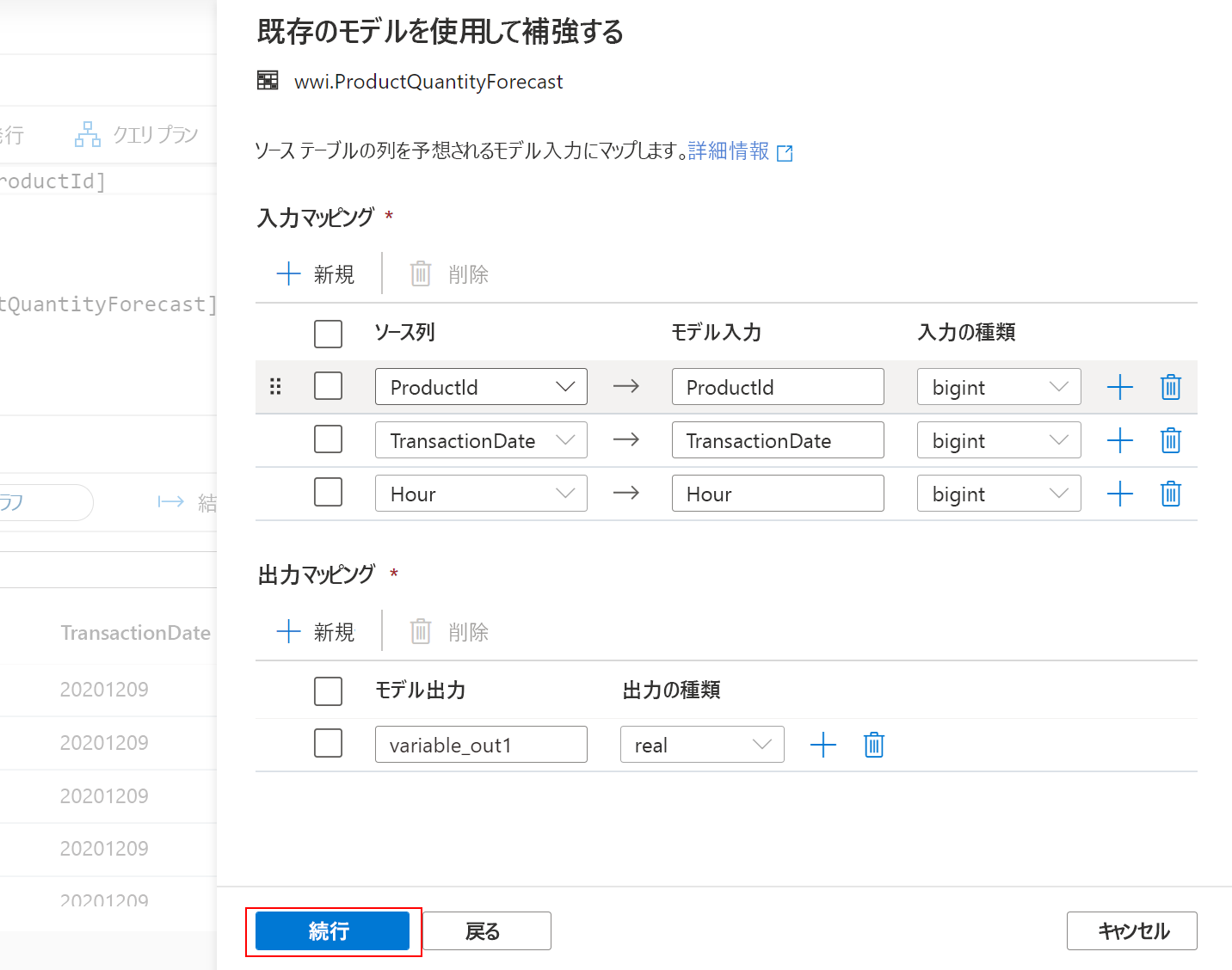
最後の手順では、予測を実行するストアド プロシージャと、モデルのシリアル化された形式を格納するテーブルに名前を付けるオプションが表示されます。 次の値を指定します。
- ストアド プロシージャ名 (1):
[wwi].[ForecastProductQuantity] - ターゲット テーブルの選択:
Create new(2) - 新しいテーブル:
[wwi].[Model](3)
Deploy model + open script(4) を選択して、モデルを SQL プールにデプロイします。
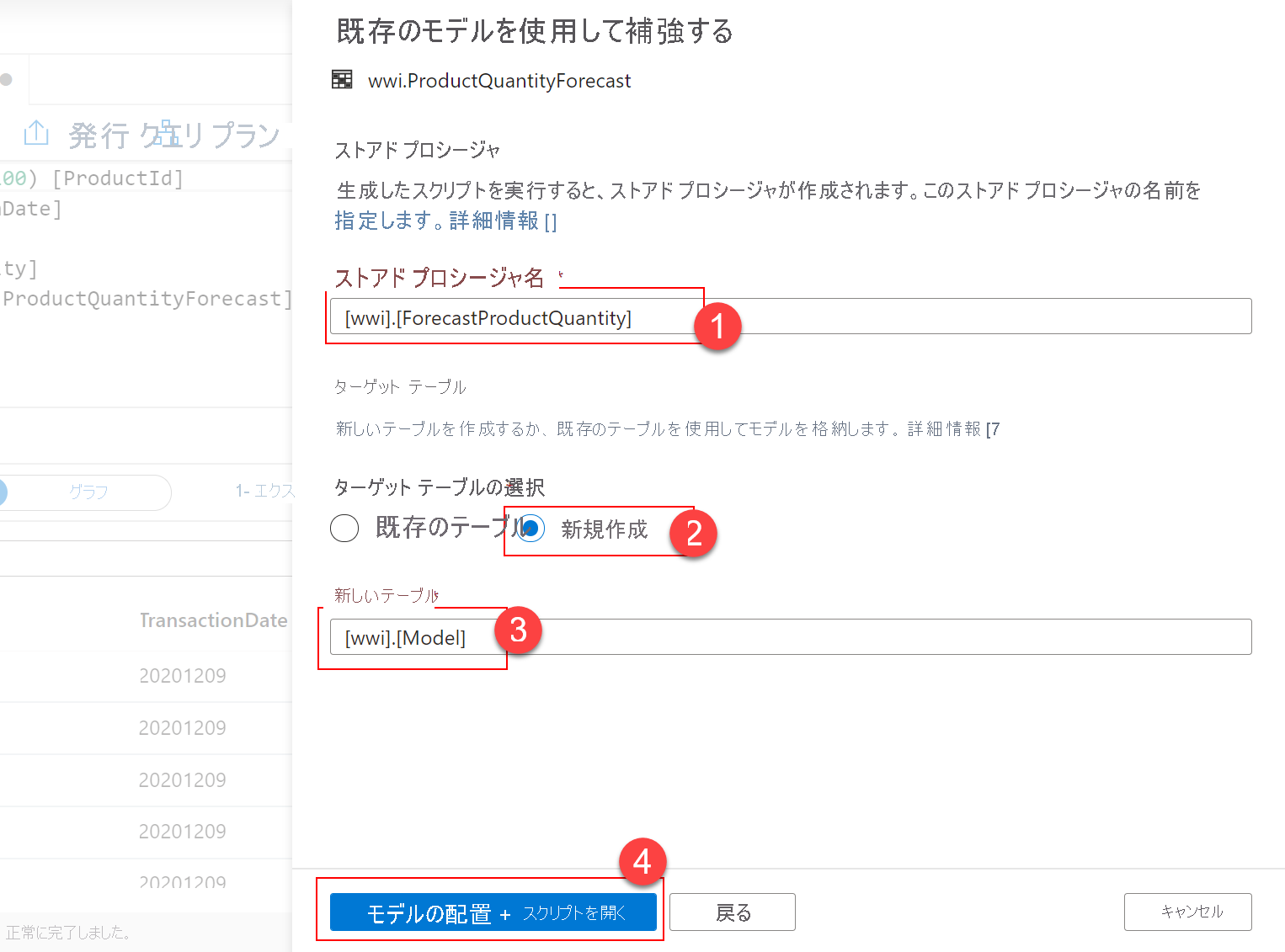
作成された新しい SQL スクリプトから、モデルの ID をコピーします。
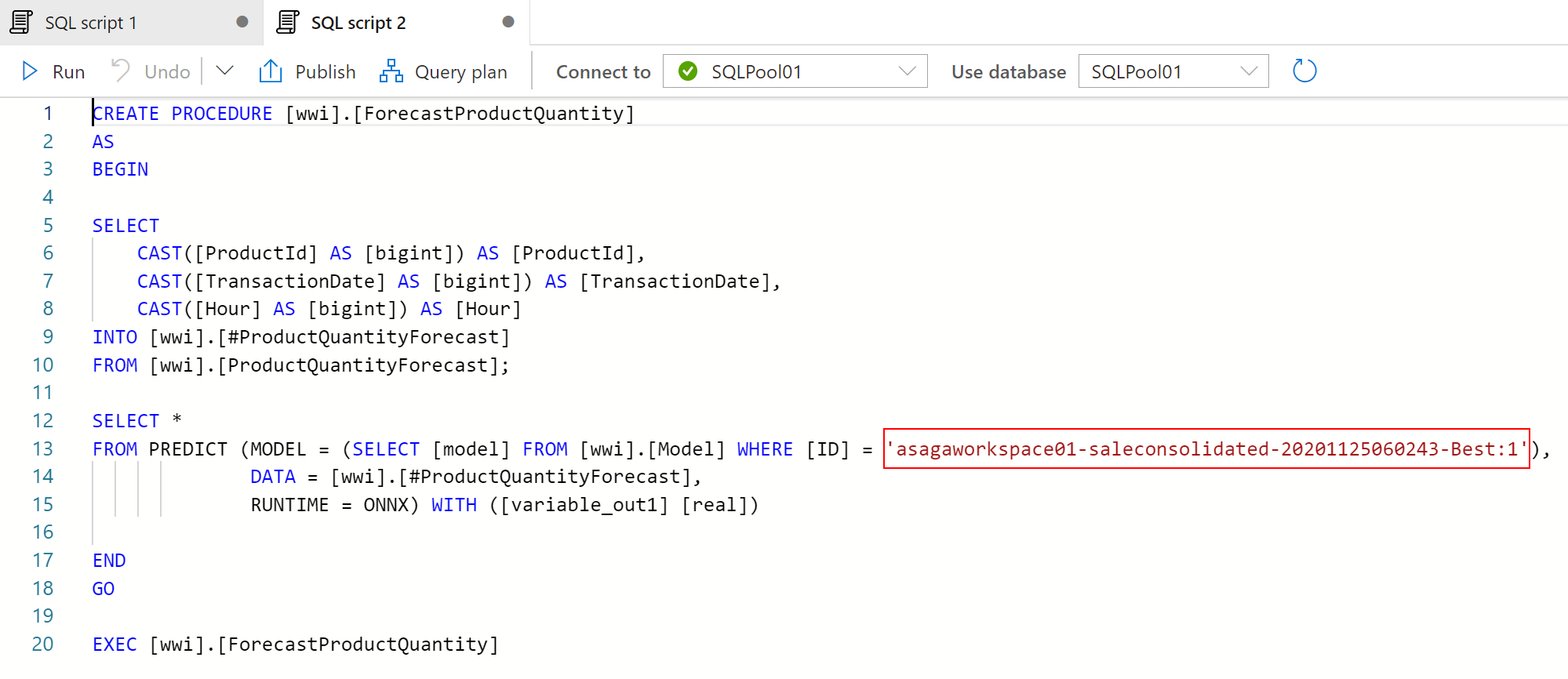
生成された T-SQL コードは、予測の結果を返すだけで、実際に保存しません。 予測の結果を [wwi].[ProductQuantityForecast] テーブルに直接保存するには、生成されたコードを次のコードに置き換えます。
CREATE PROC [wwi].[ForecastProductQuantity] AS
BEGIN
SELECT
CAST([ProductId] AS [bigint]) AS [ProductId],
CAST([TransactionDate] AS [bigint]) AS [TransactionDate],
CAST([Hour] AS [bigint]) AS [Hour]
INTO #ProductQuantityForecast
FROM [wwi].[ProductQuantityForecast]
WHERE TotalQuantity = 0;
SELECT
ProductId
,TransactionDate
,Hour
,CAST(variable_out1 as INT) as TotalQuantity
INTO
#Pred
FROM PREDICT (MODEL = (SELECT [model] FROM wwi.Model WHERE [ID] = '<your_model_id>'),
DATA = #ProductQuantityForecast,
RUNTIME = ONNX) WITH ([variable_out1] [real])
MERGE [wwi].[ProductQuantityForecast] AS target
USING (select * from #Pred) AS source (ProductId, TransactionDate, Hour, TotalQuantity)
ON (target.ProductId = source.ProductId and target.TransactionDate = source.TransactionDate and target.Hour = source.Hour)
WHEN MATCHED THEN
UPDATE SET target.TotalQuantity = source.TotalQuantity;
END
GO
上記のコードでは必ず、<your_model_id> をモデルの実際の ID (前の手順でコピーした ID) に置き換えてください。
注意
このバージョンのストアド プロシージャでは、MERGE コマンドを使用して、wwi.ProductQuantityForecast テーブル内の TotalQuantity フィールドの値をインプレースで更新します。 MERGE コマンドは、最近、Azure Synapse Analytics に追加されました。 詳細については、「Azure Synapse Analytics の新しい MERGE コマンド」を参照してください。
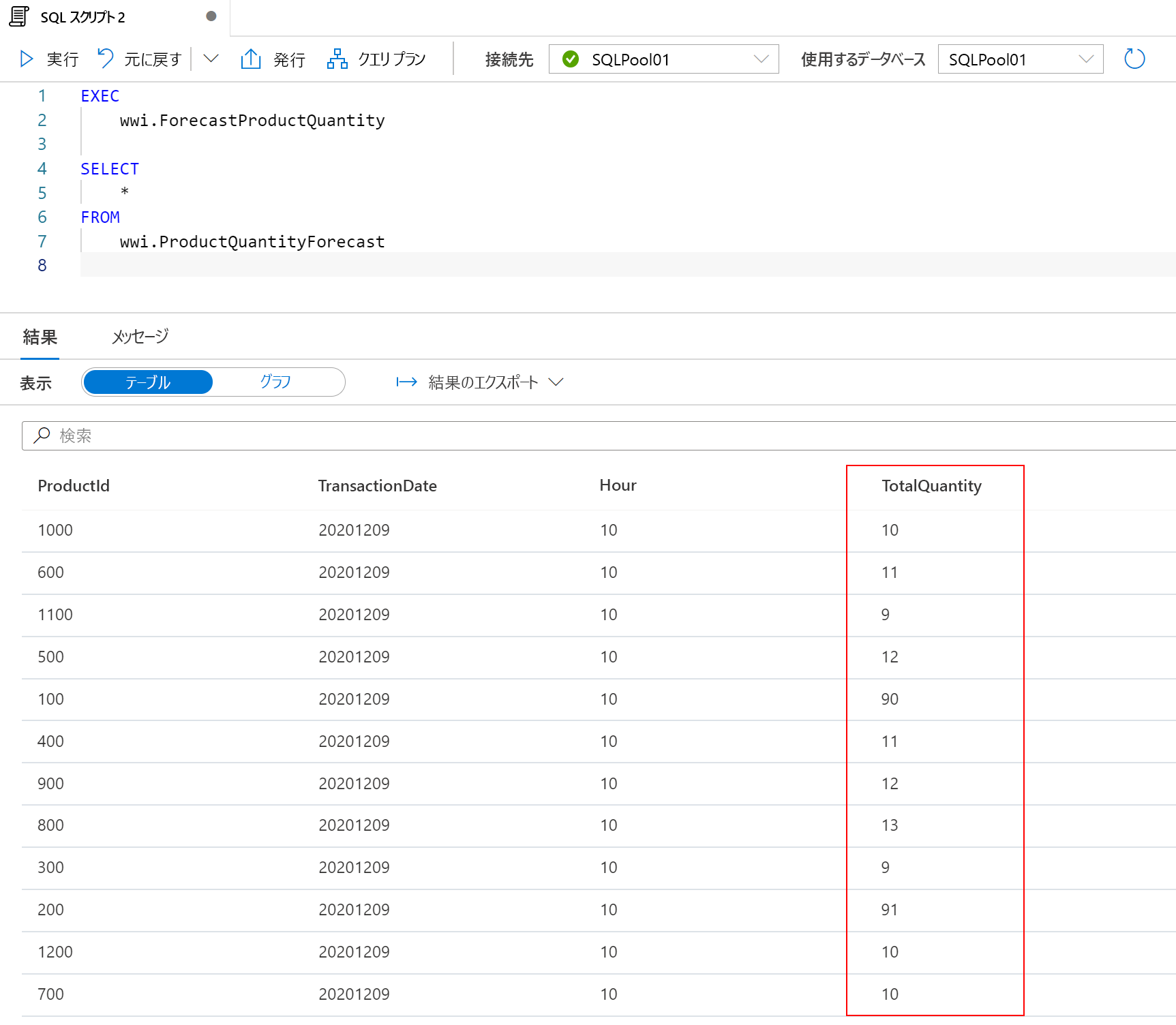
これで、TotalQuantity 列で予測を実行する準備が整いました。 新しい SQL スクリプトを開き、次のステートメントを実行します。
EXEC
wwi.ForecastProductQuantity
SELECT
*
FROM
wwi.ProductQuantityForecast
TotalQuantity 列の値が 0 から 0 以外の予測値に変更されたことに注意してください。
タスク 2 - Azure Cognitive Services のトレーニング済みモデルを使用して Spark テーブルのデータをエンリッチする
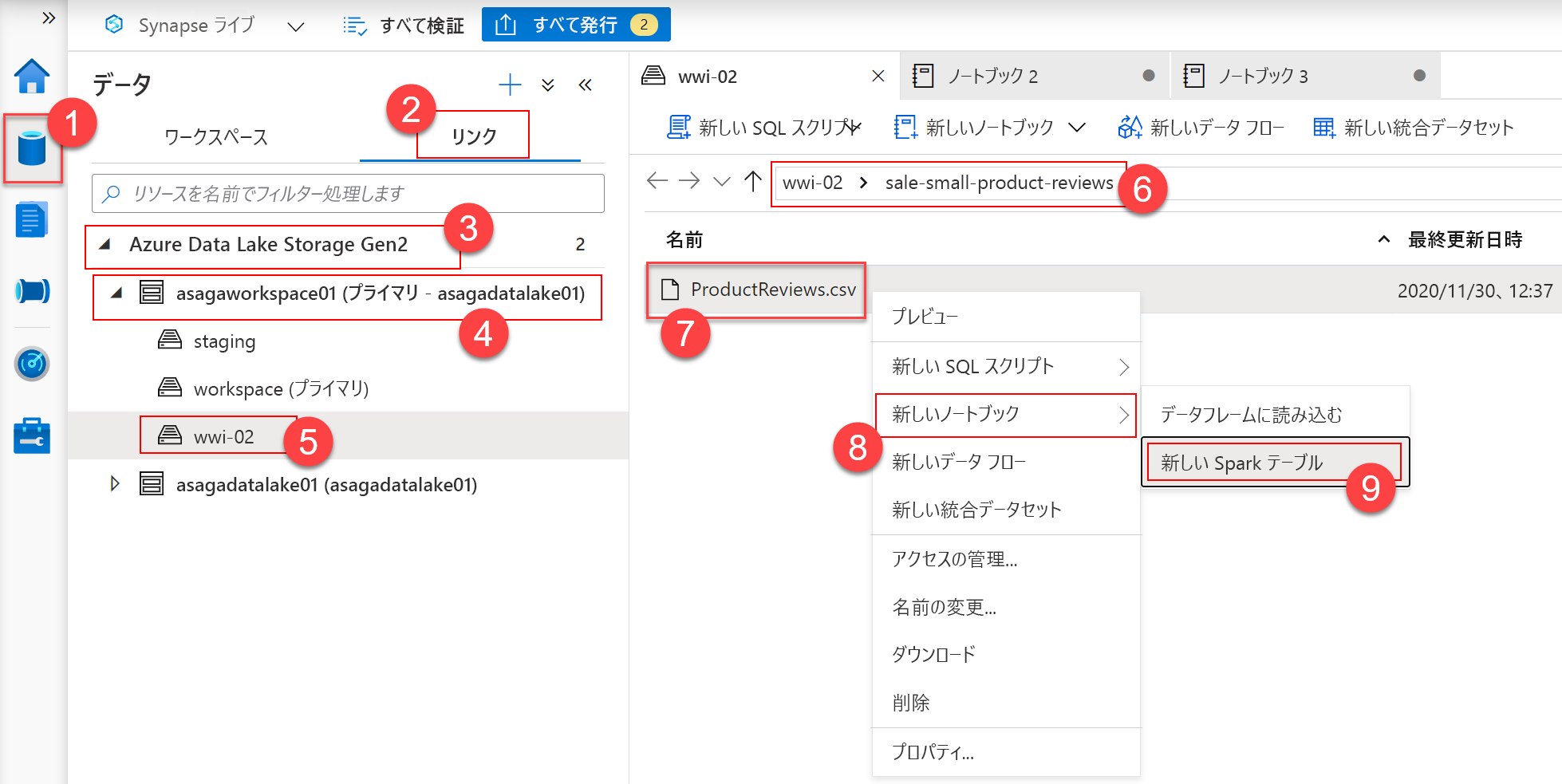
最初に、Cognitive Services モデルの入力として使用される Spark テーブルを作成する必要があります。 Synapse Studio で、[Data] ハブ (1)、[Linked] (2) セクションの順に選択します。 プライマリ [Azure Data Lake Storage Gen 2] (3) アカウントで、[wwi-02(5)] ファイル システムを選択し、wwi-02\sale-small-product-reviews(6) の下の ProductReviews.csv(7) ファイルを選択します。 ファイルを右クリックし、[New notebook -> New Spark table] (8-9) を選択します。
ノートブック セルの内容を次のコードに置き換えて、セルを実行します。
%%pyspark
df = spark.read.load('abfss://wwi-02@<data_lake_account_name>.dfs.core.windows.net/sale-small-product-reviews/ProductReviews.csv', format='csv'
,header=True
)
df.write.mode("overwrite").saveAsTable("default.ProductReview")
注意
<data_lake_account_name> を Synapse Analytics プライマリ データ レイク アカウントの実際の名前に置き換えます。
[Data] ハブにテーブルを表示するには、[Workspace] セクションの [default (Spark)] データベースを展開します。 テーブルが Tables フォルダーに表示されます。 テーブル名の右側にある 3 個のドットを選択すると、コンテキスト メニューに [Machine Learning] オプションが表示されます。[Machine Learning > Enrich with existing model] を選択します。
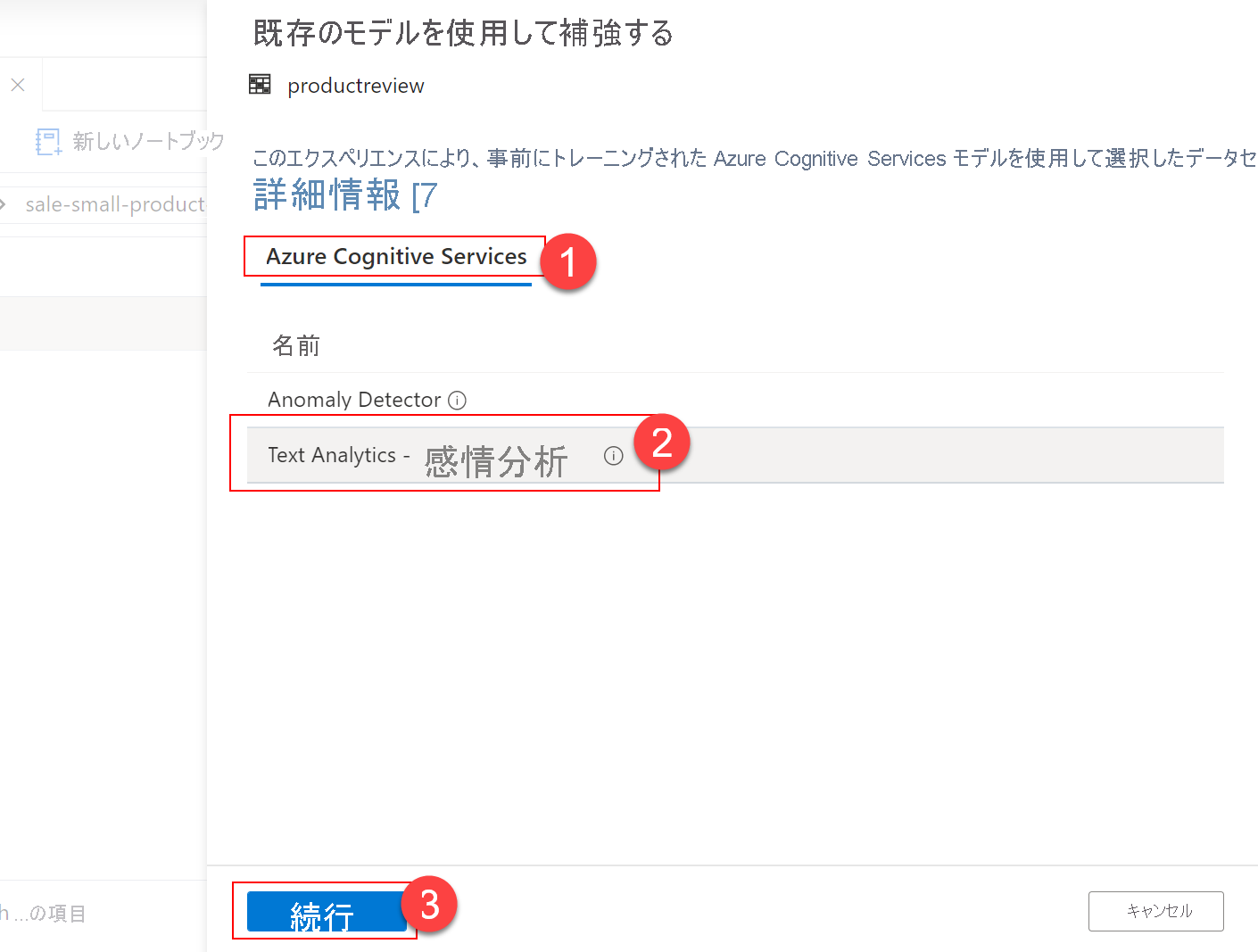
[Enrich with existing model] ダイアログで、[Azure Cognitive Services] (1) の下の [Text Analytics - Sentiment Analysis] (2) を選択し、[Continue] (3) を選択します。
次に、値を次のように指定します。
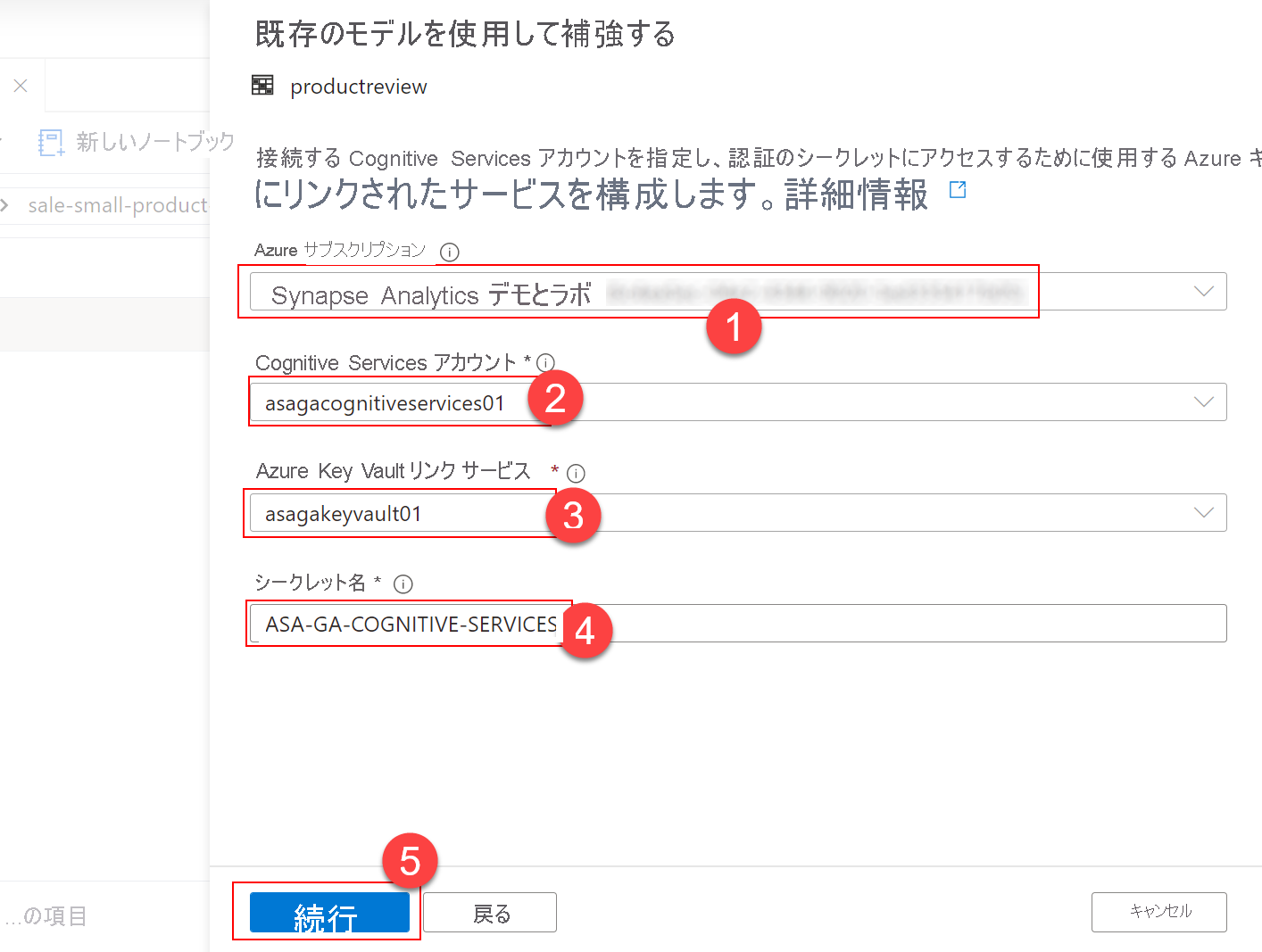
- Azure サブスクリプション (1): ご使用のリソース グループの Azure サブスクリプションを選択します。
- Cognitive Services アカウント (2): ご使用のリソース グループでプロビジョニングされた Cognitive Services アカウント。 名前は、
asagacognitiveservices<unique_suffix>にする必要があります。ここで、<unique_suffix>は、Synapse Analytics ワークスペースをデプロイしたときに指定した一意のサフィックスです。 - Azure Key Vault のリンクされたサービス (3): Synapse Analytics ワークスペースでプロビジョニングされた Azure Key Vault のリンクされたサービスを選択します。 名前は、
asagakeyvault<unique_suffix>にする必要があります。ここで、<unique_suffix>は、Synapse Analytics ワークスペースをデプロイしたときに指定した一意のサフィックスです。 - シークレット名 (4): 「
ASA-GA-COGNITIVE-SERVICES」 (指定された Cognitive Services アカウントのキーを含むシークレットの名前) と入力します。
[Continue] (5) を選択して、次に進みます。
次に、値を次のように指定します。
- 言語: [
English] を選択します。 - テキスト列: [
ReviewText (string)] を選択します
生成されたコードを表示するには、[Open notebook] を選択します。
注意
ノートブック セルを実行して ProductReview Spark テーブルを作成したときに、そのノートブックで Spark セッションを開始しました。 Synapse Analytics ワークスペースの既定の設定では、そのノートブックと並行して実行される新しいノートブックを開始することはできません。
Cognitive Services 統合コードに含まれる 2 つのセルの内容をそのノートブックにコピーし、既に開始している Spark セッションでそれらを実行する必要があります。 2 つのセルをコピーすると、次のような画面が表示されます。

Note
セルをコピーせずに、Synapse Studio によって生成されたノートブックを実行するには、[Monitor] ハブの [Apache Spark applications] セクションを使用できます。ここでは、実行中の Spark セッションを表示したり、キャンセルしたりすることができます。 この詳細については、「Synapse Studio を使用して Apache Spark アプリケーションを監視する」を参照してください。 このラボでは、実行中の Spark セッションをキャンセルし、後で新しいセッションを開始するために余分な時間がかからないように、セルをコピーする方法を使用しました。
ノートブックでセル 2 と 3 を実行して、データの感情分析結果を取得します。
