検索ソリューションの要素を特定する
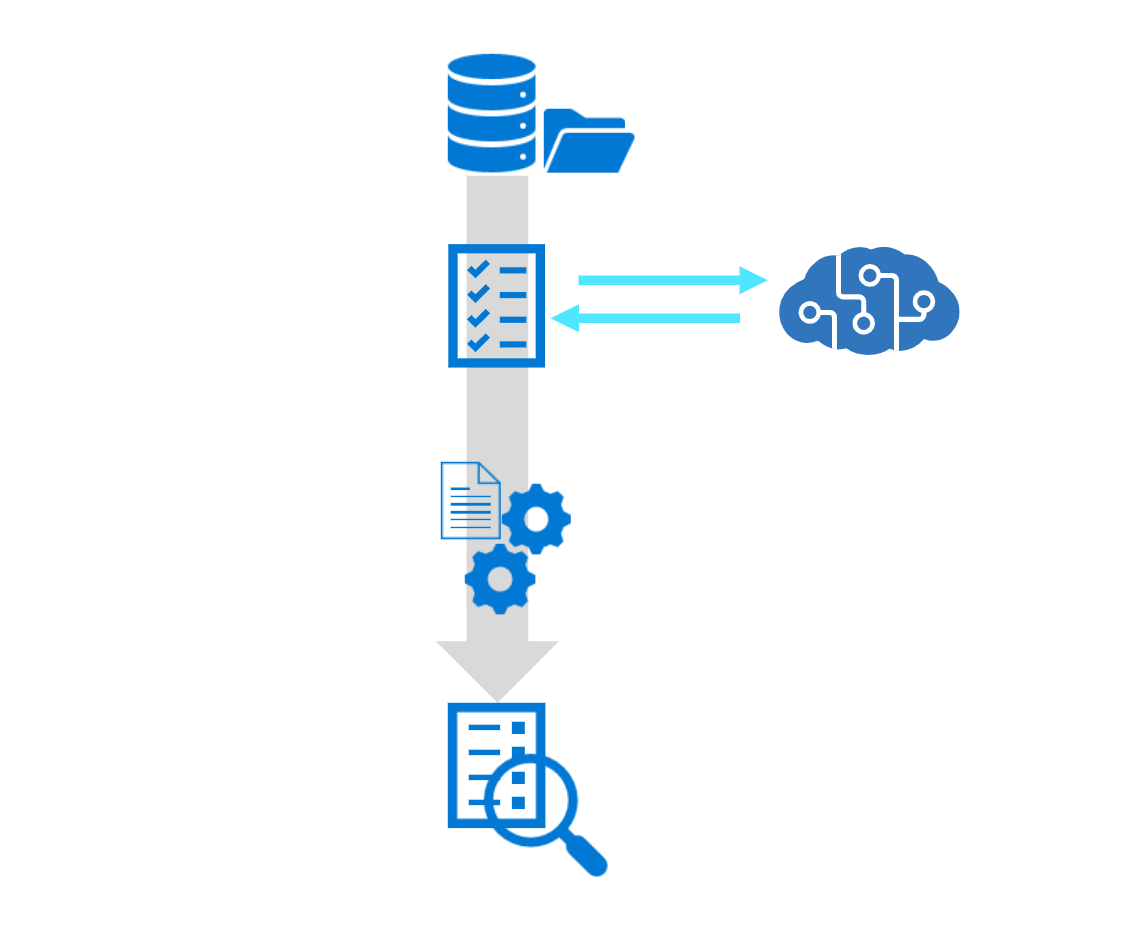
一般的な Azure AI 検索ソリューションは、検索するデータ成果物を含むデータ ソースから始まります。 これは、Azure Storage 内のフォルダーとファイルの階層、または Azure SQL Database や Azure Cosmos DB などのデータベース内のテキストである場合があります。 Azure AI 検索サポートされるデータ形式は JSON です。 データのソースにかかわらず、JSON ドキュメントとして提供できる場合は、検索エンジンでインデックスを作成できます。
データがサポートされているデータ ソースに存在する場合は、インデクサーを使用して、ソース データを JSON でネイティブ形式でシリアル化するなど、データ インジェストを自動化できます。 インデクサーは、データ ソースに接続し、データをシリアル化し、インデックス作成のために検索エンジンに渡します。 ほとんどのインデクサーは変更検出をサポートしているため、簡単にデータを更新できます。
データ インジェストの自動化に加え、インデクサーでは、AI エンリッチメントもサポートしています。 一連の AI スキルを適用するスキルセットをアタッチしてデータを強化し、より検索しやすくすることができます。 Azure AI サービス API に基づく組み込みスキルの包括的なセットは、たとえば、テキスト内のエンティティの識別、テキストの翻訳、センチメントの評価、画像にとって適切なキャプションの予測などによって、新しい分野を派生させることを支援します。 必要に応じて、エンリッチされたコンテンツは、AI エンリッチメント パイプラインからの出力を Azure Storage のテーブルと BLOB に格納して個別に分析またはダウンストリーム処理する、ナレッジ ストアに送ることもできます。
データをインデックスにプッシュするアプリケーション コードを記述する場合でも、データ インジェストを自動化して AI エンリッチメントを追加するインデクサーを使用する場合でも、ご自分のコンテンツを含むフィールドは、クライアント アプリケーションで検索可能なインデックスに保持されます。 フィールドは、クライアント アプリケーションで表示または使用できる結果のセットを生成するために、検索、フィルター処理、および並べ替えに使用されます。