インデックスについて理解する
Azure AI Search インデックスは、検索可能なドキュメントのコンテナーと考えることができます。 概念的には、インデックスはテーブルと考えることができ、テーブル内の各行はドキュメントを表します。 テーブルには列があります。列はドキュメント内のフィールドに相当するものと考えることができます。 ドキュメントのフィールドがそうであるように、列にはデータ型があります。
インデックス スキーマ
Azure AI Search では、インデックスは検索機能を有効にするために使用される JSON ドキュメントと他のコンテンツの永続的なコレクションです。 インデックス内のドキュメントはテーブルの行と考えることができ、各ドキュメントはインデックス内の検索可能なデータの 1 単位です。
インデックスでは、これらのドキュメントのデータの構造の定義が含まれ、そのスキーマと呼ばれます。 AI によって抽出されたフィールドの keyphrases と imageTags を含むインデックス スキーマの例を以下に示します。

インデックスの属性
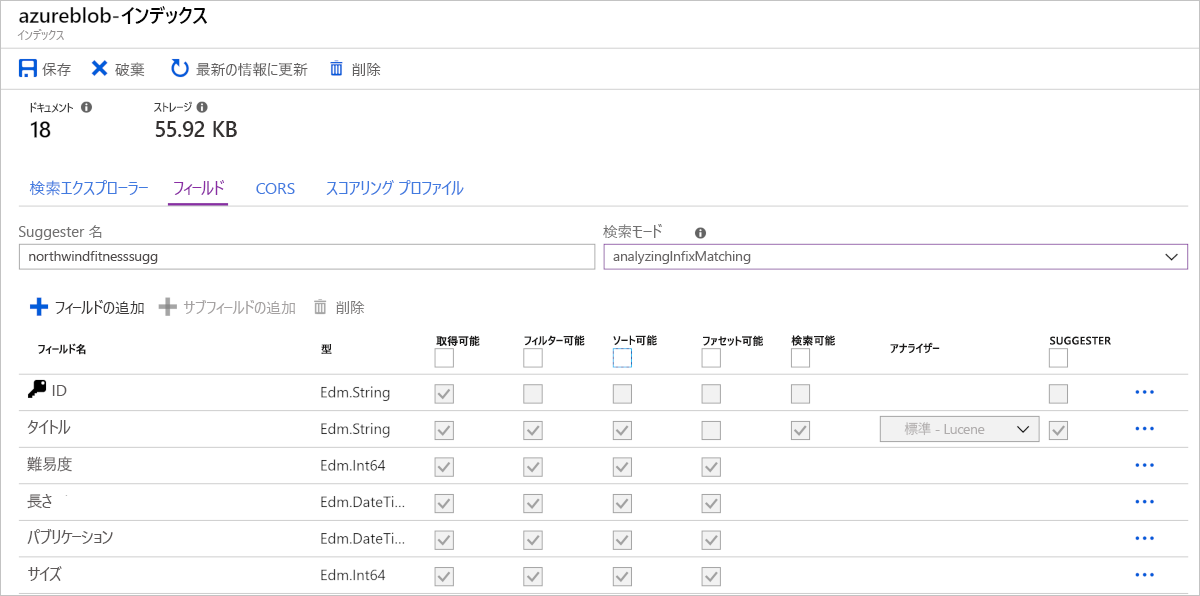
Azure AI Search により、ドキュメント内のフィールドを検索および表示する方法が認識されている必要があります。 属性または動作をこれらのフィールドに割り当てることで、それを指定します。 ドキュメント内のフィールドごとに、その名前、データ型、フィールドでサポートされる動作 (フィールドは検索可能か、フィールドを並べ替えることはできるか、など) がインデックスに格納されます。
最も効率的なインデックスでは、必要な動作のみが使われます。 設計時にフィールドに必要な動作を設定するのを忘れた場合、その機能を有効にするにはインデックスを再構築するしかありません。
次の画像は、Azure でインデックスを設計するときのフィールドを示したものです。