教師あり学習を定義する
モデルをトレーニングするプロセスは、教師ありまたは教師なしのいずれかです。 ここでの目標は、これらのアプローチを対比させたうえで、教師あり学習に焦点を当てて学習プロセスについてさらに深く掘り下げることです。 ただし、この説明の全体を通して、教師あり学習と教師なし学習の唯一の違いは、目的関数の動作のしくみにあることに留意してください。
教師なし学習とは
教師なし学習では、正解を知らない状態で問題を解決するためにモデルをトレーニングします。 教師なし学習は、通常、1 つの正解ではなく、より適切な解とより適切ではない解がある問題に対して使用されます。
機械学習モデルで雪崩救助犬の写実的な絵を描かせたいとします。 描くべき 1 つの "正しい" 絵があるわけではなく、 絵が犬のように見える限りは満足できます。 しかし、出来上がった絵が猫だった場合、それは適切ではない解ということになります。
トレーニングにはいくつかのコンポーネントが必要なことを思い出してください。
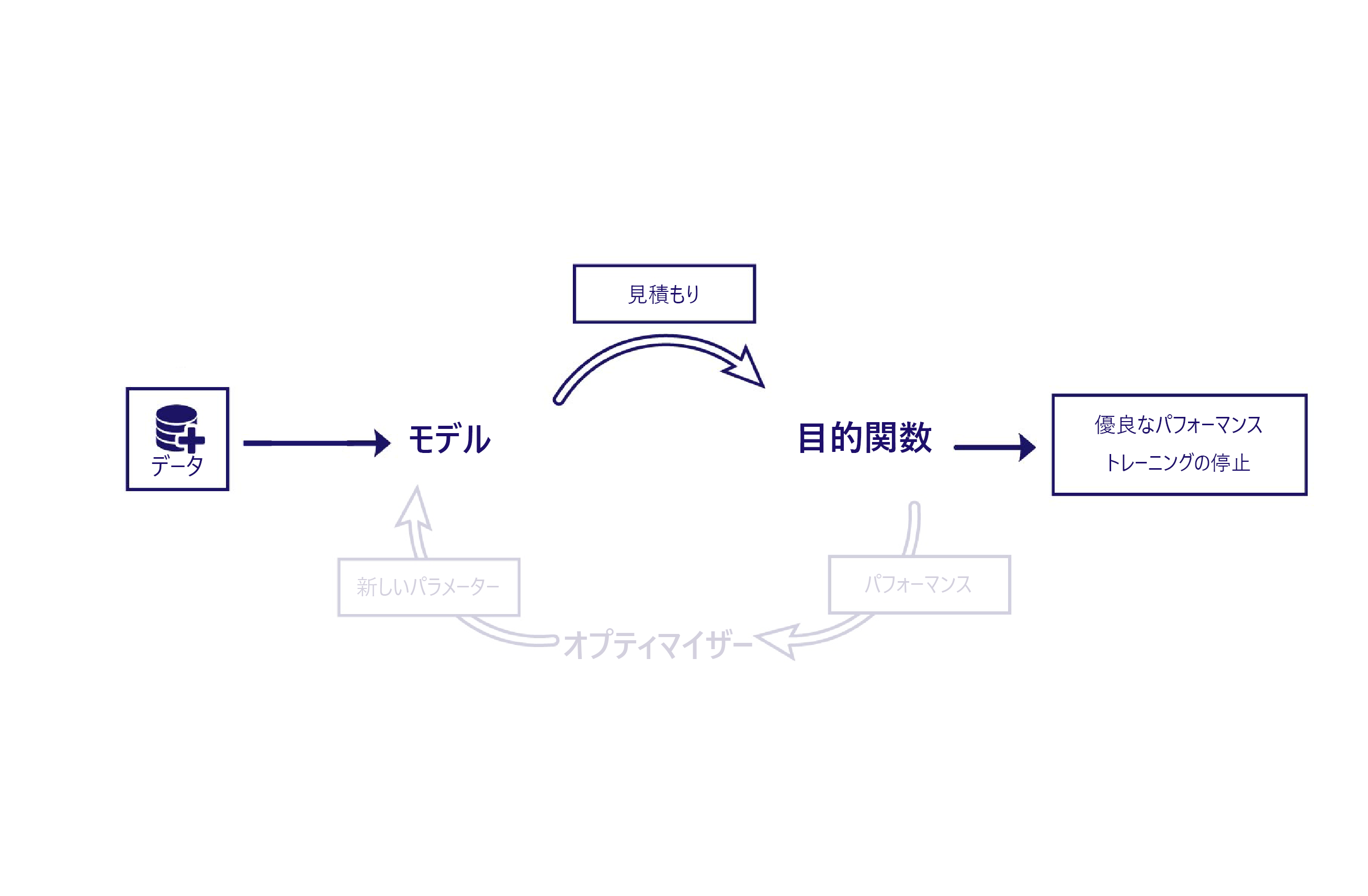
教師なし学習では、目的関数による判断は純粋にモデルの推定に基づきます。 つまり、多くの場合、比較的高度な目的関数が必要になります。 たとえば、モデルで描かれた絵が写実的に見えるかどうかを評価する "犬検出機能" を目的関数に含めることが必要になるかもしれません。 教師なし学習に必要なデータは、特徴量、つまり人間がモデルに与えるデータのみです。
教師あり学習とは
教師あり学習は、例による学習と考えてください。 教師あり学習の場合、モデルのパフォーマンスは、その推定を正解と比較することで評価されます。 シンプルな目的関数を使用できますが、次の両方が必要です。
- モデルに入力として与える特徴量
- ラベル。これは、モデルに生成させたい正解
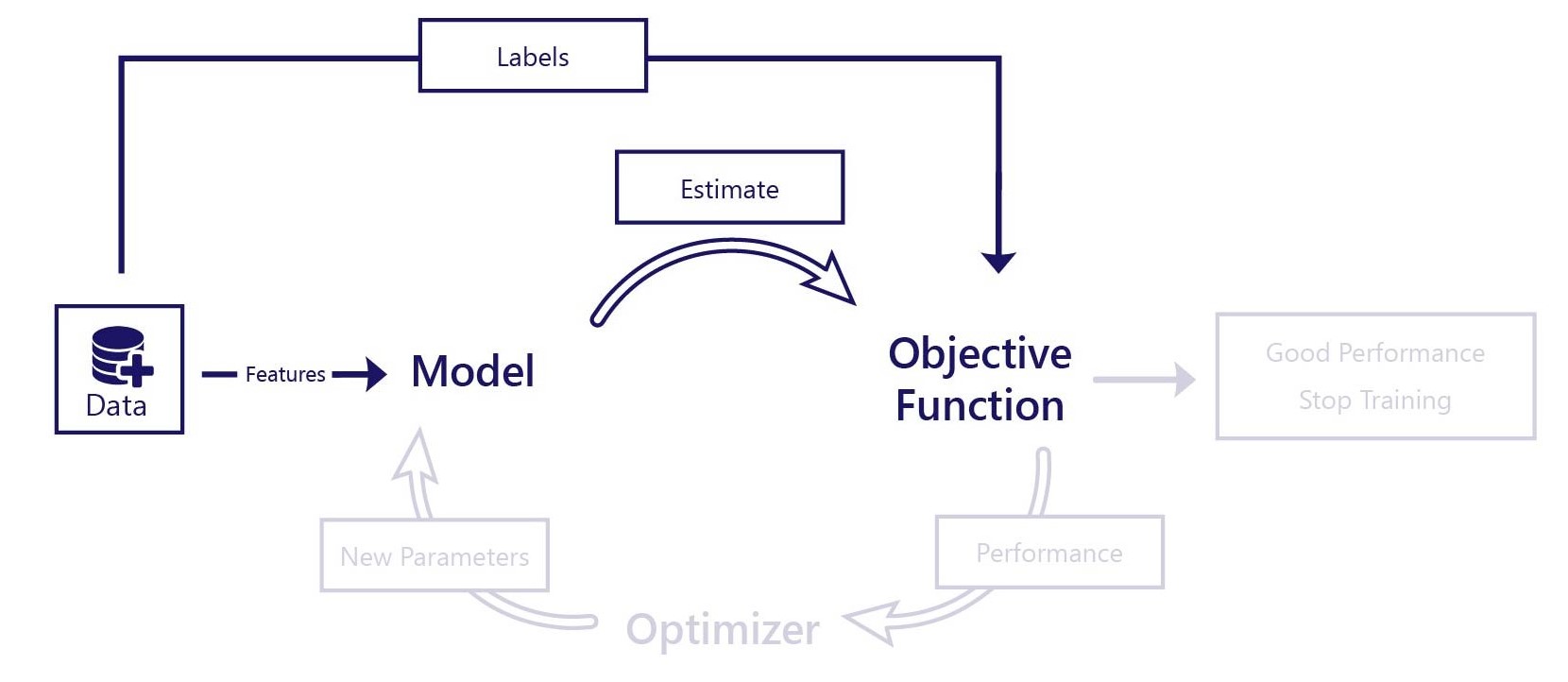
たとえば、特定の年の 1 月 31 日の気温を予測したいとします。 この予測には、次の 2 つのコンポーネントを含むデータが必要です。
- 特徴量: 日付
- ラベル: 毎日の気温 (過去の記録にあるものなど)
このシナリオでは、モデルに日付という特徴量を与えます。 モデルで気温が予測されます。この結果をデータセットの "正しい" 気温と比較します。 この後、目的関数で、モデルの動作がどの程度適切であったかを計算し、モデルに対して調整を行うことができます。
ラベルは学習のためだけのもの
モデルは、どのようにトレーニングしても、特徴量を処理するだけである点に注意することが重要です。 教師あり学習の間、ラベルへのアクセスに依存する唯一のコンポーネントは目的関数です。 トレーニング後は、モデルを使用するためにラベルは必要ありません。