one-hot ベクトル
ここまで、連続データのエンコード (浮動小数点数)、序数データのエンコード (通常は整数)、バイナリ カテゴリ データのエンコード (生存/死亡、男性/女性など) について説明してきました。
ここでは、データをエンコードする方法を学習し、3 つ以上のクラスを持つカテゴリ データ リソースについて調べます。 また、モデルの改善の決定がモデルのパフォーマンスに与える可能性のある悪影響についても調べます。
カテゴリ データは数値ではない
カテゴリ データは、他のデータ型と同じようには数値で機能しません。 "序数" または "連続" (数値) データでは、大きな値は量が増えたことを示します。 たとえば、タイタニック号では、£30 のチケット価格は £12 のチケット価格より高額です。
これに対し、カテゴリ データには論理的な順序はありません。 3 つ以上のクラスを持つカテゴリ的特徴を数値としてエンコードしようとすると、問題が発生します。
たとえば、乗船港には C (シェルブール)、Q (クイーンズタウン)、S (サウサンプトン) の 3 つの値があります。 これらの記号を数値に置き換えることはできません。 それを行うと、これらの港のいずれかが他の港 "より小さい" のに対して、別の港が他の港 "より大きい" ことになってしまいます。 この置換は意味がありません。
この問題の例として、大胆な発想で乗船港とチケット クラスの間の関係をモデル化し、乗船港を数値として扱ってみましょう。 まず、C < S < Q と設定します。
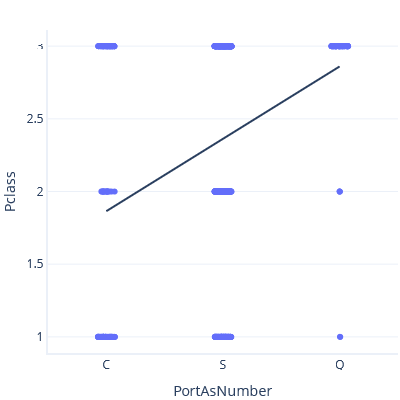
このプロットでは、この直線によって港 Q に対して約 3 のクラスが予測されます。
次に、S < C < Q と設定すると、異なる傾向線と予測が得られます。
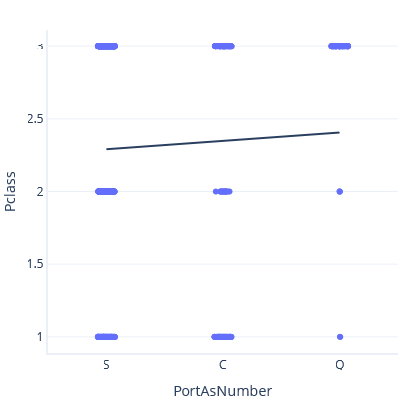
これらの傾向線はどれも正しくありません。 カテゴリを連続した特徴量として扱うことは意味がありません。 カテゴリをどのように操作すればよいでしょうか。
one-hot エンコード
one-hot エンコードは、この問題を回避する方法でカテゴリ データをエンコードできます。 使用可能な各カテゴリに独自の 1 列を割り当て、特定の行では、それが属するカテゴリにのみ 1 つの値 1 が含まれます。
たとえば、港の値を 3 つの列 (シェルブールに 1 つ、クイーンズタウンに 1 つ、サウサンプトンに 1 つ) でエンコードできます (ここでは正確な順序は関係ありません)。 シェルブールで乗船した人は、次のように、Port_Cherbourg 列が 1 になります。
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 1 | 0 | 0 |
クイーンズタウンで乗船した人は、2 番目の列が 1 になります。
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 1 | 0 |
サウサンプトンで乗船した人は、3 番目の列が 1 になります
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 0 | 1 |
one-hot エンコード、データ クリーニング、統計的検出力
one-hot エンコードを使う前に、それを使うと、モデルの現実世界のパフォーマンスに好影響または悪影響を与える可能性があることを理解しておく必要があります。
統計的検出力とは
統計的検出力とは、特徴量とラベルの間の実際の関係を確実に識別するモデルの機能を指します。 たとえば、強力なモデルは、チケット価格と生存率の間の関係を高い確実性で報告する可能性があります。 これに対して、統計的検出力の低いモデルは、低い確実性で関係を報告することがあり、この関係をまったく見つけられない可能性さえあります。
ここでは数学は避けますが、行った選択がモデルの能力に影響を与える可能性があることを覚えておいてください。
データを削除すると統計的検出力が低下する
データのクリーニングには、ある程度、不完全なデータ サンプルの削除が含まれることに、何回も触れてきました。 残念ながら、統計的検出力はデータのクリーニングによって低下する可能性があります。 たとえば、次のデータが与えられたとき、タイタニック号の航海での生存を予測してみましょう。
| チケット価格 | 生存 |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £10 | 1 |
| £25 | 1 |
£10 以上はするチケットを持った人はすべて生存したため、£15 のチケットを持った人は生存すると推測することができます。 しかし、データが少なければ、この推測はより困難になります。
| チケット価格 | 生存 |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £25 | 1 |
価値のない列によって統計的検出力が低下する
特に特徴量 (列) の数がサンプル (行) の数に近づき始めている場合、価値のない特徴量によって統計的検出力が損なわれる可能性もあります。
たとえば、次のデータで生存を予測できるようにしたいものとします。
| チケット価格 | 生存 |
|---|---|
| £4 | 0 |
| £4 | 0 |
| £25 | 1 |
| £25 | 1 |
£25 のチケットを持ったすべての人が生存したため、船室 A のチケットを持っている人は生存すると、自信を持って予測できます。
しかし、今度はもう 1 つの特徴量 (船室) があります。
| チケット価格 | Cabin | 生存 |
|---|---|---|
| £4 | A | 0 |
| £4 | A | 0 |
| £25 | B | 1 |
| £25 | B | 1 |
船室はチケット価格に対応しているだけであるため、役立つ情報は提供されません。 £25 の船室 A のチケットを持った人が生存するかどうかは明確ではありません。 船室 A の他の人のように亡くなるのでしょうか、それとも £25 のチケットを持った人のように生存するのでしょうか?
one-hot エンコードによって統計的検出力が低下する場合がある
one-hot エンコードは、複数の列 (可能性のあるカテゴリ値ごとに 1 つ) を必要とするため、連続データまたは序数データより大きく統計的検出力を低下させます。 たとえば、乗船港を one-hot エンコードする場合、3 つのモデル入力 (C、S、Q) を追加します。
カテゴリ変数は、カテゴリの数がサンプルの数 (データセットの行数) より大幅に少ない場合に役に立ちます。 カテゴリ変数は、モデルに対する他の入力ではまだ使用できない情報を提供する場合にも役立ちます。
たとえば、生存の確率は、異なる港で乗船した人によって異なることを見てきました。 この違いはおそらく、クイーンズタウン港で乗船したほとんどの人が 3 番目のクラスのチケットを持っていたという事実を反映しています。 したがって、乗船はモデルに関連情報を追加することなく、統計的検出力を少し低下させる可能性があります。
これに対して、船室は生存に大きな影響を与える可能性があります。 これは、船の下階の船室は船の上部デッキに近い船室が水で満たされるより前に浸水するためです。 とは言え、タイタニック データセットには 147 の異なる船室が含まれています。 これにより、それらを含めた場合は、モデルの統計的検出力が低下します。 モデルに船室データを含めた場合と含めない場合の実験を行い、船室データが役に立つかどうかを確認することが必要かもしれません。
次の演習では、タイタニック号の航海での生存を予測するモデルを最終的に構築し、その過程で one-hot エンコードを実践します。