データ読み込み戦略を調べる
Microsoft Fabric では、ウェアハウスにデータを読み込むさまざまな方法を選択できます。 高品質な変換または処理されたデータが 1 つのリポジトリに統合されることを保証するこのステップは、基盤となるものです。
また、データ読み込みの効率は、分析の適時性と正確性に直接影響するため、リアルタイムの意思決定プロセスに不可欠なものです。 データ ウェアハウス プロジェクトを成功させるには、堅牢なデータ読み込み戦略の設計と実装に時間とリソースを費やすことが不可欠です。
データ インジェストとデータ読み込みの操作を理解する
どちらのプロセスもデータ ウェアハウス シナリオでの ETL (抽出、変換、読み込み) パイプラインの一部ですが、通常は異なる目的に使われます。 データ インジェストと抽出では、さまざまなソースから中央リポジトリに生データが移動されます。 それに対し、データの読み込みでは、変換または処理されたデータが取得されて、分析とレポートのために最終的なストレージ先に読み込まれます。
データ ウェアハウスやレイクハウスなどのファブリック データ項目はすべて、データを Delta Parquet 形式で OneLake に自動的に格納します。
データをステージングする
テーブル、ストアド プロシージャ、関数など、読み込み操作に関係する補助オブジェクトを作成して使用することが必要な場合があります。 これらの補助オブジェクトは、一般に、ステージングと呼ばれます。 ステージング オブジェクトは、ストレージと変換のための一時的な領域として機能します。 それらは、データ ウェアハウスとリソースを共有したり、独自のストレージ領域に存在したりできます。
ステージングは抽象化レイヤーとして機能し、データ ウェアハウス内の最終的なテーブルへの読み込み操作を簡単で容易にします。
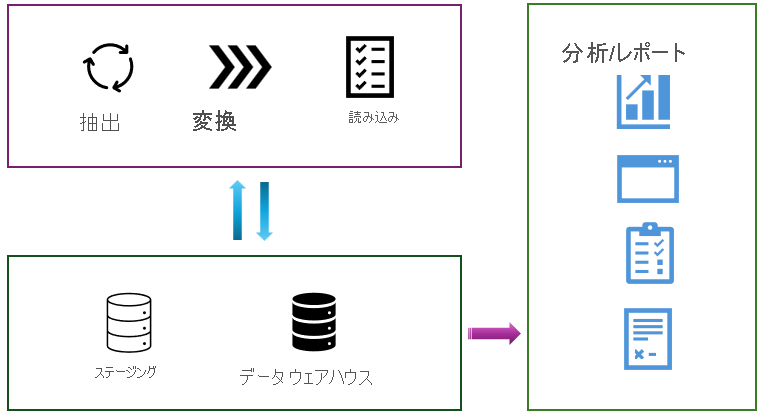
また、ステージング領域は、負荷のかかる操作がデータ ウェアハウスのパフォーマンスに及ぼす影響を最小限に抑えるのに役立つバッファーも提供します。 これは、データ読み込みプロセスの間もデータ ウェアハウスの動作と応答が維持される必要のある環境において重要なことです。
データ読み込みの種類を確認する
データの読み込みには 2 つの種類があり、データ ウェアハウスを読み込むときに考慮する必要があります。
| 読み込みの種類 | 説明 | 操作 | Duration | 複雑性 | 最適な用途 |
|---|---|---|---|---|---|
| 完全な (初期) 読み込み | データ ウェアハウスを初めて設定するプロセス。 | すべてのテーブルが切り詰められて読み込み直され、古いデータは失われます | 処理されるデータの量のため、完了に時間がかかる場合があります | 履歴が保持されていないため、簡単に実装できます | この方法は、通常、新しいデータ ウェアハウスをセットアップするとき、またはデータの完全な更新が必要なときに使われます。 |
| 増分読み込み | 前回の更新以降の変更でデータ ウェアハウスを更新するプロセス | 履歴が保持されており、新しい情報でテーブルが更新されます | 初期読み込みより、時間がかかりません | 実装は初期読み込みより複雑です | この方法は、データ ウェアハウスの定期的な更新 (日ごとや時間ごとの更新など) に一般的に使われます。 最後の読み込み以降にソース データで行われた変更を追跡するためのメカニズムが必要です。 |
データ ウェアハウスの ETL (抽出、変換、読み込み) プロセスでは、完全読み込みと増分読み込みの両方が常に必要であるとは限りません。 場合によっては、両方の方法の組み合わせが使われることがあります。 完全読み込みと増分読み込みのどちらを選ぶかは、データの量、データの特性、データ ウェアハウスの要件など、多くの要因に依存します。
増分読み込みの実行方法について詳しくは、増分読み込みに関する記事をご覧ください。
ディメンション テーブルを読み込む
ディメンション テーブルは、データ ウェアハウスの "だれ、何、どこ、いつ、なぜ" と考えることができます。 これは、ファクト テーブルで見つかる生の数値にコンテキストを与える説明的な背景のようなものです。
たとえば、オンライン ストアを運営している場合、ファクト テーブルには生の売上データ (各製品の販売単位数) が含まれている可能性があります。 しかし、ディメンション テーブルがないと、それらの製品を誰が買ったのか、いつ買ったのか、購入者がどこにいるのかわかりません。
緩やかに変化するディメンション (SCD)
緩やかに変化するディメンションは時間と共に変化しますが、その変化は遅く、予測できません。 たとえば、小売ビジネスの顧客の住所などです。 顧客が引っ越すと、住所が変わります。 古い住所を新しい住所で上書きすると、履歴は失われます。 しかし、過去の売上データを分析したい場合は、各売上の時点で顧客が住んでいた場所を知ることが必要になる場合があります。 そのようなときこそ SCD の出番です。
データ ウェアハウスの緩やかに変化するディメンションにはいくつかの種類があり、最もよく使われるのはタイプ 1 とタイプ 2 です。
- タイプ 0 SCD: ディメンション属性は変更されません。
- タイプ 1 SCD: 既存のデータを上書きし、履歴を保持しません。
- タイプ 2 SCD: 変更があると新しいレコードを追加し、特定の自然キーについての完全な履歴を保持します。
- タイプ 3 SCD: 履歴は新しい列として追加されます。
- タイプ 4 SCD: 新しいディメンションが追加されます。
- タイプ 5 SCD: 大きなディメンションの特定の属性が時間と共に変化するものの、ディメンションのサイズが大きいためタイプ 2 を使用できない場合。
- タイプ 6 SCD: タイプ 2 とタイプ 3 の組み合わせ。
タイプ 2 SCD では、同じ要素の新しいバージョンがデータ ウェアハウスに取り込まれると、古いバージョンは期限切れと見なされて、新しいバージョンがアクティブになります。

次の例では、T-SQL を使って、Dim_Products テーブルの変更をタイプ 2 SCD で処理する方法を示します。
IF EXISTS (SELECT 1 FROM Dim_Products WHERE SourceKey = @ProductID AND IsActive = 'True')
BEGIN
-- Existing product record
UPDATE Dim_Products
SET ValidTo = GETDATE(), IsActive = 'False'
WHERE SourceKey = @ProductID AND IsActive = 'True';
END
ELSE
BEGIN
-- New product record
INSERT INTO Dim_Products (SourceKey, ProductName, StartDate, EndDate, IsActive)
VALUES (@ProductID, @ProductName, GETDATE(), '9999-12-31', 'True');
END
ソース システムでの変更検出メカニズムは、レコードがいつ挿入、更新、または削除されたかを特定するために重要です。 SQL Server などのソース システムでのデータ追跡を管理するには、変更データ キャプチャ (CDC)、変更追跡、トリガーの機能をすべて利用できます。
ファクト テーブルを読み込む
例として、データ ウェアハウスに Fact_Sales テーブルを読み込む場合を考えてみましょう。 このテーブルの FactKey、DateKey、ProductKey、OrderID、Quantity、Price、LoadTime などの列には、売上トランザクション データが含まれています。
OLTP システムに、OrderID、OrderDate、ProductID、Quantity、Price の各列を含むソース テーブル Order_Detail があるとします。
次の T-SQL スクリプトの例は、Fact_Sales テーブルを読み込みます。
-- Lookup keys in dimension tables
INSERT INTO Fact_Sales (DateKey, ProductKey, OrderID, Quantity, Price, LoadTime)
SELECT d.DateKey, p.ProductKey, o.OrderID, o.Quantity, o.Price, GETDATE()
FROM Order_Detail o
JOIN Dim_Date d ON o.OrderDate = d.Date
JOIN Dim_Product p ON o.ProductID = p.ProductID;
この例では、JOIN 操作を使って、Dim_Date テーブルと Dim_Product テーブルでそれぞれ値 DateKey と ProductKey を検索し、Fact_Sales テーブルにデータを挿入します。 ただし、読み込みプロセスの複雑さは、データの量、変換要件、エラー処理、スキーマの違い、パフォーマンスなど、いくつかの要因に依存することに注意することが重要です。